
# Prometheus 监控实战(三)
# 一. Promtheus 节点监控
# 1.1 配置 Prometheus
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
# rules 配置文件路径 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] |
# 1.2 创建 rules 目录并重载 Prometheus
[root@prom-node01 ~]# mkdir /etc/prometheus/rules | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 1.3 Promtheus 配置告警规则
# 1.3.1 配置 CPU 告警规则
#1. 配置 CPU 告警规则 | |
[root@prom-node01 ~]# cat /etc/prometheus/rules/node_rules.yml | |
groups: | |
- name: CPU告警规则 | |
rules: | |
- alert: 节点处于Down状态 | |
expr: up == 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "节点处于Down状态,实例:" | |
description: " 节点已关闭" | |
- alert: 节点CPU使率超过80% | |
expr: ( 1 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance,job) ) * 100 > 80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机CPU利率过高,实例:, 任务:" | |
description: "该实例的CPU利用率低于20%,当前利用率:%。可能存在CPU资源浪费情况。" | |
- alert: CPU饱和度过⾼ | |
expr: sum(node_load1) by (instance,job) / (count(node_cpu_seconds_total{mode="idle"}) by (instance,job) * 2) * 100 > 80 | |
for: 2m | |
labels: | |
severity: critical | |
annotations: | |
summary: "CPU饱和度过高,实例:, 任务:" | |
description: "该实例的1分钟平均CPU负载超过了核心数的两倍,已经持续2分钟,当前CPU饱和度:%。需要立即检查系统负载情况。" | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/node_rules.yml | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 1.3.2 配置内存告警规则
#1. 配置内存告警规则 | |
[root@prom-node01 ~]# cat /etc/prometheus/rules/node_rules.yml | |
groups: | |
- name: CPU告警规则 | |
rules: | |
- alert: 节点处于Down状态 | |
expr: up == 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "节点处于Down状态,实例:" | |
description: " 节点已关闭" | |
- alert: 节点CPU使率超过80% | |
expr: ( 1 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance,job) ) * 100 > 80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机CPU利率过高,实例:, 任务:" | |
description: "该实例的CPU利用率低于20%,当前利用率:%。可能存在CPU资源浪费情况。" | |
- alert: CPU饱和度过⾼ | |
expr: sum(node_load1) by (instance,job) / (count(node_cpu_seconds_total{mode="idle"}) by (instance,job) * 2) * 100 > 80 | |
for: 2m | |
labels: | |
severity: critical | |
annotations: | |
summary: "CPU饱和度过高,实例:, 任务:" | |
description: "该实例的1分钟平均CPU负载超过了核心数的两倍,已经持续2分钟,当前CPU饱和度:%。需要立即检查系统负载情况。" | |
- name: 内存告警规则 | |
rules: | |
- alert: 主机内存不⾜ | |
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80 | |
for: 2m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机内存使用率较高, 实例:, 任务:" | |
description: "该实例的内存使用率持续2分钟高于80%,当前利用率:%" | |
- alert: 内存饱和度⾼ | |
expr: ( 1 - node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes) * 100 > 10 | |
for: 2m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机内存内存饱和度高, 实例:, 任务:" | |
description: "SWAP内存使用率已连续2分钟超过10%,表明内存饱和度过⾼,当前SWAP使用率为:%。" | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/node_rules.yml | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 1.3.3 配置磁盘告警规则
[root@prom-node01 ~]# cat /etc/prometheus/rules/node_rules.yml | |
groups: | |
- name: CPU告警规则 | |
rules: | |
- alert: 节点处于Down状态 | |
expr: up == 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "节点处于Down状态,实例:" | |
description: " 节点已关闭" | |
- alert: 节点CPU使率超过80% | |
expr: ( 1 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance,job) ) * 100 > 80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机CPU利率过高,实例:, 任务:" | |
description: "该实例的CPU利用率低于20%,当前利用率:%。可能存在CPU资源浪费情况。" | |
- alert: CPU饱和度过⾼ | |
expr: sum(node_load1) by (instance,job) / (count(node_cpu_seconds_total{mode="idle"}) by (instance,job) * 2) * 100 > 80 | |
for: 2m | |
labels: | |
severity: critical | |
annotations: | |
summary: "CPU饱和度过高,实例:, 任务:" | |
description: "该实例的1分钟平均CPU负载超过了核心数的两倍,已经持续2分钟,当前CPU饱和度:%。需要立即检查系统负载情况。" | |
- alert: 主机内存不⾜ | |
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80 | |
for: 2m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机内存使用率较高, 实例:, 任务:" | |
description: "该实例的内存使用率持续2分钟高于80%,当前利用率:%" | |
- alert: 内存饱和度⾼ | |
expr: ( 1 - node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes) * 100 > 10 | |
for: 2m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机内存内存饱和度高, 实例:, 任务:" | |
description: "SWAP内存使用率已连续2分钟超过10%,表明内存饱和度过⾼,当前SWAP使用率为:%。" | |
- name: 磁盘告警规则 | |
rules: | |
- alert: 磁盘空间告急 | |
expr: ( node_filesystem_size_bytes{device!="tmpfs"} - node_filesystem_avail_bytes{device!="tmpfs"} ) / node_filesystem_size_bytes{device!="tmpfs"} * 100 > 70 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘 分区空间不足" | |
description: "实例 磁盘 分区空间使用率已超过 70%,当前使用率为 %,请及时处理。" | |
- alert: 磁盘Inode空间告急 | |
expr: (node_filesystem_files{device!="tmpfs"} - node_filesystem_files_free{device!="tmpfs"} ) / node_filesystem_files{device!="tmpfs"} * 100 > 70 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘 分区Inode空间不足" | |
description: "实例 磁盘 分区的Inode空间使用率已超过 70%,,当前使用率为 %,请及时处理。" | |
- alert: 磁盘IOPS写入较高 | |
#expr: sum(rate(node_disk_writes_completed_total[1m])) by (instance,job) / 120 * 100 >60 | |
#round 函数可以对值进行四舍五入,磁盘最大 IOPS 为 120 次 /s | |
expr: round(max(irate(node_disk_writes_completed_total[1m])) by (instance,job) / 120 * 100) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 IOPS每秒写入次数超过120次/s" | |
description: | |
当前磁盘IOPS写入饱和度是 <!--swig47-->% | |
当前磁盘IOPS每秒写入最大 <!--swig48--> 次/s | |
- alert: 磁盘IOPS读取较高 | |
expr: round(max(irate(node_disk_reads_completed_total[1m])) by (instance,job) / 120 * 100) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 IOPS每秒读取次数超过120次/s" | |
description: | |
当前磁盘IOPS读取饱和度是 <!--swig50-->% | |
当前磁盘IOPS每秒读取最⼤ <!--swig51--> 次/s | |
- alert: 磁盘IO写入吞吐较高 | |
expr: round(max(rate(node_disk_written_bytes_total[1m])) by (instance,job) / 1024 /1024 / 30 * 100) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘IO写入每秒超过最高30MB/s" | |
description: | |
当前磁盘IO写入吞吐量的饱和度是 <!--swig53-->%。 | |
当前磁盘IO写入吞吐量每秒最大是 <!--swig54-->MB/s | |
- alert: 磁盘IO读取吞吐较高 | |
expr: round(max(rate(node_disk_read_bytes_total[1m])) by (instance,job) / 1024 /1024 /30 * 100 ) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘IO读取每秒超过最大30MB/s" | |
description: | |
当前磁盘IO读取吞吐量的饱和度是 <!--swig56-->%。 | |
当前磁盘IO读取吞吐量每秒最大是 <!--swig57-->MB/s | |
.instance $labels.job | query | first | value | printf "%.2f" }}MB/s | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/node_rules.yml | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload | |
#根据过去 24 小时磁盘使用情况,计算未来 30 天磁盘使用空间 | |
predict_linear(node_filesystem_avail_bytes{device!~"tmpfs|rootfs"}[24h],60*60*24*30) /1024/1024/1024 |
# 1.3.4 配置⽹络告警规则
[root@prom-node01 ~]# cat /etc/prometheus/rules/node_rules.yml | |
groups: | |
- name: 节点告警规则 | |
rules: | |
- alert: 节点处于Down状态 | |
expr: up == 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "节点处于Down状态,实例:" | |
description: " 节点已关闭" | |
- alert: 节点CPU使率超过80% | |
expr: ( 1 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance,job) ) * 100 > 80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机CPU利率过高,实例:, 任务:" | |
description: "该实例的CPU利用率低于20%,当前利用率:%。可能存在CPU资源浪费情况。" | |
- alert: CPU饱和度过高 | |
expr: sum(node_load1) by (instance,job) / (count(node_cpu_seconds_total{mode="idle"}) by (instance,job) * 2) * 100 > 80 | |
for: 2m | |
labels: | |
severity: critical | |
annotations: | |
summary: "CPU饱和度过高,实例:, 任务:" | |
description: "该实例的1分钟平均CPU负载超过了核心数的两倍,已经持续2分钟,当前CPU饱和度:%。需要立即检查系统负载情况。" | |
- alert: 主机内存不足 | |
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80 | |
for: 2m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机内存使用率较高, 实例:, 任务:" | |
description: "该实例的内存使用率持续2分钟高于80%,当前利用率:%" | |
- alert: 内存饱和度高 | |
expr: ( 1 - node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes) * 100 > 10 | |
for: 2m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机内存内存饱和度高, 实例:, 任务:" | |
description: "SWAP内存使用率已连续2分钟超过10%,表明内存饱和度过高,当前SWAP使用率为:%。" | |
- alert: 磁盘空间告急 | |
expr: ( node_filesystem_size_bytes{device!="tmpfs"} - node_filesystem_avail_bytes{device!="tmpfs"} ) / node_filesystem_size_bytes{device!="tmpfs"} * 100 > 70 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘 分区空间不足" | |
description: "实例 磁盘 分区空间使用率已超过 70%,当前使用率为 %,请及时处理。" | |
- alert: 磁盘Inode空间告急 | |
expr: (node_filesystem_files{device!="tmpfs"} - node_filesystem_files_free{device!="tmpfs"} ) / node_filesystem_files{device!="tmpfs"} * 100 > 70 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘 分区Inode空间不足" | |
description: "实例 磁盘 分区的Inode空间使用率已超过 70%,,当前使用率为 %,请及时处理。" | |
- alert: 磁盘IOPS写入较高 | |
#expr: sum(rate(node_disk_writes_completed_total[1m])) by (instance,job) / 120 * 100 >60 | |
#round 函数可以对值进行四舍五入,磁盘最大 IOPS 为 120 次 /s | |
expr: round(max(irate(node_disk_writes_completed_total[1m])) by (instance,job) / 120 * 100) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 IOPS每秒写入次数超过120次/s" | |
description: | |
当前磁盘IOPS写入饱和度是 <!--swig83-->% | |
当前磁盘IOPS每秒写入最大 <!--swig84--> 次/s | |
- alert: 磁盘IOPS读取较高 | |
expr: round(max(irate(node_disk_reads_completed_total[1m])) by (instance,job) / 120 * 100) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 IOPS每秒读取次数超过120次/s" | |
description: | |
当前磁盘IOPS读取饱和度是 <!--swig86-->% | |
当前磁盘IOPS每秒读取最⼤ <!--swig87--> 次/s | |
- alert: 磁盘IO写入吞吐较高 | |
expr: round(max(rate(node_disk_written_bytes_total[1m])) by (instance,job) / 1024 /1024 / 30 * 100) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘IO写入每秒超过最高30MB/s" | |
description: | |
当前磁盘IO写入吞吐量的饱和度是 <!--swig89-->%。 | |
当前磁盘IO写入吞吐量每秒最大是 <!--swig90-->MB/s | |
- alert: 磁盘IO读取吞吐较高 | |
expr: round(max(rate(node_disk_read_bytes_total[1m])) by (instance,job) / 1024 /1024 /30 * 100 ) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘IO读取每秒超过最大30MB/s" | |
description: | |
当前磁盘IO读取吞吐量的饱和度是 <!--swig92-->%。 | |
当前磁盘IO读取吞吐量每秒最大是 <!--swig93-->MB/s | |
- alert: 网络下载带宽异常 | |
expr: max(irate(node_network_receive_bytes_total[1m]) * 8 / 1024 / 1024) by (instance,job,device) / 50 * 100 >= 80 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 的 接口下载流量已经超过公司实际50Mbps" | |
description: | |
当前下载带宽已经达到 <!--swig96--> Mbps/s | |
当前下载带宽使用率在 <!--swig97-->% | |
- alert: 网络上传带宽异常 | |
expr: max(irate(node_network_transmit_bytes_total[1m]) * 8 / 1024 / 1024) by (instance,job,device) / 50 * 100 >= 80 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 的 接口上传流量已经超过公司实际50Mbps" | |
description: | |
当前上传带宽已经达到 <!--swig100--> Mbps/s | |
当前上传带宽使用率在 <!--swig101-->% | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/node_rules.yml | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
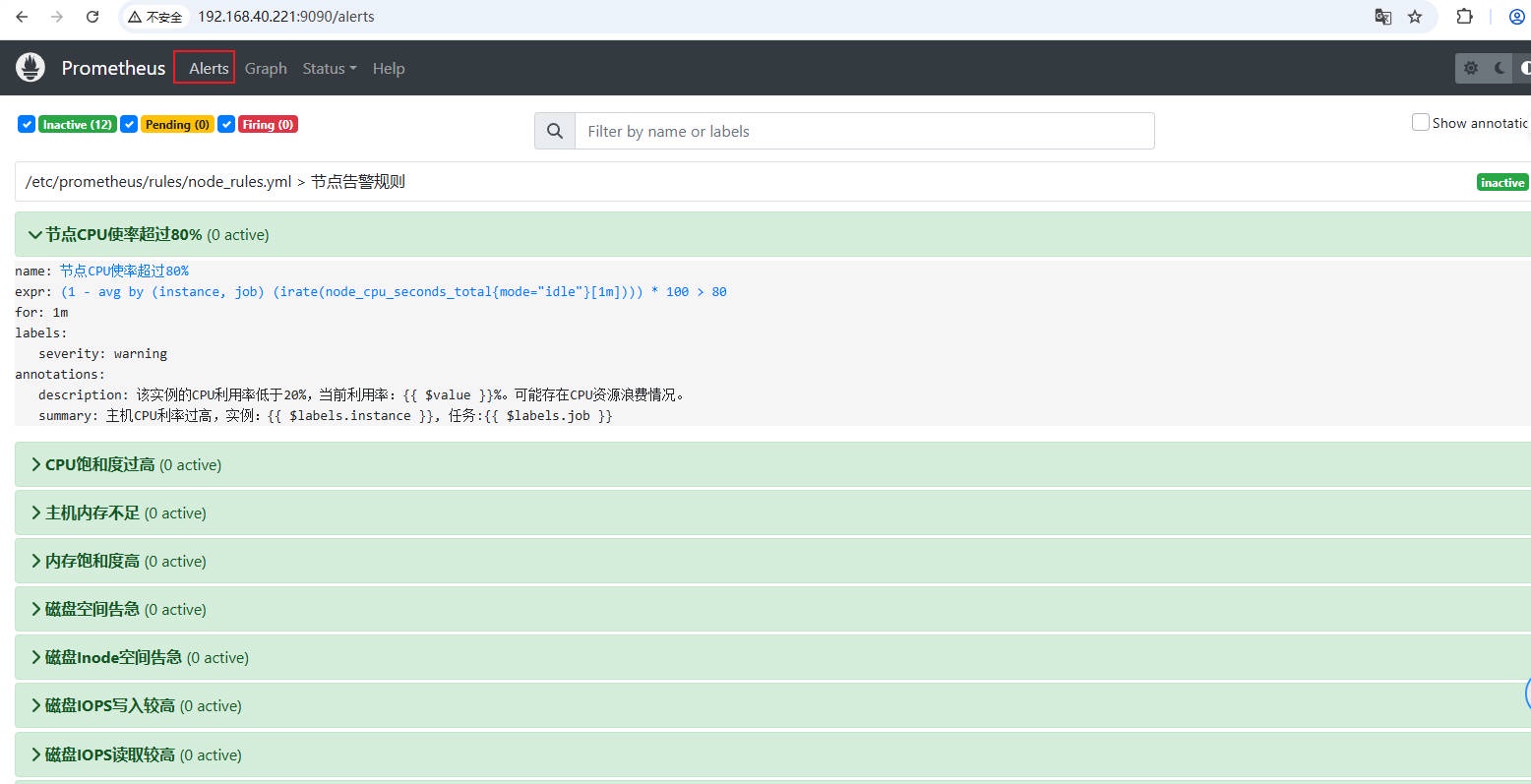
# 1.4 检查告警规则⽂件
# 1.5 导入 Grafana 模板
在 Grafana 的官方插件库中,有很多 Node-exporter 模板。其中相对受欢的模板的 ID 是: 11074、1860。
11074:模板包括了 CPU、内存、磁盘、网络、温度传感器等指标(常用)。
1860:模板包括 CPU、内存、磁盘、网络等。这运行状况,及时发现潜在问题并进行调优。
# 二. Prometheus 监控 RabbitmQ
# 2.1 配置 Prometheus
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
#2. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 2.2 RabbitMQ 告警规则文件
#1. 配置 rabbitmq 告警规则 | |
[root@prom-node01 ~]# cat /etc/prometheus/rules/rabbitmq_rules.yml | |
groups: | |
- name: rabbitmq告警规则 | |
rules: | |
- alert: RabbitMQDown | |
expr: up{instance="prom-node02.oldxu.net:15692", job="rabbitmq"} != 1 | |
labels: | |
severity: High | |
annotations: | |
summary: "Rabbitmq Down,实例:" | |
description: "Rabbitmq_exporter连不上RabbitMQ!" | |
- alert: RabbitMQ队列已就绪的消息过多 | |
expr: avg_over_time(rabbitmq_queue_messages_ready[5m]) > 500 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: ' RabbitMQ实例的队列消息准备过多' | |
description: '实例中平均准备好待消费的消息数量超过500,当前平均值为。' | |
- alert: RabbitMQ队列中已消费但未确认的消息过多 | |
expr: avg_over_time(rabbitmq_queue_messages_unacked[5m]) > 500 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: ' RabbitMQ实例的队列消息确认存在延迟' | |
description: ' 实例中平均已被消费但未被确认的消息数量超过500,当前平均值为。' | |
- alert: RabbitMQ磁盘空间预测不足 | |
expr: predict_linear(rabbitmq_disk_space_available_bytes[24h], 60*60*24*10) < rabbitmq_disk_space_available_limit_bytes | |
for: 1h | |
labels: | |
severity: critical | |
annotations: | |
summary: ' RabbitMQ实例的磁盘空间预测不足。' | |
description: '基于过去24小时磁盘可用空间数据预测,未来10天内磁盘的可用空间可能低于默认配置的50MB。' | |
- alert: RabbitMQ文件描述符使用率过高 | |
expr: max_over_time(rabbitmq_process_open_fds[5m]) / rabbitmq_process_max_fds * 100 > 80 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: ' RabbitMQ实例的文件描述符使用率过高' | |
description: ' 实例打开的文件描述符数量最大值,占文件描述限制的比率超过80%,当前比率为%。' | |
- alert: RabbitMQ TCP套接字使用率过高 | |
expr: max_over_time(rabbitmq_process_open_tcp_sockets[5m]) / rabbitmq_process_max_tcp_sockets * 100 > 80 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: ' RabbitMQ实例的TCP套接字使用率过高' | |
description: ' 实例打开的TCP套接字数量最大值,占操作系统允许的TCP连接数限制的比率超过80%,当前比率为%。' | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/rabbitmq_rules.yml | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 2.3 导入 Grafana 模板
导⼊ RabbitMQ 的 Grafana 模板。ID 为 10991
# 三. Prometheus 监控 Nginx
# 3.1 安装并配置 Nginx
#1. 安装 Nginx | |
[root@prom-node03 ~]# yum install nginx -y | |
[root@prom-node03 ~]# cat /etc/nginx/conf.d/mointor.oldxu.net.conf | |
server { | |
listen 8888; | |
server_name monitor.oldxu.net; | |
location /nginx_status { | |
stub_status on; | |
} | |
} | |
[root@prom-node03 ~]# nginx -t | |
[root@prom-node03 ~]# systemctl enable nginx && systemctl start nginx | |
#2. 检查 Nginx 的状态⻚⾯ | |
[root@prom-node03 ~]# curl http://localhost:8888/nginx_status | |
Active connections: 1 | |
server accepts handled requests | |
1 1 1 | |
Reading: 0 Writing: 1 Waiting: 0 |
# 3.2 安装并配置 Nginx-exporter
#1. 下载 Nginx-exporter | |
[root@prom-node03 ~]# wget https://github.com/nginxinc/nginx-prometheus-exporter/releases/download/v1.1.0/nginx-prometheus-exporter_1.1.0_linux_amd64.tar.gz | |
#加速地址 | |
[root@prom-node03 ~]# wget https://mirror.ghproxy.com/https://github.com/nginxinc/nginx-prometheus-exporter/releases/download/v1.1.0/nginx-prometheus-exporter_1.1.0_linux_amd64.tar.gz | |
#2. 将 Nginx_exporter 安装到指定的路径 | |
[root@prom-node03 ~]# mkdir /etc/nginx_exporter_1.1.0 | |
[root@prom-node03 ~]# tar xf nginx-prometheus-exporter_1.1.0_linux_amd64.tar.gz -C /etc/nginx_exporter_1.1.0/ | |
[root@prom-node03 ~]# ln -s /etc/nginx_exporter_1.1.0/ /etc/nginx_exporter | |
[root@prom-node03 nginx_exporter]# ./nginx-prometheus-exporter --web.listen-address=:9113 --nginx.scrape-uri=http://127.0.0.1:8888/nginx_status | |
#3. 为 nginx_exporter 准备 system 启停⽂件 | |
[root@prom-node03 ~]# cat /usr/lib/systemd/system/nginx_exporter.service | |
[Unit] | |
Description=nginx-exporter | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
ExecStart=/etc/nginx_exporter/nginx-prometheus-exporter \ | |
--web.listen-address=:9113 \ | |
--web.telemetry-path="/metrics" \ | |
--nginx.scrape-uri=http://127.0.0.1:8888/nginx_status | |
Restart=on-failure | |
RestartSec=20 | |
[Install] | |
WantedBy=multi-user.target | |
#4. 启动 nginx_exporter 服务,它默认监听在 9113 端⼝上 | |
[root@prom-node03 ~]# systemctl daemon-reload && systemctl enable nginx_exporter && systemctl start nginx_exporter | |
[root@prom-node03 ~]# netstat -lntp|grep 9113 | |
tcp6 0 0 :::9113 :::* LISTEN 1829/nginx-promethe | |
#5. 访问 nginx_exporter 暴露的 metrics,检查是否能获取到对应的指标数据 | |
[root@prom-node03 nginx_exporter]# curl http://127.0.0.1:9113/metrics | |
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles. | |
# TYPE go_gc_duration_seconds summary | |
go_gc_duration_seconds{quantile="0"} 0 | |
go_gc_duration_seconds{quantile="0.25"} 0 | |
go_gc_duration_seconds{quantile="0.5"} 0 | |
go_gc_duration_seconds{quantile="0.75"} 0 |
# 3.3 配置 Prometheus
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
#2. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 3.4 Nginx 告警规则⽂件
#1. 具体的告警规则示例⽂件(需要根据公司实际情况进⾏调整) | |
[root@prom-node01 ~]# cat /etc/prometheus/rules/nginx_rules.yml | |
groups: | |
- name: nginx告警规则 | |
rules: | |
- alert: Nginx Server Down | |
expr: nginx_up == 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "Nginx 服务不存活, 实例:" | |
description: "nginx_exporter连不上Nginx了,当前状态为: " | |
- alert: Nginx活跃连接数过高 | |
expr: avg_over_time(nginx_connections_active[5m]) > 500 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Nginx 活跃连接数过高, 实例:" | |
description: " Nginx 的平均活跃连接数超过了设定的500阈值,当前值为 。" | |
- alert: Nginx等待连接数高 | |
expr: max_over_time(nginx_connections_waiting[5m]) > 100 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Nginx 等待连接数过高, 实例:" | |
description: "Nginx 的等待连接数超过了设定的100阈值,当前最大值为 。可能后端服务存在瓶颈。" | |
- alert: Nginx读写入率异常 | |
expr: (nginx_connections_reading - nginx_connections_writing) / nginx_connections_reading * 100 > 10 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "Nginx 读写入率异常, 实例:" | |
description: "Nginx 读取请求的数量高于写请求的数量,当前读请求高于写请求比率是: " | |
- alert: Nginx⼤量TCP连接处理失败 | |
expr: nginx_connections_accepted - nginx_connections_handled > 50 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "Nginx 大量TCP连接处理失败, 实例:" | |
description: "Nginx 接受的连接数与处理成功的连接数之差超过了50,当前差值为" | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/node_rules.yml | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 3.5 导入 Grafana 模板
导⼊ nginx 的 Grafana 模板。ID 为 12708
# 四. Prometheus 监控 Tomcat
# 4.1 安装并配置 Tomcat
#1. 安装 tomcat | |
[root@prom-node03 nginx_exporter]# yum install tomcat tomcat-webapps -y | |
#2. 下载所依赖的 jar 包 | |
[root@prom-node03 ~]# wget https://search.maven.org/remotecontent?filepath=io/prometheus/simpleclient/0.12.0/simpleclient-0.12.0.jar | |
[root@prom-node03 ~]# wget https://search.maven.org/remotecontent?filepath=io/prometheus/simpleclient_common/0.12.0/simpleclient_common-0.12.0.jar | |
[root@prom-node03 ~]# wget https://search.maven.org/remotecontent?filepath=io/prometheus/simpleclient_hotspot/0.12.0/simpleclient_hotspot-0.12.0.jar | |
[root@prom-node03 ~]# wget https://search.maven.org/remotecontent?filepath=io/prometheus/simpleclient_servlet/0.12.0/simpleclient_servlet-0.12.0.jar | |
[root@prom-node03 ~]# wget https://search.maven.org/remotecontent?filepath=io/prometheus/simpleclient_servlet_common/0.12.0/simpleclient_servlet_common-0.12.0.jar | |
[root@prom-node03 ~]# wget https://search.maven.org/remotecontent?filepath=nl/nlighten/tomcat_exporter_client/0.0.15/tomcat_exporter_client-0.0.15.jar | |
[root@prom-node03 ~]# wget https://search.maven.org/remotecontent?filepath=nl/nlighten/tomcat_exporter_servlet/0.0.15/tomcat_exporter_servlet-0.0.15.war | |
# 整合包的下载地址 | |
[root@prom-node03 ~]# wget https://mirror.ghproxy.com/https://github.com/Im-oldxu/tomcat-exporter/releases/download/tomcat_exporter-0.0.17/tomcat_exporter.tar.gz | |
#3. 将 jar 包和 war 包分别拷⻉⾄对应的⽬录下 | |
[root@prom-node03 ~]# cp tomcat_exporter/*.jar /usr/share/tomcat/lib/ | |
[root@prom-node03 ~]# cp tomcat_exporter/*.war /usr/share/tomcat/webapps/ | |
#4. 启动 Tomcat | |
[root@prom-node03 ~]# systemctl start tomcat && systemctl enable tomcat | |
#5. 访问 tomcat 的 metrics | |
[root@prom-node03 ~]# curl http://localhost:8080/metrics/ | |
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds. | |
# TYPE process_cpu_seconds_total counter | |
process_cpu_seconds_total 7.37 | |
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds. | |
# TYPE process_start_time_seconds gauge | |
process_start_time_seconds 1.70921425481E9 | |
# HELP process_open_fds Number of open file descriptors. | |
# TYPE process_open_fds gauge | |
process_open_fds 65.0 |
# 4.2 配置 Prometheus
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
- job_name: "tomcat" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8080"] | |
#. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 4.3 Tomcat 告警规则⽂件
#1. 具体的告警规则示例⽂件 | |
[root@prom-node01 ~]# cat /etc/prometheus/rules/tomcat_rules.yml | |
groups: | |
- name: tomcat告警规则 | |
rules: | |
- alert: Tomcat活跃连接数过⾼ | |
expr: tomcat_connections_active_total / tomcat_connections_active_max* 100 >=80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Tomcat服务器活跃连接数过高, 实例:" | |
description: | |
Tomcat最大连接数是 <!--swig127--> | |
Tomcat目前连接数是 <!--swig128--> | |
Tomcat活跃连接数已超过最大活跃连接数的80%, 当前值为 <!--swig129-->% | |
- alert: Tomcat处理请求超过5秒 | |
expr: rate(tomcat_requestprocessor_time_seconds[5m]) > 5 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Tomcat处理请求时间过长, 实例:" | |
description: "Tomcat在过去5分钟的平均处理请求时间超过5秒,当前值 。" | |
- alert: "Tomcat会话拒绝率超过20%" | |
expr: (tomcat_session_rejected_total / (tomcat_session_created_total +tomcat_session_rejected_total)) * 100 > 20 | |
for: 5m | |
labels: | |
severity: critical | |
annotations: | |
summary: "Tomcat会话拒绝率过高, 实例:" | |
description: "Tomcat在Host: 的 的上下文中的会话拒绝率超过20%,当前值 。" | |
- alert: "Tomcat线程使用率过高" | |
expr: (tomcat_threads_active_total / tomcat_threads_max) * 100 > 80 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Tomcat线程使⽤率过⾼, 实例:" | |
description: | |
Tmcat最大线程数是 <!--swig137--> | |
Tomcat目前线程数是 <!--swig138--> | |
Tomcat线程数已超过最大活跃连接数的80%, 当前值为 <!--swig139-->% | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/node_rules.yml | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 4.4 导入 Grafana 模板
1、下载对应的 dashboard
wget https://mirror.ghproxy.com/https://github.com/nlighten/tomcat_exporter/blob/master/dashboard/example.json |
# 五. Prometheus 监控 SpringBoot
# 5.1 下载 jmx-exporter
1、访问 github, https://github.com/prometheus/jmx_exporter/releases ,下载 java-expoter
[root@prom-node03 ~]# mkdir /etc/jmx_exporter | |
[root@prom-node03 ~]# cd /etc/jmx_exporter | |
[root@prom-node03 springboot]# wget https://repo.maven.apache.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.20.0/jmx_prometheus_javaagent-0.20.0.jar |
2、准备 config.yml 配置⽂件(规则⽂件可以定义要暴露哪些指标给 Prometheus)
[root@prom-node03 ~]# cat /etc/jmx_exporter/config.yaml | |
rules: | |
- pattern: ".*" |
# 5.2 运⾏ SpringBoot 应⽤
#1、安装 java 基础环境 | |
[root@prom-node03 ~]# yum install java-11-openjdk maven -y | |
[root@prom-node03 ~]# wget -O /etc/maven/settings.xml https://linux.oldxu.net/settings.xml | |
#2、下载 java 应⽤然后进⾏编译 | |
[root@prom-node03 ~]# wget http://file.oldxu.net/jenkins/springboot-devops-myapp-java11-jar.tar.gz | |
[root@prom-node03 ~]# tar xf springboot-devops-myapp-java11-jar.tar.gz | |
[root@prom-node03 ~]# cd springboot-devops-myapp-jar/ | |
[root@prom-node03 springboot-devops-myapp-jar]# mvn package | |
#3、运⾏ java 应⽤,并加载 jmx 监控,监听 12345 端⼝, <path_to_jmx_exporter.jar>=<exporter_port>:<path_to_config.yaml> | |
[root@prom-node03 springboot-devops-myapp-jar]# java \ | |
-javaagent:/etc/jmx_exporter/jmx_prometheus_javaagent-0.20.0.jar=12345:/etc/jmx_exporter/config.yaml \ | |
-jar -Xms50m -Xmx50m target/devops-myapp-1.0.jar \ | |
--server.port=8081 &>/var/log/springboot.log & | |
#4、检查对应的端⼝是否正常 | |
[root@prom-node03 springboot-devops-myapp-jar]# curl http://localhost:12345/metrics | |
# HELP jmx_scrape_error Non-zero if this scrape failed. | |
# TYPE jmx_scrape_error gauge | |
jmx_scrape_error 0.0 | |
# HELP jmx_scrape_cached_beans Number of beans with their matching rule cached |
# 5.3 配置 Prometheus
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
- job_name: "tomcat" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8080"] | |
- job_name: "jmx_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:12345"] | |
#2. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 5.4 JMX 告警规则⽂件
[root@prom-node01 ~]# cat /etc/prometheus/rules/jvm_rules.yml | |
groups: | |
- name: "JVM告警规则" | |
rules: | |
- alert: JVM堆内存使用率过高 | |
expr: jvm_memory_bytes_used{area="heap",} / jvm_memory_bytes_max{area="heap",} * 100 > 80 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "JVM 堆内存使用率过高, 实例:, job: " | |
description: "JVM堆内存使用率超过80%, 当前值 %" | |
- alert: JVMGC时间过长 | |
expr: sum (rate(jvm_gc_collection_seconds_sum[5m]) / rate(jvm_gc_collection_seconds_count[5m])) by (gc, instance, job) > 1 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "JVM GC时间过长, 实例:, job: " | |
description: "JVM 的回收时间超过1s,当前值 s" | |
- alert: JVM死锁线程过多 | |
expr: min_over_time(jvm_threads_deadlocked[5m]) > 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "JVM检测到死锁线程" | |
description: "在过去5分钟内JVM检测到存在死锁线程, 当前值 。" | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/jvm_rules.yml | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 5.5 导入 Grafana 模板
导⼊⼀个 JVM 的 Grafana 模板。Dashboard ID 为 14845
# 六。安装并配置 mysql_master
# 6.1 安装并配置 mysql_master
#1、安装 Mysql5.7 | |
[root@prom-node03 ~]# yum install -y mysql-community-server | |
[root@prom-node03 ~]# systemctl start mysqld && systemctl enable mysqld | |
[root@prom-node03 ~]# mysql -uroot -p$(awk '/temporary password/{print $NF}' /var/log/mysqld.log) | |
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'Superman*2023'; | |
#2、创建⼀个 mysql_exporter 专属的监控账户 | |
mysql> create user 'exporter'@'localhost' identified by 'Superman*2023' WITH MAX_USER_CONNECTIONS 3; | |
mysql> grant process,replication client,select on *.* to 'exporter'@'localhost'; | |
#3、创建 MySQL 从库复制的账户 | |
mysql> grant replication slave on *.* to 'repl'@'%' identified by 'Superman*2023'; | |
mysql> flush privileges; | |
#4. 配置主库 | |
[root@prom-node03 ~]# vim /etc/my.cnf | |
server-id=1 | |
log-bin=mysql-bin | |
read-only=0 | |
[root@prom-node03 ~]# systemctl restart mysqld |
# 6.2 安装并配置 mysql_slave
#1、从库配置 | |
[root@prom-node04 ~]# yum install -y mysql-community-server | |
[root@db02 ~]# vim /etc/my.cnf | |
server-id=2 | |
read-only=1 | |
#2、创建⼀个 mysql_exporter 专属的监控账户 | |
grant all on *.* to 'exporter'@'localhost' identified by 'Superman*2023'; | |
#3、获取主库的信息,⽽后配置从库的 change master | |
mysql> show master status; | |
+------------------+----------+--------------+------------------+-------------------+ | |
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | | |
+------------------+----------+--------------+------------------+-------------------+ | |
| mysql-bin.000007 | 154 | | | | | |
+------------------+----------+--------------+------------------+-------------------+ | |
1 row in set (0.01 sec) | |
#4、配置从服务器,连接主服务器 | |
mysql> change master to master_host='192.168.40.223',master_user='repl',master_password='Superman*2023',master_log_file='mysql-bin.000007',master_log_pos=154; | |
#5. 开启从库 | |
mysql> start slave; | |
#6. 检查主从复制状态 | |
mysql> show slave status\G |
# 6.3 安装并配置 mysqld_exporter
1、访问 mysqld_exporter 的 github 地址, https://github.com/prometheus/mysqld_exporter/releases 下载 mysqld-exporter
#1、下载 mysqld_expor | |
[root@prom-node03 ~]# wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.15.0/mysqld_exporter-0.15.0.linux-amd64.tar.gz | |
# 加速地址 | |
[root@prom-node03 ~]# wget https://mirror.ghproxy.com/https://github.com/prometheus/mysqld_exporter/releases/download/v0.15.0/mysqld_exporter-0.15.0.linux-amd64.tar.gz | |
#2、解压 mysqld_expor | |
[root@prom-node03 ~]# tar xf mysqld_exporter-0.15.0.linux-amd64.tar.gz -C /etc/ | |
[root@prom-node03 ~]# ln -s /etc/mysqld_exporter-0.15.0.linux-amd64/ /etc/mysqld_exporter | |
#3、启动 mysqld_expor | |
[root@prom-node03 ~]# export MYSQLD_EXPORTER_PASSWORD=Superman*2023 | |
[root@prom-node03 ~]# /etc/mysqld_exporter/mysqld_exporter --mysqld.address=localhost:3306 --mysqld.username=exporter | |
#4、编写 mysqld_exporter 启动⽂件 | |
[root@prom-node03 ~]# cat /usr/lib/systemd/system/mysqld_exporter.service | |
[Unit] | |
Description=mysqld_exporter | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
Environment='MYSQLD_EXPORTER_PASSWORD=Superman*2023' | |
ExecStart=/etc/mysqld_exporter/mysqld_exporter \ | |
--mysqld.address=localhost:3306 \ | |
--mysqld.username=exporter \ | |
--web.listen-address=:9104 \ | |
--web.telemetry-path="/metrics" \ | |
--collect.info_schema.processlist \ | |
--collect.info_schema.innodb_tablespaces \ | |
--collect.info_schema.innodb_metrics \ | |
--collect.info_schema.query_response_time \ | |
--collect.info_schema.userstats \ | |
--collect.info_schema.tables \ | |
--collect.global_status \ | |
--collect.global_variables \ | |
--collect.slave_status \ | |
--collect.binlog_size \ | |
--collect.engine_innodb_status | |
ExecReload=/bin/kill -HUP $MAINPID | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target | |
#4、启动 mysqld_exporter,并检查服务 | |
[root@prom-node03 ~]# systemctl daemon-reload | |
[root@prom-node03 ~]# systemctl start mysqld_exporter | |
#5、测试 mysqld_exporter 能否获取到对应的指标 | |
[root@prom-node03 ~]# netstat -lntp |grep 9104 | |
tcp6 0 0 :::9104 :::* LISTEN 2863/mysqld_exporte | |
[root@prom-node03 ~]# curl http://localhost:9104/metrics |
# 6.4 配置 Prometheus
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
- job_name: "tomcat" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8080"] | |
- job_name: "jmx_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:12345"] | |
- job_name: "mysqld_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9104"] | |
labels: | |
service: database | |
role: master | |
- targets: ["prom-node04.oldxu.net:9104"] | |
labels: | |
service: database | |
role: slave | |
#2. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 6.5 MySQL 告警规则⽂件
#1、编写 MySQL 告警规则⽂件 | |
[root@prom-node01 ~]# cat /etc/prometheus/rules/mysql_rules.yml | |
groups: | |
- name: mysql告警规则 | |
rules: | |
- alert: MySQL主库实例宕机 | |
expr: mysql_up{role="master"} == 0 | |
for: 0m | |
labels: | |
severity: critical | |
annotations: | |
summary: "MySQL实例宕机, 实例: " | |
description: "服务: ⻆⾊: 已经宕机。" | |
- alert: MySQL从库实例宕机 | |
expr: mysql_up{role="slave"} == 0 | |
for: 0m | |
labels: | |
severity: critical | |
annotations: | |
summary: "MySQL实例宕机, 实例: " | |
description: "服务: ⻆⾊: 已经宕机。" | |
- alert: MySQL实例重启 | |
expr: sum(mysql_global_status_uptime) by (instance,job,service,role)< 60 | |
for: 0m | |
labels: | |
severity: warning | |
annotations: | |
summary: "MySQL实例重启, 实例 " | |
description: "服务: ⻆⾊: 运行时间小于60s。当前值 " | |
- alert: MySQL连接数使用率超过80% | |
expr: max_over_time(mysql_global_status_threads_connected[5m]) / mysql_global_variables_max_connections * 100 > 80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "MySQL连接数过高, 实例 ,服务: ⻆⾊: " | |
description: "该实例MySQL的连接数在过去5分钟内超过了最大连接数的80%, 当前值 %。" | |
- alert: MySQL活跃线程数高 | |
expr: avg_over_time(mysql_global_status_threads_running[5m]) / mysql_global_variables_max_connections * 100 > 60 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "MySQL活跃线程数过高, 实例 ,服务: 角色: " | |
description: "该实例MySQL的活跃线程数在过去5分钟内持续超过了最大连接数的60%, 当前值 %。" | |
- alert: MySQL查询率(QPS)过高 | |
expr: irate(mysql_global_status_queries[5m]) > 1000 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "MySQL查询率(QPS)超标, 实例 ,服务: 角色: " | |
description: "该实例MySQL的查询率(QPS)在过去5分钟内超过1000, 当前值 。" | |
- alert: MySQL事务率(TPS)过高 | |
expr: sum(rate(mysql_global_status_commands_total{command=~"(commit|rollback)"}[5m])) without (command) > 100 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "MySQL事务率(TPS)超标, 实例 ,服务: 角色: " | |
description: "该实例MySQL的事务率(TPS)在过去5分钟内超过100, 当前值 。" | |
- alert: MySQL文件描述符使用率过高 | |
expr: mysql_global_status_open_files / mysql_global_variables_open_files_limit * 100 > 80 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: "MySQL活跃线程数过高, 实例 ,服务: 角色: " | |
description: "该实例MySQL的文件描述符使用率超过80%,当前值 %可能需要增加文件描述符限制。" | |
- alert: Mysql从库IO线程未运行 | |
expr: mysql_slave_status_slave_io_running == 0 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "MySQL从库IO线程已停止, 实例 " | |
description: "该MySQL实例IO线程已停止,当前值 " | |
- alert: Mysql从库SQL线程未运行 | |
expr: mysql_slave_status_slave_sql_running == 0 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "MySQL从库SQL线程已停止, 实例 " | |
description: "该MySQL实例SQL线程已停止,当前值 " | |
- alert: Mysql从库复制延迟过高 | |
expr: mysql_slave_status_seconds_behind_master - mysql_slave_status_sql_delay > 5 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "MySQL从库复制延迟过高, 实例 " | |
description: "该实例MySQL的复制延迟超过5s,当前值 s" | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/mysql_rules.yml | |
Checking /etc/prometheus/rules/mysql_rules.yml | |
SUCCESS: 11 rules found | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 6.6 导入 Grafana 模板
导⼊⼀个 MySQL 的 Grafana 模板。Dashboard ID 为 7362、9625 ,⽽监控 MySQL 主从的 Dashboard 可以使⽤ 11323
# 七. Prometheus 监控 Redis
# 7.1 安装并配置 Redis
[root@prom-node03 ~]# yum install redis -y | |
[root@prom-node03 ~]# vim /etc/redis.conf | |
maxmemory 200mb | |
[root@prom-node03 ~]# systemctl start redis && systemctl enable redis | |
[root@prom-node03 ~]# netstat -lntp|grep redis | |
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 2532/redis-server 1 |
# 7.2 安装并配置 redis_exporter
1、访问 redis_exporter 的 github 地址, https://github.com/oliver006/redis_exporter/releases ,下载 redis_exporter
#1、下载 redis_exporter | |
[root@prom-node03 ~]# wget https://github.com/oliver006/redis_exporter/releases/download/v1.57.0/redis_exporter-v1.57.0.linux-amd64.tar.gz | |
#加速地址 | |
[root@prom-node03 ~]# wget https://mirror.ghproxy.com/https://github.com/oliver006/redis_exporter/releases/download/v1.57.0/redis_exporter-v1.57.0.linux-amd64.tar.gz | |
#2、解压 redis_exporter | |
[root@prom-node03 ~]# tar xf redis_exporter-v1.57.0.linux-amd64.tar.gz -C /etc | |
[root@prom-node03 ~]# ln -s /etc/redis_exporter-v1.57.0.linux-amd64/ /etc/redis_exporter | |
#3、配置 redis_exporter 启动⽂件 | |
[root@prom-node03 ~]# cat /usr/lib/systemd/system/redis_exporter.service | |
[Unit] | |
Description=redis_exporter | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
ExecStart=/etc/redis_exporter/redis_exporter \ | |
-redis.addr="redis://localhost:6379" | |
-redis.password="" | |
-web.listen-address=":9121" \ | |
-web.telemetry-path="/metrics" \ | |
ExecReload=/bin/kill -HUP $MAINPID | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target | |
#4、启动 redis_exporter | |
[root@prom-node03 ~]# systemctl daemon-reload | |
[root@prom-node03 ~]# systemctl start redis_exporter | |
[root@prom-node03 ~]# systemctl enable redis_exporter | |
[root@prom-node03 ~]# netstat -lntp|grep 9121 | |
tcp6 0 0 :::9121 :::* LISTEN 2600/redis_exporter | |
#5、访问 redis 的 metrics | |
[root@prom-node03 ~]# curl http://localhost:9121/metrics | |
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles. | |
# TYPE go_gc_duration_seconds summary | |
go_gc_duration_seconds{quantile="0"} 4.7772e-05 | |
go_gc_duration_seconds{quantile="0.25"} 4.7772e-05 | |
go_gc_duration_seconds{quantile="0.5"} 9.3206e-05 | |
go_gc_duration_seconds{quantile="0.75"} 9.3206e-05 | |
go_gc_duration_seconds{quantile="1"} 9.3206e-05 | |
go_gc_duration_seconds_sum 0.000140978 | |
go_gc_duration_seconds_count 2 | |
# HELP go_goroutines Number of goroutines that currently exist. | |
# TYPE go_goroutines gauge | |
go_goroutines 8 |
# 7.3 配置 Prometheus
#1、修改 Prometheus 配置 | |
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
- job_name: "tomcat" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8080"] | |
- job_name: "jmx_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:12345"] | |
- job_name: "mysqld_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9104"] | |
labels: | |
service: database | |
role: master | |
- targets: ["prom-node04.oldxu.net:9104"] | |
labels: | |
service: database | |
role: slave | |
- job_name: "redis_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9121"] | |
#2. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 7.4 Redis 告警规则⽂件
#1、编写 Redis 告警规则⽂件 | |
[root@prom-node01 ~]# cat /etc/prometheus/rules/redis_rules.yml | |
groups: | |
- name: redis告警规则 | |
rules: | |
- alert: Redis实例宕机 | |
expr: sum(redis_up) by (instance, job) == 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "Redis实例宕机, " | |
description: "Redis实例 在过去1分钟内无法连接。" | |
- alert: Redis实例重启 | |
expr: sum(redis_uptime_in_seconds) by (instance, job) < 60 | |
for: 0m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Redis实例 重启" | |
description: "Redis实例 出现重启。当前运行时间: 秒。" | |
- alert: Redis连接数过高 | |
expr: redis_connected_clients / redis_config_maxclients * 100 > 80 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Redis实例 连接数超过80%" | |
description: "Redis实例 当前连接数占最大连接数的比率超过80%。当前比率: %。" | |
- alert: Redis连接被拒绝 | |
expr: increase(redis_rejected_connections_total[1h]) > 0 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Redis实例 有连接被拒绝" | |
description: "Redis实例 在过去1小时内有连接被拒绝。当前被拒绝的连接数: 。" | |
- alert: Redis内存使用率过高 | |
expr: redis_memory_used_bytes / redis_memory_max_bytes * 100 > 80 | |
for: 5m | |
labels: | |
severity: critical | |
annotations: | |
summary: "Redis实例 内存使用率超过80%" | |
description: "Redis实例 当前内存使用率超过配置的最大内存值的80%。当前内存使用率: %。" | |
- alert: Redis缓存命中率低 | |
expr: | | |
irate(redis_keyspace_hits_total[5m]) / | |
(irate(redis_keyspace_hits_total[5m]) + irate(redis_keyspace_misses_total[5m])) * 100 < 90 | |
for: 10m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Redis实例 缓存命中率低于90%" | |
description: "Redis实例 最近5分钟内的缓存命中率低于90%。当前命中率: %。" | |
- alert: Redis即将过期的Key数量过多 | |
expr: | | |
sum(redis_db_keys_expiring) by (instance, job, db) / | |
sum(redis_db_keys) by (instance, job, db) * 100 > 50 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Redis实例 中的数据库 有过多即将过期的Key" | |
description: "Redis实例 中的数据库 有超过50%的Key即将过期。当前比率: %。" | |
- alert: RedisRDB备份失败 | |
expr: redis_rdb_last_bgsave_status == 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "Redis实例 RDB备份失败" | |
description: "Redis实例 最近的RDB备份尝试失败。" | |
- alert: RedisRDB备份时间过长 | |
expr: redis_rdb_last_bgsave_duration_sec > 3 and redis_rdb_last_bgsave_status == 1 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Redis实例 RDB备份成功但耗时超过3秒" | |
description: "Redis实例 RDB备份成功,但备份耗时超过了3秒。持续时间: 秒。" | |
- alert: RedisRDB备份过期 | |
expr: (time() - redis_rdb_last_save_timestamp_seconds) > 36000 | |
for: 5m | |
labels: | |
severity: critical | |
annotations: | |
summary: "Redis实例 超过10小时未进行RDB备份" | |
description: "Redis实例 已超过10小时没有生成新的RDB备份文件。" | |
- alert: Redis命令拒绝率过高 | |
expr: | | |
sum(irate(redis_commands_rejected_calls_total[5m])) by (instance, job) / | |
sum(irate(redis_commands_total[5m])) by (instance, job) * 100 > 25 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: "Redis实例 命令拒绝率超过25%" | |
description: "Redis实例 的命令拒绝率超过了25%。当前拒绝率: %。" | |
- alert: Redis命令平均响应时间过长 | |
expr: | | |
sum(rate(redis_commands_duration_seconds_total[5m])) by (instance,job) / | |
sum(rate(redis_commands_processed_total[5m])) by (instance, job) >0.250 | |
for: 5m | |
labels: | |
severity: critical | |
annotations: | |
summary: "Redis实例 命令平均响应时间超过250ms" | |
description: "Redis实例 的执⾏命令平均响应时间超过了250毫秒。当前平均响应时间: 秒。" | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/redis_rules.yml | |
Checking /etc/prometheus/rules/redis_rules.yml | |
SUCCESS: 12 rules found | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 7.5 导入 Grafana 模板
导⼊⼀个 Redis 的 Grafana 模板。Dashboard ID 为 763
# 八. Prometheus 监控 Docker
Docker 的监控,可以使⽤ Docker ⾃带的 stats 命令来获取当前主机上运⾏中的容器的资源使⽤情况。例如:容器的 CPU 使⽤率、内存占⽤、⽹络 IO 以及磁盘 IO 等指标。
# 8.1 安装 Docker
1、添加 yum 源
[root@prom-node03 ~]# yum remove docker* -y && yum install -y yum-utils | |
[root@prom-node03 ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo | |
[root@prom-node03 ~]# yum install docker-ce -y |
2、安装并 docker
[root@prom-node03 ~]# sudo mkdir -p /etc/docker | |
[root@prom-node03 ~]# sudo tee /etc/docker/daemon.json <<-'EOF' | |
{ | |
"registry-mirrors": [ | |
"https://docker.credclouds.com", | |
"https://k8s.credclouds.com", | |
"https://quay.credclouds.com", | |
"https://gcr.credclouds.com", | |
"https://k8s-gcr.credclouds.com", | |
"https://ghcr.credclouds.com", | |
"https://do.nark.eu.org", | |
"https://docker.m.daocloud.io", | |
"https://docker.nju.edu.cn", | |
"https://docker.mirrors.sjtug.sjtu.edu.cn", | |
"https://docker.1panel.live", | |
"https://docker.rainbond.cc" | |
], | |
"exec-opts": ["native.cgroupdriver=systemd"] | |
} | |
EOF | |
[root@prom-node03 ~]# systemctl enable docker --now |
4、运⾏两个容器应⽤
[root@prom-node03 ~]# docker run -d -p3811:80 --name demoapp --memory="100m" oldxu3957/demoapp:v1.0 | |
[root@prom-node03 ~]# docker run -d -p3812:80 --name nginx --memory="50m" nginx:1.16 |
# 8.2 运⾏ Cadvisor
1、启动 Cadvisor 容器
[root@prom-node03 ~]# docker run -d --name=cadvisor \ | |
-p 8082:8080 \ | |
-v /:/rootfs:ro \ | |
-v /var/run:/var/run:ro \ | |
-v /sys:/sys:ro \ | |
-v /dev/disk/:/dev/disk:ro \ | |
-v /sys/fs/cgroup:/sys/fs/cgroup:ro \ | |
-v /var/lib/docker/:/var/lib/docker:ro \ | |
--privileged \ | |
uhub.service.ucloud.cn/oldxu/cadvisor:v0.47.2 |
2、Cadvisor 提供的 metrics 地址为 http://IP:8082/metrics
# 8.3 配置 Prometheus
[root@prom-node01 ~]# vim /etc/prometheus/prometheus.yml | |
scrape_configs: | |
- job_name: "docker" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8082"] | |
[root@prom-node01 ~]# curl -X POST http://localhost:9090/-/reload |
# 8.4 Docker 告警规则⽂件
#1、编写 Docker 告警规则⽂件 | |
[root@prom-node01 ~]# cat /etc/prometheus/rules/docker_rules.yml | |
groups: | |
- name: Docker的告警规则 | |
rules: | |
- alert: 容器CPU利用率高 | |
expr: sum(rate(container_cpu_usage_seconds_total{name!=""}[1m])) by (instance,name) * 100 > 80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "实例的容器CPU利用率高" | |
description: "容器的CPU利用率当前为%,超过了80%的阈值。" | |
- alert: 容器内存利用率高 | |
expr: | | |
sum(container_memory_working_set_bytes{name!=""}) by (instance,name) / | |
sum(container_spec_memory_limit_bytes{name!=""} > 0) by (instance,name) * 100 > 80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "实例的容器内存利用率高" | |
description: 容器<!--swig225-->的内存最大限制是<!--swig226-->MB , 目前利用率已达<!--swig227-->%,超过限制的80%。 | |
- alert: 容器整体内存利用率过高 | |
expr: sum(container_memory_working_set_bytes{name!=""}) / sum(machine_memory_bytes) * 100 > 80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "所有容器的总内存利用率过高" | |
description: "当前所有容器占用物理内存的总量为%,超过了物理内存的80%阈值。" | |
- alert: 容器网络发送速率过高 | |
expr: sum(rate(container_network_transmit_bytes_total{name!=""}[1m]))by (instance,job,name) * 8 / 1024 / 1024 > 50 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "实例的容器网络发送速率过高" | |
description: "容器的网络发送速率达到Mbps,超过了50Mbps的阈值。" | |
- alert: 容器网络接收速率过高 | |
expr: sum(rate(container_network_receive_bytes_total{name!=""}[1m])) by (instance,job,name) * 8 / 1024 / 1024 > 50 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "实例的容器网络接收速率过高" | |
description: "容器的网络接收速率达到Mbps,超过了50Mbps的阈值。" | |
- alert: 容器停止时间过长 | |
expr: sum(time() - container_last_seen{name!=""}) by (instance,name)> 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例的容器已停止" | |
description: "容器已停止运行超过60秒。当前停止时长 s" | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/docker_rules.yml | |
Checking /etc/prometheus/rules/docker_rules.yml | |
SUCCESS: 6 rules found | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 8.5 导入 Grafana 模板
导⼊⼀个 Docker Container 的 Grafana 模板。Dashboard ID 为 11600
# 九. Blackbox_exporter ⿊盒监控
Blackbox_exporter 是⼀个专⻔⽤于⿊盒监控的⼯具,它⽀持多种⽹络协议对⽬标对象进⾏检测,⽐如 HTTP、HTTPS、TCP 和 ICMP。这意味着我们可以⽤它来监控⽹站响应状态和响应时间、以及通过端⼝来判断服务是否正常运⾏。此外⽤户还可以通过设置不同的检查模块来定制 blackbox_exporter,以便它能够适应不同的检测需求。
# 9.1 安装 Blackbox_exporter
1、访问 blackbox_exporter 的 github 地址, https://github.com/prometheus/blackbox_exporter/releases ,下载 blackbox_exporter
#1. 下载 blackbox_exporter | |
[root@prom-node04 ~]# wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.24.0/blackbox_exporter-0.24.0.linux-amd64.tar.gz | |
#加速地址 | |
[root@prom-node04 ~]# wget https://mirror.ghproxy.com/https://github.com/prometheus/blackbox_exporter/releases/download/v0.24.0/blackbox_exporter-0.24.0.linux-amd64.tar.gz | |
#2、解压 blackbox_exporter | |
[root@prom-node04 ~]# tar xf blackbox_exporter-0.24.0.linux-amd64.tar.gz -C /etc | |
[root@prom-node04 ~]# ln -s /etc/blackbox_exporter-0.24.0.linux-amd64/ /etc/blackbox_exporter |
2、编辑 /etc/blackbox_exporter/blackbox.yml 默认配置⽂件,可以⾃⾏定义对应的模块,blackbox_exporter/example.yml
[root@prom-node04 ~]# cat /etc/blackbox_exporter/blackbox.yml | |
modules: | |
# http 检查模块 | |
http_2xx: | |
prober: http | |
http: | |
preferred_ip_protocol: "ip4" | |
valid_http_versions: [ "HTTP/1.1", "HTTP/2.0" ] | |
# Http Post 检查模块 | |
http_post_2xx: | |
prober: http | |
http: | |
method: POST | |
preferred_ip_protocol: "ip4" | |
valid_http_versions: [ "HTTP/1.1", "HTTP/2.0" ] | |
# TCP 检查模块 | |
tcp_connect: | |
prober: tcp | |
timeout: 5s | |
# ICMP 检查模块 | |
icmp: | |
prober: icmp | |
timeout: 5s | |
icmp: | |
preferred_ip_protocol: "ip4" | |
# DNS 检查模块 | |
dns_tcp: | |
prober: dns | |
dns: | |
transport_protocol: "tcp" | |
preferred_ip_protocol: "ip4" | |
query_name: "www.oldxu.net" | |
# SSH 检查模块 | |
ssh_banner: | |
prober: tcp | |
tcp: | |
query_response: | |
- expect: "^SSH-2.0-" | |
- send: "SSH-2.0-blackbox-ssh-check" |
3、配置 blackbox_exporter 启动⽂件
[root@prom-node04 ~]# cat /usr/lib/systemd/system/blackbox_exporter.service | |
[Unit] | |
Description=blackbox_exporter | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
ExecStart=/etc/blackbox_exporter/blackbox_exporter \ | |
--config.file=/etc/blackbox_exporter/blackbox.yml \ | |
--web.listen-address=:9115 | |
ExecReload=/bin/kill -HUP $MAINPID | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target |
4、启动 blackbox_exporter
[root@prom-node04 ~]# systemctl daemon-reload | |
[root@prom-node04 ~]# systemctl start blackbox_exporter | |
[root@prom-node04 ~]# systemctl enable blackbox_exporter | |
[root@prom-node04 ~]# netstat -lntp|grep 9115 | |
tcp6 0 0 :::9115 :::* LISTEN 1879/blackbox_expor |
5、访问 Blackbox_exporter
1、访问 Blackbox_exporter,通过 http://IP:9115
2、使⽤ blackbox_exporter 监控站点,需要传递⽬标 target ,以及检测⽅法 module
具体的 Url 地址:http://192.168.40.224:9115/probe?target=https://www.baidu.com&module=http_2xx&debug=true
3、针对 blackbox_exporter 的探测过程进⾏解读
Logs for the probe: | |
ts=2025-07-10T13:00:22.422589861Z caller=main.go:181 module=http_2xx target=https://www.baidu.com level=info msg="Beginning probe" probe=http timeout_seconds=119.5 | |
ts=2025-07-10T13:00:22.422705868Z caller=http.go:328 module=http_2xx target=https://www.baidu.com level=info msg="Resolving target address" target=www.baidu.com ip_protocol=ip4 | |
ts=2025-07-10T13:00:22.45404596Z caller=http.go:328 module=http_2xx target=https://www.baidu.com level=info msg="Resolved target address" target=www.baidu.com ip=183.2.172.17 | |
ts=2025-07-10T13:00:22.454537363Z caller=client.go:252 module=http_2xx target=https://www.baidu.com level=info msg="Making HTTP request" url=https://183.2.172.17 host=www.baidu.com | |
ts=2025-07-10T13:00:22.604504723Z caller=handler.go:120 module=http_2xx target=https://www.baidu.com level=info msg="Received HTTP response" status_code=200 | |
ts=2025-07-10T13:00:22.658174121Z caller=handler.go:120 module=http_2xx target=https://www.baidu.com level=info msg="Response timings for roundtrip" roundtrip=0 start=2025-07-10T21:00:22.454597016+08:00 dnsDone=2025-07-10T21:00:22.454597016+08:00 connectDone=2025-07-10T21:00:22.47947711+08:00 gotConn=2025-07-10T21:00:22.587945635+08:00 responseStart=2025-07-10T21:00:22.604420439+08:00 tlsStart=2025-07-10T21:00:22.479503968+08:00 tlsDone=2025-07-10T21:00:22.58792749+08:00 end=2025-07-10T21:00:22.658024376+08:00 | |
ts=2025-07-10T13:00:22.658287803Z caller=main.go:181 module=http_2xx target=https://www.baidu.com level=info msg="Probe succeeded" duration_seconds=0.23567288 | |
# 1、开始探测(msg="Beginning probe") 使⽤的是 http_2xx 模块,超时设置为 119.5 秒。 | |
# 2、解析⽬标地址(msg="Resolving target address") 正在尝试解析⽬标 www..com 的 IP 地址,使⽤的是 IPv4 协议。 | |
# 3、已解析⽬标地址(msg="Resolved target address") 成功解析为 183.2.172.17。 | |
# 4、发出 HTTP 请求(msg="Making HTTP request") 向 http://183.2.172.17 发出 HTTP 请求,请求中的 host 头设置为 www.baidu.com。 | |
# 5、收到 HTTP 响应(msg="Received HTTP response") 已收到状态码为 200 的 HTTP 响应,这意味着⽹⻚正常,服务器成功处理了请求。 | |
# 6、响应时间(msg="Response timings for roundtrip") 提供了对于整个请求 - 响应周期中每个步骤的具体时间点,包括 DNS 解析完成、TLS 握⼿开始和完成、连接建⽴、获得连接、响应开始等时间点。 | |
# 7、探测成功(msg="Probe succeeded") 探测操作成功完成,总耗时为 0.23567288 秒。 |
# 9.2 配置 Prometheus
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
- job_name: "tomcat" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8080"] | |
- job_name: "jmx_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:12345"] | |
- job_name: "mysqld_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9104"] | |
labels: | |
service: database | |
role: master | |
- targets: ["prom-node04.oldxu.net:9104"] | |
labels: | |
service: database | |
role: slave | |
- job_name: "redis_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9121"] | |
- job_name: 'blackbox_http' | |
metrics_path: /probe # metrics 的 path 这次不是 /metrics,⽽是 /probe | |
params: # 传递参数 | |
module: [http_2xx] # 调⽤哪个模块进⾏探测 | |
static_configs: | |
- targets: ["https://www.xuliangwei.com","http://www.oldxu.net","https://www.baidu.com","http://httpbin.org/status/400","https://httpstat.us/500","https://httpstat.us/502"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
# relabel_configs 是标签重写的配置,这⾥进⾏了三次操作: | |
# 1、将⽬标地址(__address__)赋予给__param_target,这是 Blackbox Exporter 需要的⽬标 target 参数。 | |
# 2、将__param_target 的内容复制到 instance 标签,这样 Prometheus UI 中显示的 instance 实例名称会是⽬标站点地址,⽽不是 Blackbox 的地址。 | |
# 3、最后,将实际发送探测请求的地址(__address__)设置为运⾏ Blackbox Exporter 的节点地址和端⼝(prom-node04.oldxu.net:9115),这样 Prometheus 就会向这个地址发送探测请求。 | |
#. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 9.3 配置 tcp、ssh、icmp 监控
#1、修改 Prometheus 配置 | |
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
- job_name: "tomcat" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8080"] | |
- job_name: "jmx_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:12345"] | |
- job_name: "mysqld_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9104"] | |
labels: | |
service: database | |
role: master | |
- targets: ["prom-node04.oldxu.net:9104"] | |
labels: | |
service: database | |
role: slave | |
- job_name: "redis_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9121"] | |
- job_name: 'blackbox_http' | |
metrics_path: /probe # metrics 的 path 这次不是 /metrics,是 /probe | |
params: # 传递参数 | |
module: [http_2xx] # 调哪个模块进探测 | |
static_configs: | |
- targets: ["https://www.xuliangwei.com","http://www.oldxu.net","https://www.baidu.com","http://httpbin.org/status/400","https://httpstat.us/500","https://httpstat.us/502"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_tcp' | |
metrics_path: /probe | |
params: | |
module: [tcp_connect] # 使 tcp_connect 模块 | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:3306","prom-node03.oldxu.net:6379"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_icmp' | |
metrics_path: /probe | |
params: | |
module: [icmp] # 使 icmp 模块 | |
static_configs: | |
- targets: ["prom-node01.oldxu.net","prom-node02.oldxu.net","prom-node03.oldxu.net"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_ssh' | |
metrics_path: /probe | |
params: | |
module: [ssh_banner] # 使⽤ ssh_banner 模块 | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:22","prom-node02.oldxu.net:22","prom-node03.oldxu.net:22"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
#2. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 9.4 Blackbox 告警规则⽂件
[root@prom-node01 ~]# cat /etc/prometheus/rules/blackbox_rules.yml | |
groups: | |
- name: Blackbox告警规则文件 | |
rules: | |
- alert: 探测失败 | |
expr: sum(probe_success == 0) by (instance, job) | |
for: 5m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 探测失败" | |
description: "探测目标 在 job 中失败。" | |
- alert: 站点整体平均请求时间过长 | |
expr: sum(avg_over_time(probe_http_duration_seconds[1m])) by (instance,job) > 3 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "实例 请求时间过长" | |
description: "实例 最近1分钟的平均请求时间超过3秒。当前平均请求时间:秒。" | |
- alert: 重定向次数过多 | |
expr: probe_http_redirects > 5 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: "实例 重定向次数过多" | |
description: "实例 在最近的探测中重定向次数超过5次。当前次数:次。" | |
- alert: 站点阶段耗时过⻓ | |
expr: | | |
( | |
probe_http_duration_seconds{phase="connect"} > 0.5 or | |
probe_http_duration_seconds{phase="processing"} > 0.5 or | |
probe_http_duration_seconds{phase="resolve"} > 0.5 or | |
probe_http_duration_seconds{phase="tls"} > 0.5 or | |
probe_http_duration_seconds{phase="transfer"} > 0.5 | |
) | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "实例 阶段 '' 耗时过长" | |
description: "实例 在阶段 '' 的耗时超过0.5秒。当前耗时:秒。" | |
- alert: 站点响应状态码异常 | |
expr: probe_http_status_code <= 199 or probe_http_status_code >= 400 | |
for: 5m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 返回异常状态码" | |
description: "实例 返回的状态码为 ,表明请求可能存在问题。" | |
- alert: 证书即将过期<30 | |
expr: (probe_ssl_earliest_cert_expiry - time()) /86400 < 30 | |
for: 24h | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 的 SSL 证书即将过期" | |
description: "实例 的 SSL 证书将在 天内过期。" | |
- alert: 证书即将过期<7 | |
expr: (probe_ssl_earliest_cert_expiry - time()) /86400 < 7 | |
for: 24h | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 的 SSL 证书即将过期" | |
description: "实例 的 SSL 证书将在 天内过期." | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/blackbox_rules.yml | |
Checking /etc/prometheus/rules/blackbox_rules.yml | |
SUCCESS: 7 rules found | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 9.5 导⼊ Blackbox 图形
1、专⽤于针对 HTTP 的图形,导⼊ ID13659 ;
2、也可以使⽤ ID 为 7587 的图形;
3、以及 ID 为 9965 的图形;
# 十. domain_exporter 域名监控
domain_exporter 主要⽤来监控⽹站域名的过期时间。这对于企业和个⼈都是⽐较重要的,因为域名过期可能会导致⽹站⽆法访问,进⽽影响业务的正常运⾏。因此监控 “域名的过期时间” 就显得⽐较重要了。
domain_exporter 的⼯作逻辑有如下⼏步:
- 1、收集域名信息:通过 WHOIS 协议收集 “target 参数定义的域名” 信息。
- 2、解析域名信息:从收集到的数据中解析出域名的过期时间。
- 3、导出指标:将解析出的域名过期时间等信息格式化为 Prometheus 兼容的格式,⽽后通过 /probe 接⼝输出指标。
# 10.1 安装 domain_exporter
1、访问 domain_exporter 的 github 地址, https://github.com/caarlos0/domain_exporter/releases ,下载 domain_exporter
#1. 下载 domain_exporte | |
[root@prom-node04 ~]# wget https://github.com/caarlos0/domain_exporter/releases/download/v1.23.0/domain_exporter_1.23.0_linux_amd64.tar.gz | |
#2. 加速地址 | |
[root@prom-node04 ~]# wget https://mirror.ghproxy.com/https://github.com/caarlos0/domain_exporter/releases/download/v1.23.0/domain_exporter_1.23.0_linux_amd64.tar.gz | |
#3. 解压 domain_exporter | |
[root@prom-node04 ~]# mkdir /etc/domain_exporter_1.23.0 | |
[root@prom-node04 ~]# tar xf domain_exporter_1.23.0_linux_amd64.tar.gz -C /etc/domain_exporter_1.23.0 | |
[root@prom-node04 ~]# ln -s /etc/domain_exporter_1.23.0/ /etc/domain_exporter | |
#4. 配置 domain_exporter 启动⽂件 | |
[root@prom-node04 domain_exporter]# cat /usr/lib/systemd/system/domain_exporter.service | |
[Unit] | |
Description=domain_exporter | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
ExecStart=/etc/domain_exporter/domain_exporter | |
ExecReload=/bin/kill -HUP $MAINPID | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target | |
#5. 动 domain_exporter | |
[root@prom-node04 ~]# systemctl daemon-reload | |
[root@prom-node04 ~]# systemctl start domain_exporter.service | |
[root@prom-node04 ~]# systemctl enable domain_exporter.service | |
Created symlink from /etc/systemd/system/multi-user.target.wants/domain_exporter.service to /usr/lib/systemd/system/domain_exporter.service. | |
[root@prom-node04 ~]# netstat -lntp|grep 9222 | |
tcp6 0 0 :::9222 :::* LISTEN 1880/domain_exporte |
2、通过 domain_exporter 获取域名过期时间,访问 URL http://localhost:9222/probe?target=oldxu.net 来获取特定域名(如 oldxu.net)的过期时间。
[root@prom-node04 ~]# curl http://localhost:9222/probe?target=hmallleasing.com | |
# HELP domain_expiry_days time in days until the domain expires | |
# TYPE domain_expiry_days gauge | |
domain_expiry_days{domain="hmallleasing.com"} 741 | |
# HELP domain_probe_duration_seconds returns how long the probe took to complete in seconds | |
# TYPE domain_probe_duration_seconds gauge | |
domain_probe_duration_seconds{domain="hmallleasing.com"} 1.036303946 | |
# HELP domain_probe_success whether the probe was successful or not | |
# TYPE domain_probe_success gauge | |
domain_probe_success{domain="hmallleasing.com"} 1 |
# 10.2 配置 Prometheus
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
- job_name: "tomcat" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8080"] | |
- job_name: "jmx_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:12345"] | |
- job_name: "mysqld_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9104"] | |
labels: | |
service: database | |
role: master | |
- targets: ["prom-node04.oldxu.net:9104"] | |
labels: | |
service: database | |
role: slave | |
- job_name: "redis_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9121"] | |
- job_name: 'blackbox_http' | |
metrics_path: /probe # metrics 的 path 这次不是 /metrics,是 /probe | |
params: # 传递参数 | |
module: [http_2xx] # 调哪个模块进探测 | |
static_configs: | |
- targets: ["https://www.xuliangwei.com","http://www.oldxu.net","https://www.baidu.com","http://httpbin.org/status/400","https://httpstat.us/500","https://httpstat.us/502"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_tcp' | |
metrics_path: /probe | |
params: | |
module: [tcp_connect] # 使 tcp_connect 模块 | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:3306","prom-node03.oldxu.net:6379"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_icmp' | |
metrics_path: /probe | |
params: | |
module: [icmp] # 使 icmp 模块 | |
static_configs: | |
- targets: ["prom-node01.oldxu.net","prom-node02.oldxu.net","prom-node03.oldxu.net"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_ssh' | |
metrics_path: /probe | |
params: | |
module: [ssh_banner] # 使⽤ ssh_banner 模块 | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:22","prom-node02.oldxu.net:22","prom-node03.oldxu.net:22"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'domain_exporter' | |
metrics_path: /probe # metrics 的 path 不是 /metrics,⽽是 /probe | |
static_configs: | |
- targets: ["nf-leasing.com","ixuyong.cn","hmallleasing.com","jd.com"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9222 | |
#. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 10.3 domain 告警规则⽂件
[root@prom-node01 ~]# cat /etc/prometheus/rules/domain_rules.yml | |
groups: | |
- name: domain告警规则文件 | |
rules: | |
- alert: 域名即将过期 <100 | |
expr: domain_expiry_days < 100 | |
for: 5m | |
labels: | |
severity: warning | |
annotations: | |
summary: "域名即将过期 (实例 )" | |
description: "域名 还有少于100天即将过期。当前剩余天数:。" | |
- alert: 域名即将过期<30 | |
expr: domain_expiry_days < 30 | |
for: 5m | |
labels: | |
severity: critical | |
annotations: | |
summary: "域名即将过期 (实例 )" | |
description: "域名 还有少于30天即将过期。当前剩余天数:。" | |
- alert: 域名检测失败 | |
expr: sum(domain_probe_success) by (domain, instance, job) == 0 | |
for: 5m | |
labels: | |
severity: critical | |
annotations: | |
summary: "域名检测失败 (实例 )" | |
description: "域名 在 上的检测失败。当前值:。" | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/domain_rules.yml | |
Checking /etc/prometheus/rules/domain_rules.yml | |
SUCCESS: 3 rules found | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 10.4 导⼊ domain_exporter 图形
查看域名的状态,以及连通性和过期时间,导⼊ ID 13924
# 十一. PushGateway 推送⽹关服务
Pushgateway 允许脚本通过 Push 的⽅式来推送指标数据,但它不会像 Prometheus 那样主动去抓取指标数据。
Pushgateway 作为中间存储,仅负责接收数据,等待 Prometheus Server 进⾏数据抓取,它⾃身并不具备抓取功能。默认情况下,数据保存在内存中,但可以通过 --persistence.file 参数持久化数据⾄⽂件中,同时通过 --persistence.interval=5m 设置数据持久化间隔。
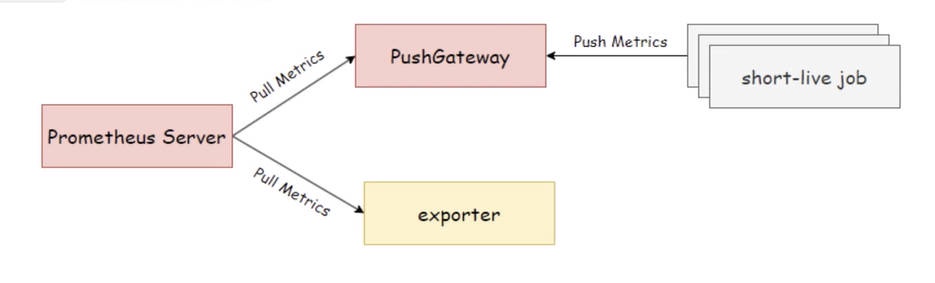
使⽤ Pushgateway 时需要注意以下⼏点:
- 1、若使⽤单个 Pushgateway 接收多个不同实例、或者是脚本推送的数据,它会成为单点。
- 2、Pushgateway 不会⾃动删除已推送的数据,⼀旦数据推送到 Pushgateway, Prometheus 会持续从中抓取数据。
- 3、删除 Pushgateway 中的数据不会影响 Prometheus 已经抓取的历史数据,但之后 Prometheus 将不会有新的数据更新,直到有新的数据被推送到 Pushgateway。
# 11.1 安装 pushGateway
1、访问 PushGateway 官⽹ https://github.com/prometheus/pushgateway ,下载 PushGateway
#1. 下载 Pushgateway | |
[root@prom-node04 ~]# wget https://github.com/prometheus/pushgateway/releases/download/v1.7.0/pushgateway-1.7.0.linux-amd64.tar.gz | |
# 加速地址 | |
[root@prom-node04 ~]# wget https://mirror.ghproxy.com/https://github.com/prometheus/pushgateway/releases/download/v1.7.0/pushgateway-1.7.0.linux-amd64.tar.gz | |
#2. 解压 PushGateway | |
[root@prom-node04 ~]# tar xf pushgateway-1.7.0.linux-amd64.tar.gz -C /etc/ | |
[root@prom-node04 ~]# ln -s /etc/pushgateway-1.7.0.linux-amd64/ /etc/pushgateway | |
#3. 编写 pushgateway 启动⽂件 | |
[root@prom-node04 ~]# cat /usr/lib/systemd/system/pushgateway.service | |
[Unit] | |
Description=pushgateway | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
ExecStart=/etc/pushgateway/pushgateway \ | |
--web.listen-address=:9091 \ | |
--web.telemetry-path=/metrics \ | |
--web.enable-lifecycle | |
ExecReload=/bin/kill -HUP | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target | |
#4. 启动 PushGateway | |
[root@prom-node04 ~]# systemctl daemon-reload | |
[root@prom-node04 ~]# systemctl start pushgateway | |
[root@prom-node04 ~]# systemctl enable pushgateway | |
[root@prom-node04 ~]# netstat -lntp|grep 9091 | |
tcp6 0 0 :::9091 :::* LISTEN 2421/pushgateway |
2、是⽤ Curl 给 pushgateway 推送⼀个 some_metric 的指标,值为 3.14
[root@prom-node04 ~]# echo "some_metric 3.14" | curl --data-binary @- http://localhost:9091/metrics/job/some_job |
3、访问 pushgateway 的 web ⻚⾯,通过 http://IP:9091
# 11.2 配置 Promethues
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
- job_name: "tomcat" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8080"] | |
- job_name: "jmx_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:12345"] | |
- job_name: "mysqld_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9104"] | |
labels: | |
service: database | |
role: master | |
- targets: ["prom-node04.oldxu.net:9104"] | |
labels: | |
service: database | |
role: slave | |
- job_name: "redis_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9121"] | |
- job_name: 'blackbox_http' | |
metrics_path: /probe # metrics 的 path 这次不是 /metrics,是 /probe | |
params: # 传递参数 | |
module: [http_2xx] # 调哪个模块进探测 | |
static_configs: | |
- targets: ["https://www.xuliangwei.com","http://www.oldxu.net","https://www.baidu.com","http://httpbin.org/status/400","https://httpstat.us/500","https://httpstat.us/502"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_tcp' | |
metrics_path: /probe | |
params: | |
module: [tcp_connect] # 使 tcp_connect 模块 | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:3306","prom-node03.oldxu.net:6379"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_icmp' | |
metrics_path: /probe | |
params: | |
module: [icmp] # 使 icmp 模块 | |
static_configs: | |
- targets: ["prom-node01.oldxu.net","prom-node02.oldxu.net","prom-node03.oldxu.net"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_ssh' | |
metrics_path: /probe | |
params: | |
module: [ssh_banner] # 使⽤ ssh_banner 模块 | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:22","prom-node02.oldxu.net:22","prom-node03.oldxu.net:22"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'domain_exporter' | |
metrics_path: /probe # metrics 的 path 不是 /metrics,⽽是 /probe | |
static_configs: | |
- targets: ["nf-leasing.com","hmallleasing.com","jd.com"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9222 | |
- job_name: "pushgateway" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node04.oldxu.net:9091"] | |
#. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 11.3 编写脚本并推送指标
假设我们有⼀个备份脚本,它每天执⾏⼀次并且很快就完成了。但是我们需要知道它是否每次都成功执⾏了,以及每次执⾏花了多少时间。为了捕获这些信息,我们可以在脚本执⾏完成之后,将其成功状态和执⾏时间推送到 PushGateway。之后 Prometheus 就会定期从 PushGateway 中拉取这些数据,以此来监控这个脚本的状态。
[root@prom-node04 ~]# cat pushgateway_backup.sh | |
#!/bin/bash | |
[[ $# -ne 1 ]] && echo "给定一个备份的应用名称" && exit | |
# PushGateway 地址 | |
PUSH_ADDR="prom-node04.oldxu.net" | |
# 应用名称 | |
APP_NAME="$1" | |
# 备份脚本示例 | |
START_TIME=$(date +%s) | |
# 模拟备份任务,随机睡眠时间 1-10 秒 | |
SLEEP_TIME=$((1 + RANDOM % 10)) | |
sleep $SLEEP_TIME | |
# 随机决定备份操作是否成功 | |
if [ $((RANDOM % 10)) -lt 5 ]; then | |
STATUS=1 # 成功 | |
else | |
STATUS=0 # 失败 | |
fi | |
END_TIME=$(date +%s) | |
DURATION=$((END_TIME - START_TIME)) | |
# 推送指标至 PushGateway | |
cat <<EOF | curl --data-binary @- http://$PUSH_ADDR:9091/metrics/job/backup/instance/$APP_NAME | |
# HELP backup_duration_seconds The duration of the last backup in seconds. | |
# TYPE backup_duration_seconds gauge | |
backup_duration_seconds{application="$APP_NAME"} $DURATION | |
# HELP backup_success Last backup was success(1) or ERROR(0). | |
# TYPE backup_success gauge | |
backup_success{application="$APP_NAME"} $STATUS | |
EOF |
1、执⾏脚本,需要传递⼀个应⽤的名称
[root@prom-node04 ~]# sh pushgateway_backup.sh shop |
2、在 Prometheus UI 中检查 backup_duration_seconds 和 backup_success 指标
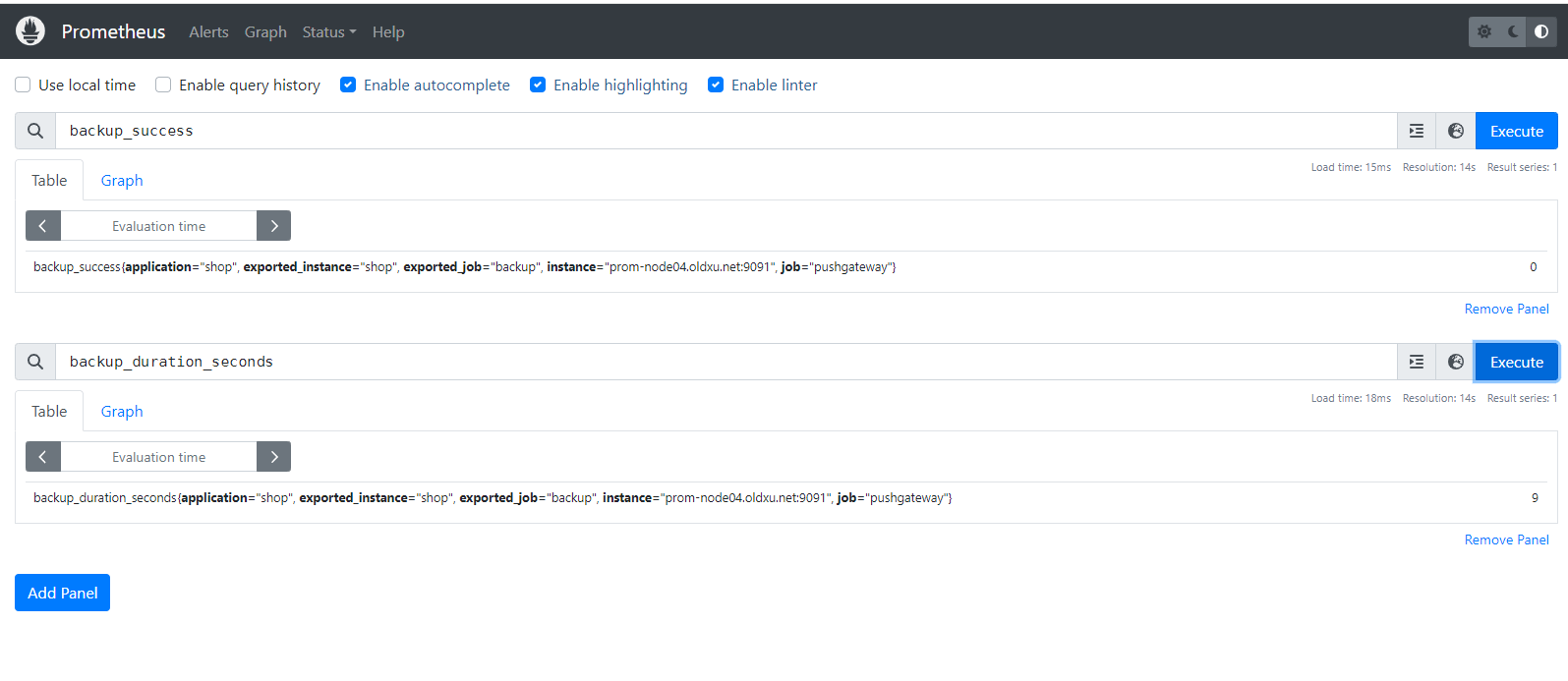
# 11.4 配置告警规则⽂件
[root@prom-node01 ~]# cat /etc/prometheus/rules/backup_rules.yml | |
groups: | |
- name: backup_alerts | |
rules: | |
# 警告:在备份成功情况在,如果备份任务耗时超过了 9 秒则触发告警 | |
- alert: 备份告警超时 | |
expr: backup_duration_seconds > 6 and backup_success == 1 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "备份任务耗时过长" | |
description: " 应⽤备份任务成功完成,但耗时超过了6秒。实际耗时: 秒。" | |
# 严重警告:备份任务失败,并且不考虑耗时 | |
- alert: 备份任务失败 | |
expr: backup_success == 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "备份失败" | |
description: " 任务中 应用备份失败。" | |
#2. 检查告警规则语法 | |
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/backup_rules.yml | |
Checking /etc/prometheus/rules/backup_rules.yml | |
SUCCESS: 2 rules found | |
#3. 重载 Prometheus | |
[root@prom-node01 ~]# curl -v -X POST http://localhost:9090/-/reload |
# 11.5 清理 pushGateway
清理 PushGateway 中的数据,有两种⽅式,⼀种⼿动清理、⼀种⾃动清理
1、⼿动清理:访问 PushGateway 的 web 界⾯,找到你要清理的指标,然后点击 “Delete Group” 进⾏删除。
2、⾃动清理:设置⼀个定时任务(如 cron job),定期通过 API 调⽤删除过时的指标。
[root@prom-node04 ~]# cat clear_pushgateway_job.sh | |
#!/bin/bash | |
[[ $# -ne 2 ]] && echo "给定要清理的 [Job_name名称]和 [instance名称]" && exit | |
JOB_NAME=$1 | |
INSTANCE_NAME=$2 | |
# 清理特定 job 名称的指标 | |
curl -X DELETE http://prom-node04.oldxu.net:9091/metrics/job/${JOB_NAME}/instance/${INSTANCE_NAME} | |
# 设定 crontab | |
[root@prom-node04 ~]# crontab -e | |
59 23 * * * /bin/bash /root/clear_pushgateway_job.sh backup shop |