
# Prometheus 告警服务
# 一。什么是 AleartManager
# 1.1 什么是 AleartManager
由于 Prometheus 本身⽆法实现告警,因此需要借助 AlertManager 来实现告警的推送。
Prometheus Server 会对已经设定好的 “告警规则” 进⾏定期评估,当检测到问题时,会⽣成相应的告警通知并发送给 AlertManager。AlertManager 则会根据告警消息所携带的 “标签” 和事先配置的 “路由规则(Routes)”,将告警消息分发⾄不同的接收器 / 接收⼈(receivers)。例如,带有 "system" 标签的告警会通过 Email 发送给运维团队,⽽带有 "database" 标签的告警则通过 WeChat 发给数据库团队。
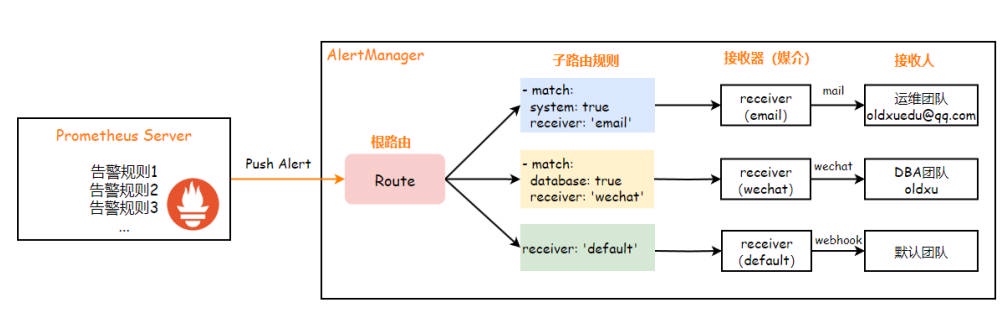
prometheus---> 评估规则 ---> 持续满⾜触发条件 ---> 触发告警 --->alertmanager---> 根据路由规则匹配标签 --> 通过不同的媒介 ---> 发送不
同的接收⼈(邮件 | 钉钉 | 微信)。
# 1.2 AleartManager 特性
除了基本的告警通知能⼒外,Altermanager 还⽀持对告警进⾏去重、分组、抑制、 静默和路由等功能:
1、去重:prometheus ⼀条报警发送给多个 AlertManager,AlertManager 会对其进⾏去重并发送。
2、分组(Group):将相似告警合并为单个告警发送,在系统因⼤⾯积故障⽽触发告警潮时,分组机制能避免⽤户被⼤量的告警淹没,进⽽导致关键信息的隐没;
例如:我们可能会使⽤ Prometheus 中的 up 指标来检测每台主机的存活状态。如果某台主机不可达,Prometheus 将会为这台主机⽣成⼀个 InstanceDown 的告警。如果多台主机同时出现不存活的问题,那么就会收到⼀连串的告警邮件,每个告警信息都是⼀个独⽴的事件,这样就⽐较难以区分哪些告警是最紧急的。⽽ Alertmanager 的分组功能它允许你定义合并的规则,例如将 alertname 相同的告警合并在⼀起,发送单⼀的通知。这意味着,如果多台主机同时出现不存活的情况,Alertmanager 会将消息合并为⼀个通知发送出去,其中包含受影响的所有主机的信息,⽽不是通知每个主机的故障。
3、路由(route):它负责决定告警的分发逻辑。它通过检查告警的属性,使⽤ “预定义的匹配规则” 来判断告警的类别,然后根据这些规则把告警发送到合适的接收器
例如:我们使⽤ Prometheus 监控了很多服务,包括数据库、web、⽀付系统等。⽽不同类型的服务故障需要通知到不同的团队,这样问题才能得到快速的解决。像数据库问题需要通知 DBA 团队,⽽应⽤层⾯的问题需要通知给运维团队。在 Alertmanager 中,可以为不同类型的告警,设置不同的接收器(receivers),Alertmanager 路由规则会将告警发送到对应的接收器,确保消息能正确的通知到不同的团队。
4、静默(Silence):是指在⼀个特定的时间窗⼝内,即便接收到告警通知,Alertmanager 也不会真正向⽤户发送告警信息
例如:在系统维护或升级过程中,通常会触发⼤量的告警。这些告警往往是维护系统的过程中引起的,⽽⾮真正出现了故障。如果我们不对告警通知进⾏调整,将会收到⼤量的告警信息,造成不必要的⼲扰。为了应对这种情况,在维护期间,我们可以在 Alertmanager 中设置静默(silence)规则。这些规则能够禁⽌对外发送告警通知。等到维护⼯作完成后,我们再取消静默规则,恢复正常的告警通知流程。这样可以保证告警系统的有效性,同时避免了在维护期间产⽣⼤量不必要的告警信息。
5、抑制(Inhibition):是⼀种告警管理机制,⽤以减少因组件故障导致的连锁告警。当⼀个核⼼组件发⽣故障时,依赖它的其他组件或服务也可能产⽣告警。启⽤抑制功能后,系统将⾃动抑制这些级联的次要告警,从⽽让⽤户将精⼒集中于真正的故障所在。
例如:当⼀台主机宕机,主机之上的所有应⽤也会随之宕机,每个应⽤异常都会单独发送告警,从⽽导致告警数量激增。为避免告警泛滥,我们可以通过告警抑制功能来设置告警规则:在主机宕机的情况下,抑制所有由主机引起的其他应⽤的告警。 仅关注主机本身的告警信息。这样我们就能更快的定位到根本的问题并解决该问题。
6、⾼可⽤(High Availability):AlertManager 可以使⽤ gossip 留⾔协议实现⾼可⽤性;
# 1.3 AlertManager 配置说明
Alertmanager 负责对 Prometheus ⽣成的告警进⾏统⼀处理。常⻅的配置分为以下⼏个主要部分:
- 1、全局配置 (global): 定义了全局通⽤的参数。例如:( SMTP 配置(⽤于邮件通知)、Slack 配置(⽤于 Slack 通知)、以及其他第三⽅服务的配置)
- 2、模板 (templates): 定义告警通知时使⽤的模板。例如:(HTML 模板、邮件模板)
- 3、告警路由 (route): 根据告警的标签进⾏匹配,确定分组逻辑,以及告警通知给谁。
- 4、接收⼈ (receivers): 接收⼈可以是邮箱、微信、Slack、Webhook 等。配合告警路由使⽤,确保告警通知到达正确的⽬的地。
- 5、抑制规则 (inhibit_rules): 通过设置抑制规则来减少不必要的告警,避免告警泛滥。
global: | |
# 已经触发了告警的消息,在多⻓时间内没有收到该告警的消息,则会⾃动将该告警标记为已解决。默认值是 5 分钟。 | |
[ resolve_timeout: <duration> | default = 5m ] | |
# 邮件配置 | |
[ smtp_from: <tmpl_string> ] | |
[ smtp_smarthost: <string> ] | |
[ smtp_hello: <string> | default = "localhost" ] | |
[ smtp_auth_username: <string> ] | |
[ smtp_auth_password: <secret> ] | |
[ smtp_auth_identity: <string> ] | |
[ smtp_auth_secret: <secret> ] | |
[ smtp_require_tls: <bool> | default = true ] | |
# 其他全局配置... | |
[ wechat_api_url: <string> | default = "https://qyapi.weixin.qq.com/cgi␂bin/" ] | |
[ wechat_api_secret: <secret> ] | |
[ wechat_api_corp_id: <string> ] | |
# 模板配置 | |
templates: | |
# 路径到告警模板⽂件 | |
[ - <filepath> ... ] | |
# 告警路由 | |
route: | |
# 告警的⼦路由配置 | |
<route> | |
# 定义接收告警的接收⼈或服务 | |
receivers: | |
- <receiver> ... | |
inhibit_rules: | |
# 抑制规则,⽤于减少告警噪声 | |
[ - <inhibit_rule> ... ] |
# 二. AleartManager 部署
# 2.1 AleartManager 安装
1、访问 AlertManager 的 github,获取 AlertManager 的下载地址, https://github.com/prometheus/alertmanager/releases
#1. 下载 AlertManager | |
[root@prom-node01 ~]# wget https://github.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz | |
# 加速地址 | |
[root@prom-node01 ~]# wget https://mirror.ghproxy.com/https://github.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz | |
#2. 解压 AlertManager | |
[root@prom-node01 ~]# tar xf alertmanager-0.26.0.linux-amd64.tar.gz -C /etc/ | |
[root@prom-node01 ~]# ln -s /etc/alertmanager-0.26.0.linux-amd64/ /etc/alertmanager | |
#3. 查看 AlertManager ⽬录结构 | |
[root@prom-node01 ~]# ll /etc/alertmanager/ | |
total 62504 | |
-rwxr-xr-x 1 3434 3434 35410965 Aug 24 2023 alertmanager | |
-rw-r--r-- 1 3434 3434 356 Aug 24 2023 alertmanager.yml | |
-rwxr-xr-x 1 3434 3434 28566971 Aug 24 2023 amtool | |
-rw-r--r-- 1 3434 3434 11357 Aug 24 2023 LICENSE | |
-rw-r--r-- 1 3434 3434 457 Aug 24 2023 NOTICE |
# 2.2 AleartManager 配置
1、定义的配置⽂件,设定发件⼈的邮箱,以及路由匹配规则,和接收⼈ (group_wait 与 group_interval 区别)
[root@prom-node01 ~]# cp /etc/alertmanager/alertmanager.yml /etc/alertmanager/alertmanager.yml.bak | |
[root@prom-node01 ~]# cat /etc/alertmanager/alertmanager.yml | |
global: | |
resolve_timeout: 2h # 已经触发了告警的消息,在多长时间内没有收到该告警的消息,则会自动将该告警标记为已解决。 | |
smtp_smarthost: 'smtp.qq.com:587' | |
smtp_from: '373370405@qq.com' # 发件人邮件 | |
smtp_auth_username: '373370405@qq.com' # 发件人用户名 | |
smtp_auth_password: '******' # 发件人密码 [授权码] | |
smtp_hello: 'qq.com' | |
smtp_require_tls: true | |
# 所有报警信息进入后的根路由,用来设置报警的分发策略 | |
route: | |
group_by: ['alertname'] #告警信息会根据告警名称分组,同名的告警消息会被归到一组,然后一起发送。(一个学校的一起搭⻋回家) | |
group_wait: 30s #当一组新告警产生时,系统会等待 30 秒,以便把这段时间内相同组的其他告警一起合并发送。(发车时间,保不齐在等待的 30s 内会有新的同校学生上车) | |
group_interval: 1m #已经发送了一个分组的告警通知之后,即使又有新的相同分组的告警到来,也需要等待至少 1 分钟后才会发送该分组的告警通知。(类似于发车间隔,没赶上就得等) | |
repeat_interval: 5m #如果同一个组中的报警信息已经发送成功了,下一次这个组发送告警的时间间隔(重复发送相同告警的时间间隔) | |
receiver: default #默认的 receiver:如果一个报警没有被一个 route 匹配,则发送给默认的接收器 | |
receivers: | |
- name: 'default' | |
email_configs: | |
- to: '373370405@qq.com' | |
send_resolved: true # 接受告警恢复的通知 |
2、检查 AlertManager 的配置⽂件是否正确
[root@prom-node01 ~]# /etc/alertmanager/amtool check-config /etc/alertmanager/alertmanager.yml | |
Checking '/etc/alertmanager/alertmanager.yml' SUCCESS | |
Found: | |
- global config | |
- route | |
- 0 inhibit rules | |
- 1 receivers | |
- 0 templates |
# 2.3 AlertManager 启动
1、配置 system 管理 alertmanager 启动和停⽌
[root@prom-node01 ~]# cat /usr/lib/systemd/system/alertmanager.service | |
[Unit] | |
Description=alertmanager | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
ExecStart=/etc/alertmanager/alertmanager \ | |
--web.listen-address=:9093 \ | |
--config.file=/etc/alertmanager/alertmanager.yml \ | |
--storage.path=/etc/alertmanager/data \ | |
--data.retention=120h | |
ExecReload=/bin/kill -HUP | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target | |
[root@prom-node01 ~]# systemctl daemon-reload | |
[root@prom-node01 ~]# systemctl enable alertmanager && systemctl start alertmanager | |
[root@prom-node01 ~]# netstat -lntp|grep 9093 | |
tcp6 0 0 :::9093 :::* LISTEN 2648/alertmanager |
2、访问 alertmanager,通过 http://IP:9093 访问
# 2.4 AlertManager 测试
1、使⽤ Go 编写的告警测试⼯具来验证告警合并功能。发送具有相同 alertname 名称,但不同内容的告警,以验证 AlertManager 是否会将它们合并成⼀个组。
# 下载告警程序 | |
[root@prom-node01 ~]# wget http://file.oldxu.net/prometheus/Alert/alert_test_oldxu | |
[root@prom-node01 ~]# chmod +x alert_test_oldxu | |
[root@prom-node03 ~]# docker run -it --rm -v `pwd`:/app/program ubuntu | |
root@4c83c1816d0b:/# cd /app/program/ | |
# alertname=nodedown(--alertURL 指定 alertmanager 服务器所在的地址、端⼝以及接⼝) | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=nodedown,instance=prom-node01.oldxu.net,severity=critical,job=node_exporter" | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=nodedown,instance=prom-node02.oldxu.net,severity=critical,job=node_exporter" | |
# alertname=cpuhigh | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=cpuhigh,instance=prom-node01.oldxu.net,severity=critical,job=node_exporter" | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=cpuhigh,instance=prom-node02.oldxu.net,severity=critical,job=node_exporter" |
2、验证结果,会发现 AlertManager 是根据 group_by 中定义的 alertname 将告警信息进⾏分组,这样能够有效避免了消息重复通知。
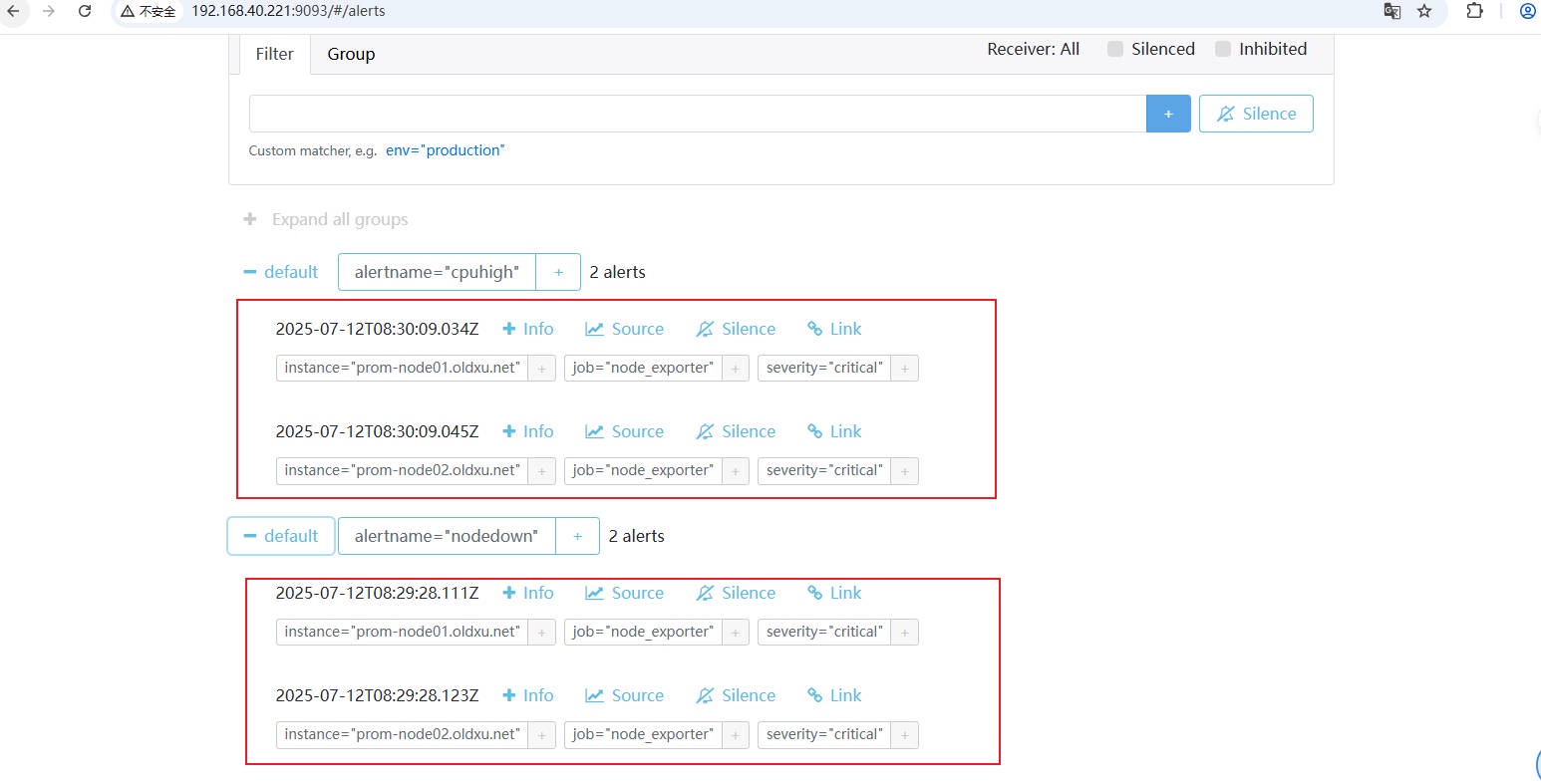
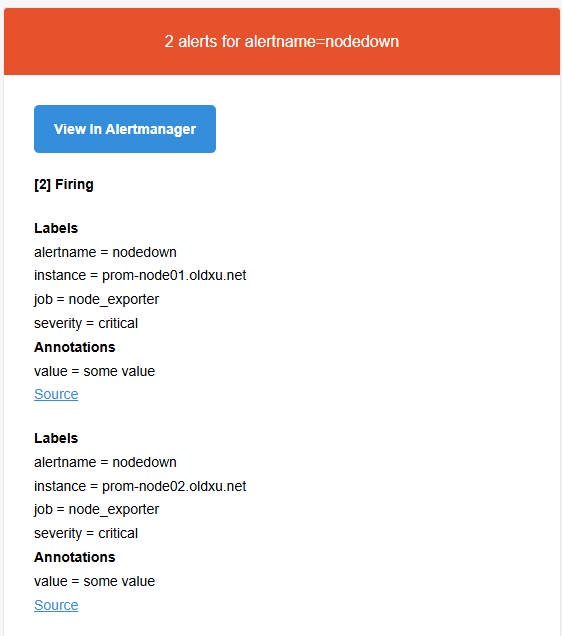
3、登录邮件查看告警信息,理想的结果是收到两封电⼦邮件通知,每封包含两条关联告警,⽽⾮四封单独的邮件。
# 三. Prometheus 对接 AleartManager
# 3.1 配置 Prom 对接 AleartManager
1、编辑 prometheus.yml ⽂件,然后将告警接⼊⾄ AlertManager 组件;
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
# Alertmanager 配置 | |
alerting: | |
alertmanagers: | |
- static_configs: | |
- targets: ["prom-node01.oldxu.net:9093"] |
2、由于 AlertManager 也对外提供了 Metrics 接⼝,我们可以直接将 AlertManager 纳⼊监控中来;
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
# Alertmanager 配置 | |
alerting: | |
alertmanagers: | |
- static_configs: | |
- targets: ["prom-node01.oldxu.net:9093"] | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] | |
- job_name: "node_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9100","prom-node02.oldxu.net:9100","prom-node03.oldxu.net:9100"] | |
- job_name: "weather_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7001"] | |
- job_name: "webserver" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:7002"] | |
- job_name: "rabbitmq" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node02.oldxu.net:15692"] | |
- job_name: "nginx" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9113"] | |
- job_name: "tomcat" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:8080"] | |
- job_name: "jmx_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:12345"] | |
- job_name: "mysqld_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9104"] | |
labels: | |
service: database | |
role: master | |
- targets: ["prom-node04.oldxu.net:9104"] | |
labels: | |
service: database | |
role: slave | |
- job_name: "redis_exporter" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:9121"] | |
- job_name: 'blackbox_http' | |
metrics_path: /probe # metrics 的 path 这次不是 /metrics,是 /probe | |
params: # 传递参数 | |
module: [http_2xx] # 调哪个模块进探测 | |
static_configs: | |
- targets: ["https://www.xuliangwei.com","http://www.oldxu.net","https://www.baidu.com","http://httpbin.org/status/400","https://httpstat.us/500","https://httpstat.us/502"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_tcp' | |
metrics_path: /probe | |
params: | |
module: [tcp_connect] # 使 tcp_connect 模块 | |
static_configs: | |
- targets: ["prom-node03.oldxu.net:3306","prom-node03.oldxu.net:6379"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_icmp' | |
metrics_path: /probe | |
params: | |
module: [icmp] # 使 icmp 模块 | |
static_configs: | |
- targets: ["prom-node01.oldxu.net","prom-node02.oldxu.net","prom-node03.oldxu.net"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'blackbox_ssh' | |
metrics_path: /probe | |
params: | |
module: [ssh_banner] # 使⽤ ssh_banner 模块 | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:22","prom-node02.oldxu.net:22","prom-node03.oldxu.net:22"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9115 | |
- job_name: 'domain_exporter' | |
metrics_path: /probe # metrics 的 path 不是 /metrics,⽽是 /probe | |
static_configs: | |
- targets: ["nf-leasing.com","hmallleasing.com","jd.com"] | |
relabel_configs: | |
- source_labels: [__address__] | |
target_label: __param_target | |
- source_labels: [__param_target] | |
target_label: instance | |
- target_label: __address__ | |
replacement: prom-node04.oldxu.net:9222 | |
- job_name: "pushgateway" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node04.oldxu.net:9091"] | |
- job_name: "alertmanager" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:9093"] |
3、重新加载 Prometheus 服务
[root@prom-node01 ~]# curl -X POST http://localhost:9090/-/reload |
# 3.2 配置 Prometheus 告警规则
1、在 Prometheus 服务器上编辑⼀个测试的告警规则
[root@prom-node01 ~]# cat /etc/prometheus/rules/node_rules.yml | |
groups: | |
- name: 节点告警规则 | |
rules: | |
- alert: 节点处于Down状态 | |
expr: up == 0 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "节点处于Down状态,实例:" | |
description: " 节点已关闭" | |
- alert: 节点CPU使率超过80% | |
expr: ( 1 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance,job) ) * 100 > 80 | |
for: 1m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机CPU利率过高,实例:, 任务:" | |
description: "该实例的CPU利用率低于20%,当前利用率:%。可能存在CPU资源浪费情况。" | |
- alert: CPU饱和度过高 | |
expr: sum(node_load1) by (instance,job) / (count(node_cpu_seconds_total{mode="idle"}) by (instance,job) * 2) * 100 > 80 | |
for: 2m | |
labels: | |
severity: critical | |
annotations: | |
summary: "CPU饱和度过高,实例:, 任务:" | |
description: "该实例的1分钟平均CPU负载超过了核心数的两倍,已经持续2分钟,当前CPU饱和度:%。需要立即检查系统负载情况。" | |
- alert: 主机内存不足 | |
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80 | |
for: 2m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机内存使用率较高, 实例:, 任务:" | |
description: "该实例的内存使用率持续2分钟高于80%,当前利用率:%" | |
- alert: 内存饱和度高 | |
expr: ( 1 - node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes) * 100 > 10 | |
for: 2m | |
labels: | |
severity: warning | |
annotations: | |
summary: "主机内存内存饱和度高, 实例:, 任务:" | |
description: "SWAP内存使用率已连续2分钟超过10%,表明内存饱和度过高,当前SWAP使用率为:%。" | |
- alert: 磁盘空间告急 | |
expr: ( node_filesystem_size_bytes{device!="tmpfs"} - node_filesystem_avail_bytes{device!="tmpfs"} ) / node_filesystem_size_bytes{device!="tmpfs"} * 100 > 70 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘 分区空间不足" | |
description: "实例 磁盘 分区空间使用率已超过 70%,当前使用率为 %,请及时处理。" | |
- alert: 磁盘Inode空间告急 | |
expr: (node_filesystem_files{device!="tmpfs"} - node_filesystem_files_free{device!="tmpfs"} ) / node_filesystem_files{device!="tmpfs"} * 100 > 70 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘 分区Inode空间不足" | |
description: "实例 磁盘 分区的Inode空间使用率已超过 70%,,当前使用率为 %,请及时处理。" | |
- alert: 磁盘IOPS写入较高 | |
#expr: sum(rate(node_disk_writes_completed_total[1m])) by (instance,job) / 120 * 100 >60 | |
#round 函数可以对值进行四舍五入,磁盘最大 IOPS 为 120 次 /s | |
expr: round(max(irate(node_disk_writes_completed_total[1m])) by (instance,job) / 120 * 100) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 IOPS每秒写入次数超过120次/s" | |
description: | |
当前磁盘IOPS写入饱和度是 <!--swig25-->% | |
当前磁盘IOPS每秒写入最大 <!--swig26--> 次/s | |
- alert: 磁盘IOPS读取较高 | |
expr: round(max(irate(node_disk_reads_completed_total[1m])) by (instance,job) / 120 * 100) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 IOPS每秒读取次数超过120次/s" | |
description: | |
当前磁盘IOPS读取饱和度是 <!--swig28-->% | |
当前磁盘IOPS每秒读取最⼤ <!--swig29--> 次/s | |
- alert: 磁盘IO写入吞吐较高 | |
expr: round(max(rate(node_disk_written_bytes_total[1m])) by (instance,job) / 1024 /1024 / 30 * 100) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘IO写入每秒超过最高30MB/s" | |
description: | |
当前磁盘IO写入吞吐量的饱和度是 <!--swig31-->%。 | |
当前磁盘IO写入吞吐量每秒最大是 <!--swig32-->MB/s | |
- alert: 磁盘IO读取吞吐较高 | |
expr: round(max(rate(node_disk_read_bytes_total[1m])) by (instance,job) / 1024 /1024 /30 * 100 ) > 60 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 磁盘IO读取每秒超过最大30MB/s" | |
description: | |
当前磁盘IO读取吞吐量的饱和度是 <!--swig34-->%。 | |
当前磁盘IO读取吞吐量每秒最大是 <!--swig35-->MB/s | |
- alert: 网络下载带宽异常 | |
expr: max(irate(node_network_receive_bytes_total[1m]) * 8 / 1024 / 1024) by (instance,job,device) / 50 * 100 >= 80 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 的 接口下载流量已经超过公司实际50Mbps" | |
description: | |
当前下载带宽已经达到 <!--swig38--> Mbps/s | |
当前下载带宽使用率在 <!--swig39-->% | |
- alert: 网络上传带宽异常 | |
expr: max(irate(node_network_transmit_bytes_total[1m]) * 8 / 1024 / 1024) by (instance,job,device) / 50 * 100 >= 80 | |
for: 1m | |
labels: | |
severity: critical | |
annotations: | |
summary: "实例 的 接口上传流量已经超过公司实际50Mbps" | |
description: | |
当前上传带宽已经达到 <!--swig42--> Mbps/s | |
当前上传带宽使用率在 <!--swig43-->% |
# 3.3 配置 Prometheus 加载规则
为了能够让 Prometheus 能够定期评估告警规则,我们需要在 Prometheus 全局配置⽂件中通过 rule_files 指定告警规则⽂件的路径,⽽后 Prometheus 会定期评估这些告警规则, 当规则条件满⾜时,会向外部发送通知。
1、配置 Prometheus 加载告警规则⽂件
[root@prom-node01 ~]# cat /etc/prometheus/prometheus.yml | |
# 全局段定义 | |
global: | |
scrape_interval: 15s # 设置 Prometheus 抓取指标数据的间隔,默认为 15 秒。 | |
# Alertmanager 配置 | |
alerting: | |
alertmanagers: | |
- static_configs: | |
- targets: ["prom-node01.oldxu.net:9093"] | |
rule_files: | |
- "/etc/prometheus/rules/*.yml" | |
# 抓取指定的目标 | |
scrape_configs: | |
- job_name: "prometheus" # 定义一个抓取任务,名为 'prometheus'。 | |
metrics_path: "/metrics" # 指定 Prometheus 从监控目标暴露的 HTTP 端点路径抓取指标,默认为 '/metrics'。 | |
static_configs: # 配置静态目标地址,Prometheus 将定期从如下这些地址抓取指标。 | |
- targets: ["prom-node01.oldxu.net:9090"] | |
- job_name: "grafana" | |
metrics_path: "/metrics" | |
static_configs: | |
- targets: ["prom-node01.oldxu.net:3000"] |
2、检查 Prometheus 语法
[root@prom-node01 ~]# /etc/prometheus/promtool check rules /etc/prometheus/rules/node_rules.yml | |
Checking /etc/prometheus/rules/node_rules.yml | |
SUCCESS: 13 rules found |
3、重启 Prometheus 服务
curl -X POST http://localhost:9090/-/reload |
# 3.4 触发规则并验证告警通知
1、停⽌ node2 和 node03 的 node_exporter 服务,那么就会触发告警
[root@prom-node02 ~]# systemctl stop node_exporter.service | |
[root@prom-node03 ~]# systemctl stop node_exporter.service |
2、检查 Prometheus 的 Alert ⻚⾯的状态是否处于 Firing
3、检查 AlertManager 是否收到了告警
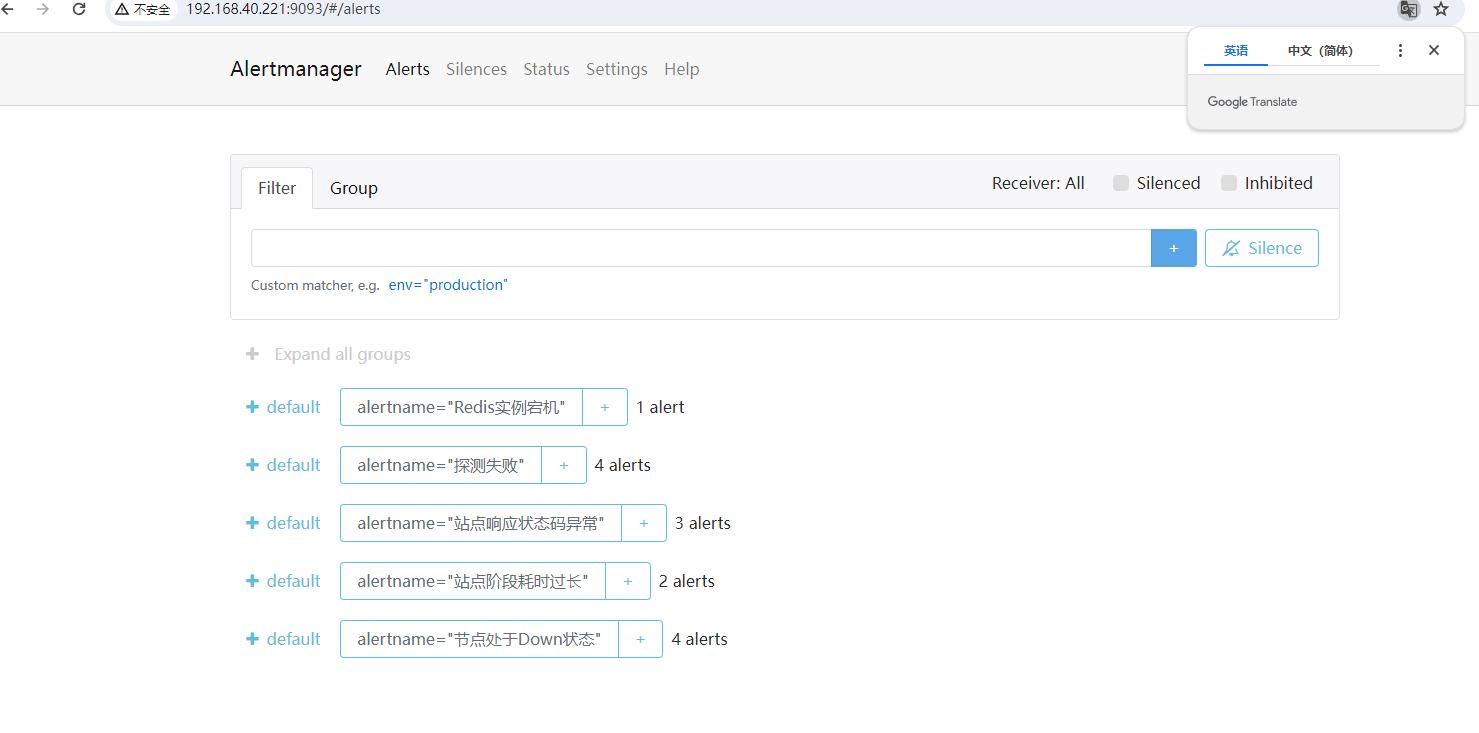
4、检查邮件是否能看到告警的信息,因为两条告警的 alertname 是一致的,因此它们会合并为一条消息发送出来。
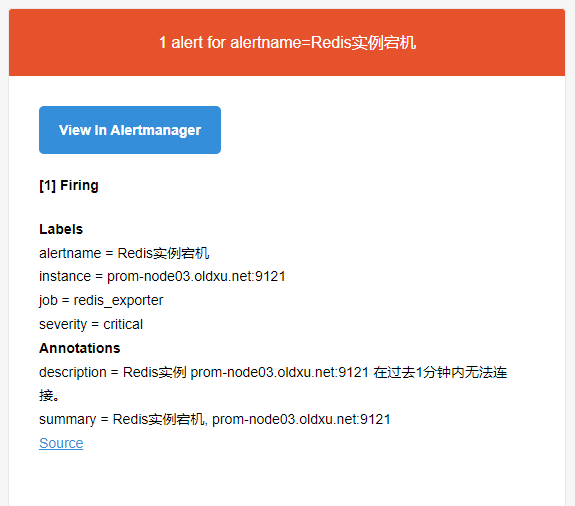
# 3.5 ⾃定义邮件告警模板
1、定义告警的通知模板和恢复模板
[root@prom-node01 ~]# mkdir /etc/alertmanager/template | |
[root@prom-node01 ~]# cat /etc/alertmanager/template/email.tmpl | |
<!--swig44--> | |
<!--swig45--> | |
<!--swig46--> | |
<h2 style="color: red;">@告警通知</h2> | |
告警程序: AlertManager <br> | |
告警级别: <!--swig47--> <br> | |
告警类型: <!--swig48--> <br> | |
故障主机: <!--swig49--> <br> | |
告警主题: <!--swig50--> <br> | |
告警详情: <!--swig51--> <br> | |
触发时间: <!--swig52--> <br> | |
<!--swig53--><!--swig54--> | |
<!--swig55--> | |
<!--swig56--> | |
<h2 style="color: green;">@告警恢复</h2> | |
告警程序: AlertManager <br> | |
告警级别: <!--swig57--> <br> | |
告警类型: <!--swig58--> <br> | |
告警主机: <!--swig59--> <br> | |
告警主题: <!--swig60--> <br> | |
告警详情: <!--swig61--> <br> | |
触发时间: <!--swig62--> <br> | |
恢复时间: <!--swig63--> <br> | |
<!--swig64--><!--swig65--> | |
<!--swig66--> |
2、配置 AlertManager,应用该模板
[root@prom-node01 ~]# cat /etc/alertmanager/alertmanager.yml
global:
resolve_timeout: 2h # 已经触发了告警的消息,在多长时间内没有收到该告警的消息,则会自动将该告警标记为已解决。
smtp_smarthost: 'smtp.qq.com:587'
smtp_from: '373370405@qq.com' # 发件人邮件
smtp_auth_username: '373370405@qq.com' # 发件人用户名
smtp_auth_password: '******' # 发件人密码[授权码]
smtp_hello: 'qq.com'
smtp_require_tls: true
# 加载模板文件
templates:
- '/etc/alertmanager/template/email.tmpl' # 模板文件的实际路径
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
group_by: ['alertname'] #告警信息会根据告警名称分组,同名的告警消息会被归到一组,然后一起发送。(一个学校的一起搭⻋回家)
group_wait: 30s #当一组新告警产生时,系统会等待30秒,以便把这段时间内相同组的其他告警一起合并发送。(发车时间,保不齐在等待的30s内会有新的同校学生上车)
group_interval: 1m #已经发送了一个分组的告警通知之后,即使又有新的相同分组的告警到来,也需要等待至少1分钟后才会发送该分组的告警通知。(类似于发车间隔,没赶上就得等)
repeat_interval: 5m #如果同一个组中的报警信息已经发送成功了,下一次这个组发送告警的时间间隔(重复发送相同告警的时间间隔)
receiver: default #默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receivers:
- name: 'default'
email_configs:
- to: '373370405@qq.com'
send_resolved: true # 接受告警恢复的通知
html: '{{ template "email.html" . }}' # 发送邮件内容,调用该模板进行渲染
3、检查 AlertManager 的配置文件是否正确
[root@prom-node01 ~]# /etc/alertmanager/amtool check-config /etc/alertmanager/alertmanager.yml | |
Checking '/etc/alertmanager/alertmanager.yml' SUCCESS | |
Found: | |
- global config | |
- route | |
- 0 inhibit rules | |
- 1 receivers | |
- 1 templates | |
SUCCESS |
4、重新加载 AlertManager
[root@prom-node01 ~]# curl -X POST http://localhost:9093/-/reload |
5、触发告警,验证告警模板是否正常渲染
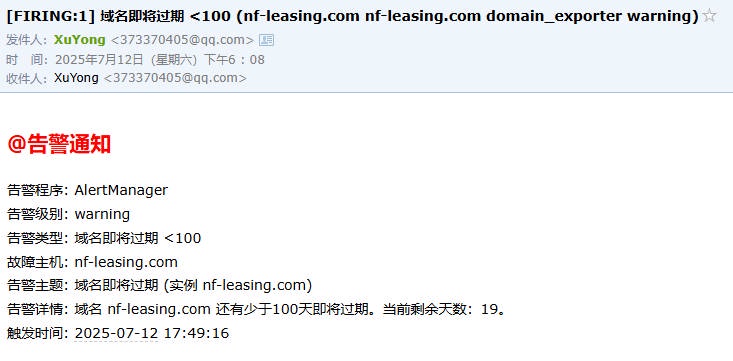
# 四. AlertManager 告警通知⽅式
# 4.1 配置 Alert 对接微信告警
企业微信告警,需要将发送告警的服务器域名添加到⽩名单,同时该服务器必须运⾏在公⽹,因此常规的企业微信告警没办法很好在本地实现。但是我们可以采⽤ webhook ⽅式来实现: Prometheus-->AlertManager--> 自定义 Webhook 程序 --> 企业微信机器⼈ --> 通知给对应的⽤户
- 1. 访问企业微信官⽹, https://work.weixin.qq.com/ ,注册⼀个账户。
- 2. 创建⼀个群聊,并邀请⾄少两名其他成员加⼊,因为企业微信群聊⾄少需要三名成员才能启⽤。
- 3. 在群组聊天中添加⼀个新的机器⼈。
- 4. 记录机器⼈的 Webhook URL (Token)
https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=47ffbdd9-4308-4db0-aa08-f309546cc92d |
1、下载并运⾏ webhook_wechat
[root@prom-node01 ~]# wget http://file.oldxu.net/prometheus/Alert/webhook_wechat_oldxu | |
[root@prom-node01 ~]# mv webhook_wechat_oldxu /usr/local/bin/ | |
[root@prom-node01 ~]# chmod +x /usr/local/bin/webhook_wechat_oldxu |
2、编辑启动脚本⽂件
[root@prom-node01 ~]# cat /usr/lib/systemd/system/webhook_wechat.service | |
[Unit] | |
Description=webhook_wechat | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
ExecStart=/usr/local/bin/webhook_wechat_oldxu --port 5001 | |
ExecReload=/bin/kill -HUP | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target | |
[root@prom-node01 ~]# systemctl daemon-reload | |
[root@prom-node01 ~]# systemctl start webhook_wechat && systemctl enable webhook_wechat | |
[root@prom-node01 ~]# netstat -lntp|grep 5001 | |
tcp6 0 0 :::5001 :::* LISTEN 2576/webhook_wechat |
3、测试 webhook_wechat 能否正确发送消息到企业微信
[root@prom-node01 ~]# curl -X POST http://localhost:5001/alert?token=< 企业微信机器人 token> \ | |
-H "Content-Type: application/json" \ | |
-d '{ | |
"alerts": [ | |
{ | |
"status": "firing", | |
"labels": { | |
"severity": "critical", | |
"alertname": "InstanceDown", | |
"instance": "example1" | |
}, | |
"annotations": { | |
"summary": "Instance example1 down", | |
"description": "The instance example1 is down." | |
}, | |
"startsAt": "2024-12-20T15:04:05Z", | |
"endsAt": "0001-01-01T00:00:00Z" | |
}, | |
{ | |
"status": "resolved", | |
"labels": { | |
"severity": "critical", | |
"alertname": "InstanceDown", | |
"instance": "example1" | |
}, | |
"annotations": { | |
"summary": "Instance example1 is back up", | |
"description": "The instance example1 has recovered." | |
}, | |
"startsAt": "2024-12-20T15:04:05Z", | |
"endsAt": "2024-12-20T16:04:05Z" | |
} | |
] | |
}' |
4、检查企业微信结果

5、配置 AlertManager 对接 webhook_wechat
[root@prom-node01 ~]# cat /etc/alertmanager/alertmanager.yml
global:
resolve_timeout: 2h # 已经触发了告警的消息,在多长时间内没有收到该告警的消息,则会自动将该告警标记为已解决。
smtp_smarthost: 'smtp.qq.com:25'
smtp_from: '373370405@qq.com' # 发件人邮件
smtp_auth_username: '373370405@qq.com' # 发件人用户名
smtp_auth_password: '******' # 发件人密码[授权码]
smtp_hello: 'qq.com'
smtp_require_tls: false
# 加载模板文件
templates:
- '/etc/alertmanager/template/email.tmpl'
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
group_by: ['alertname'] # 告警信息会根据告警名称分组,同名的告警消息会被归到一组,然后一起发送。(一个学校的一起搭⻋回家)
group_wait: 30s # 当一组新告警产生时,系统会等待30秒,以便把这段时间内相同组的其他告警一起合并发送。(发车时间,保不齐在等待的30s内会有新的同校学生上车)
group_interval: 1m # 已经发送了一个分组的告警通知之后,即使又有新的相同分组的告警到来,也需要等待至少1分钟后才会发送该分组的告警通知。(类似于发车间隔,没赶上就得等)
repeat_interval: 5m # 如果同一个组中的报警信息已经发送成功了,下一次这个组发送告警的时间间隔(重复发送相同告警的时间间隔)
receiver: webhook-wechat-ops # 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receivers:
- name: 'webhook-wechat-ops'
webhook_configs:
- url: 'http://prom-node01.oldxu.net:5001/alert?token=47ffbdd9-4308-4db0-aa08-f309546cc92d' #http://<你的服务器地址>:5001/alert?token=<企业微信机器人token>'
- name: 'default'
email_configs:
- to: '373370405@qq.com'
send_resolved: true # 接受告警恢复的通知
html: '{{ template "email.html" . }}' # 发送邮件内容,调用该模板进行渲染
6、检查 AlertManager 的配置⽂件是否正确
[root@prom-node01 ~]# /etc/alertmanager/amtool check-config /etc/alertmanager/alertmanager.yml | |
Checking '/etc/alertmanager/alertmanager.yml' SUCCESS | |
Found: | |
- global config | |
- route | |
- 0 inhibit rules | |
- 1 receivers | |
- 1 templates | |
SUCCESS |
7、重新加载 AlertManager
[root@prom-node01 ~]# curl -X POST http://localhost:9093/-/reload |
8、触发告警,验证是否能通过企业微信收到消息

# 4.2 配置 Alert 对接钉钉告警
钉钉告警可以是⽤ Prometheus-webhook-dingtalk ⼯具,github 地址 https://github.com/timonwong/prometheus-webhook-dingtalk 。但在此处,我们使⽤的是自己开发的 webhook 程序来对接钉钉, Prometheus-->AlertManager--> 自定义 Webhook 程序 --> 钉钉机器人 --> 通知给对应的群组
- 1、访问钉钉开发者后台: https://open-dev.dingtalk.com/
- 2、点击应⽤开发,然后创建机器⼈(使⽤旧版),填写机器⼈名称,然后找到创建的机器⼈(版本管理与发布,点击上线),该机器⼈就可以添加到群组。
- 3、发起群聊(添加两个⽤户),然后创建⼀个普通群,群归属为个⼈。
- 4、紧接着找到对应的群,点击群类型,必须转为 “内部群”,然后在智能群助⼿中添加机器⼈,找到此前在钉钉开发者平台创建的机器⼈添加即可。
- 5、最后点击机器⼈,获取对应的 Token 令牌。
https://oapi.dingtalk.com/robot/send?access_token=906498a49ca8fdd29ae71258393f4ae25aff9ab3d47f007716ebb283f1c8e8db |
# 4.2.1 配置 Alert 对接钉钉告警 1
1、下载并运⾏ webhook_dingding
[root@prom-node01 ~]# wget http://file.oldxu.net/prometheus/Alert/webhook_dingding_oldxu | |
[root@prom-node01 ~]# mv webhook_dingding_oldxu /usr/local/bin/ | |
[root@prom-node01 ~]# chmod +x /usr/local/bin/webhook_dingding_oldxu |
2、编辑启动脚本⽂件
[root@prom-node01 ~]# cat /usr/lib/systemd/system/webhook_dingding.service | |
[Unit] | |
Description=webhook_dingding | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
ExecStart=/usr/local/bin/webhook_dingding_oldxu --port 5002 | |
ExecReload=/bin/kill -HUP | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target | |
[root@prom-node01 ~]# systemctl daemon-reload | |
[root@prom-node01 ~]# systemctl start webhook_dingding && systemctl enable webhook_dingding | |
[root@prom-node01 ~]# netstat -lntp|grep 5002 | |
tcp6 0 0 :::5002 :::* LISTEN 3141/webhook_dingdi |
3、测试 webhook_wechat 能否正确发送消息到钉钉(注意端⼝是 5002)
[root@prom-node01 ~]# curl -X POST http://localhost:5002/alert?token=906498a49ca8fdd29ae71258393f4ae25aff9ab3d47f007716ebb283f1c8e8db \ | |
-H "Content-Type: application/json" \ | |
-d '{ | |
"alerts": [ | |
{ | |
"status": "firing", | |
"labels": { | |
"severity": "critical", | |
"alertname": "InstanceDown", | |
"instance": "example1" | |
}, | |
"annotations": { | |
"summary": "Instance example1 down", | |
"description": "The instance example1 is down." | |
}, | |
"startsAt": "2024-12-20T15:04:05Z", | |
"endsAt": "0001-01-01T00:00:00Z" | |
}, | |
{ | |
"status": "resolved", | |
"labels": { | |
"severity": "critical", | |
"alertname": "InstanceDown", | |
"instance": "example1" | |
}, | |
"annotations": { | |
"summary": "Instance example1 is back up", | |
"description": "The instance example1 has recovered." | |
}, | |
"startsAt": "2024-12-20T15:04:05Z", | |
"endsAt": "2024-12-20T16:04:05Z" | |
} | |
] | |
}' |
4、检查企业微信结果
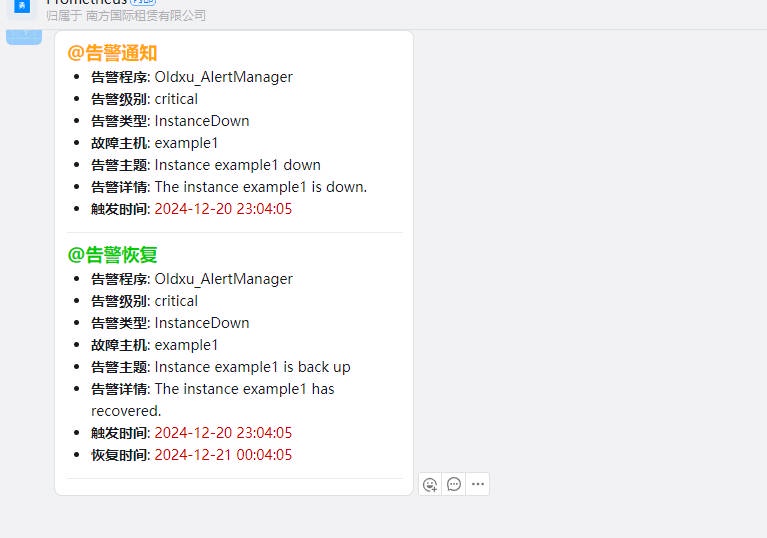
5、配置 AlertManager 对接 webhook_dingding
[root@prom-node01 ~]# cat /etc/alertmanager/alertmanager.yml
global:
resolve_timeout: 2h # 已经触发了告警的消息,在多长时间内没有收到该告警的消息,则会自动将该告警标记为已解决。
smtp_smarthost: 'smtp.qq.com:587'
smtp_from: '373370405@qq.com' # 发件人邮件
smtp_auth_username: '373370405@qq.com' # 发件人用户名
smtp_auth_password: '******' # 发件人密码[授权码]
smtp_hello: 'qq.com'
smtp_require_tls: true
# 加载模板文件
templates:
- '/etc/alertmanager/template/email.tmpl' # 模板文件的实际路径
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
group_by: ['alertname'] #告警信息会根据告警名称分组,同名的告警消息会被归到一组,然后一起发送。(一个学校的一起搭车回家)
group_wait: 30s #当一组新告警产生时,系统会等待30秒,以便把这段时间内相同组的其他告警一起合并发送。(发车时间,保不齐在等待的30s内会有新的同校学生上车)
group_interval: 1m #已经发送了一个分组的告警通知之后,即使又有新的相同分组的告警到来,也需要等待至少1分钟后才会发送该分组的告警通知。(类似于发车间隔,没赶上就得等)
repeat_interval: 5m #如果同一个组中的报警信息已经发送成功了,下一次这个组发送告警的时间间隔(重复发送相同告警的时间间隔)
receiver: webhook-dingding-ops #默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receivers:
- name: 'webhook-dingding-ops'
webhook_configs:
- url: 'http://prom-node01.oldxu.net:5002/alert?token=906498a49ca8fdd29ae71258393f4ae25aff9ab3d47f007716ebb283f1c8e8db'
- name: 'default'
email_configs:
- to: '373370405@qq.com'
send_resolved: true # 接受告警恢复的通知
html: '{{ template "email.html" . }}' # 发送邮件内容,调用该模板进行渲染
6、检查 AlertManager 的配置⽂件是否正确
[root@prom-node01 ~]# /etc/alertmanager/amtool check-config /etc/alertmanager/alertmanager.yml |
7、重新加载 AlertManager
[root@prom-node01 ~]# curl -X POST http://localhost:9093/-/reload |
8、触发告警,验证是否能通过钉钉收到消息
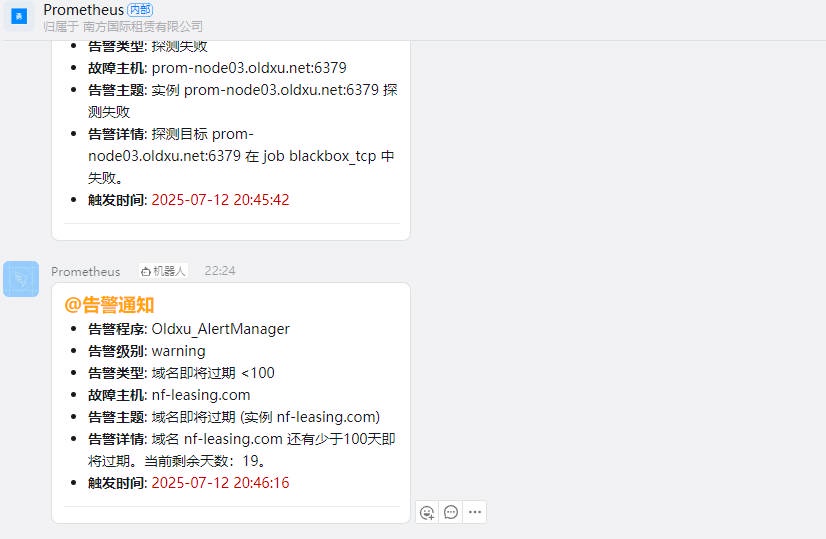
# 4.2.2 配置 Alert 对接钉钉告警 2
参考链接:https://blog.51cto.com/u_13236892/12095979
1、下载 prometheus-webhook-dingtalk
https://github.com/timonwong/prometheus-webhook-dingtalk | |
https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.1.0/prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz |
2、解压安装
[root@prom-node01 ~]# tar -xf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz -C /usr/local/bin/ | |
[root@prom-node01 ~]# ln -s /usr/local/bin/prometheus-webhook-dingtalk-2.1.0.linux-amd64/ /usr/local/bin/webhook-dingtalk |
3、添加告警规则模板
[root@prom-node01 ~]# cat /usr/local/bin/webhook-dingtalk//template.tmpl | |
<!--swig70--> | |
[<!--swig71--><!--swig72-->:<!--swig73--><!--swig74-->] | |
<!--swig75--> | |
<!--swig76--><!--swig77--> | |
--- | |
<!--swig78-->@<!--swig79--><!--swig80--> | |
**告警程序**: AlertManager <br> | |
**告警类型**: <!--swig81--> <br> | |
**告警级别**: <!--swig82--> <br> | |
**告警主机**: <!--swig83--> <br> | |
**告警主题**: <!--swig84--> <br> | |
**告警信息**: <!--swig85--> <br> | |
**告警时间**: <font color='#FF0000'><!--swig86--> </font><br> | |
<!--swig87--><!--swig88--> | |
<!--swig89--><!--swig90--> | |
--- | |
<!--swig91-->@<!--swig92--><!--swig93--> | |
**告警程序**: AlertManager <br> | |
**告警类型**: <!--swig94--> <br> | |
**告警级别**: <!--swig95--> <br> | |
**告警主机**: <!--swig96--> <br> | |
**告警主题**: <!--swig97--> <br> | |
**告警信息**: <!--swig98--> <br> | |
**告警时间**: <font color='#FF0000'><!--swig99--> </font><br> | |
**恢复时间**: <font color='#FF0000'><!--swig100--> </font><br> | |
<!--swig101--><!--swig102--> | |
<!--swig103--> | |
<!--swig104--> | |
<!--swig105--> | |
<!--swig106--> | |
<!--swig107--> | |
**<h2><font color='#FF7F00'>侦测到<!--swig108-->个故障</font></h2>** | |
<!--swig109--> | |
--- | |
<!--swig110--> | |
<!--swig111--> | |
**<h2><font color='#00FF00'>恢复<!--swig112-->个故障</font></h2>** | |
<!--swig113--> | |
<!--swig114--> | |
<!--swig115--> | |
<!--swig116--><!--swig117--><!--swig118--> | |
<!--swig119--><!--swig120--><!--swig121--> | |
<!--swig122--> | |
<!--swig123--> |
4、添加启动配置文件
[root@prom-node01 soft]# cd /usr/local/bin/webhook-dingtalk/
[root@prom-node01 webhook-dingtalk]# cp config.example.yml config.yml
[root@prom-node01 ~]# cat /usr/local/bin/webhook-dingtalk/config.yml
## Request timeout
# timeout: 5s
## Uncomment following line in order to write template from scratch (be careful!)
#no_builtin_template: true
## Customizable templates path
templates:
- /usr/local/bin/webhook-dingtalk/template.tmpl #告警模板
## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'
## Targets, previously was known as "profiles"
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=906498a49ca8fdd29ae71258393f4ae25aff9ab3d47f007716ebb283f1c8e8db #钉钉token
# secret for signature
secret: SEC000000000000000000000
webhook2:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
webhook_legacy:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# Customize template content
message:
# Use legacy template
title: '{{ template "legacy.title" . }}'
text: '{{ template "legacy.content" . }}'
webhook_mention_all:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
mention:
all: true
webhook_mention_users:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
mention:
mobiles: ['156xxxx8827', '189xxxx8325']
5、编辑启动脚本
[root@prom-node01 ~]# cat /usr/lib/systemd/system/webhook.service | |
[Unit] | |
Description=Prometheus-Server | |
After=network.target | |
[Service] | |
ExecStart=/usr/local/bin/webhook-dingtalk/prometheus-webhook-dingtalk \ | |
--config.file=/usr/local/bin/webhook-dingtalk/config.yml | |
ExecReload=/bin/kill -HUP | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target |
6、启动 webhook
[root@prom-node01 ~]# systemctl daemon-reload | |
[root@prom-node01 ~]# systemctl start webhook.service && systemctl enable webhook.service | |
[root@prom-node01 ~]# netstat -lntp|grep 8060 | |
tcp6 0 0 :::8060 :::* LISTEN 3008/prometheus-web |
7、配置 AlertManager 对接 webhook_dingding
[root@prom-node01 ~]# cat /etc/alertmanager/alertmanager.yml
global:
resolve_timeout: 2h # 已经触发了告警的消息,在多长时间内没有收到该告警的消息,则会自动将该告警标记为已解决。
smtp_smarthost: 'smtp.qq.com:587'
smtp_from: '373370405@qq.com' # 发件人邮件
smtp_auth_username: '373370405@qq.com' # 发件人用户名
smtp_auth_password: '******' # 发件人密码[授权码]
smtp_hello: 'qq.com'
smtp_require_tls: true
# 加载模板文件
templates:
- '/etc/alertmanager/template/email.tmpl' # 模板文件的实际路径
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
group_by: ['alertname'] #告警信息会根据告警名称分组,同名的告警消息会被归到一组,然后一起发送。(一个学校的一起搭⻋回家)
group_wait: 30s #当一组新告警产生时,系统会等待30秒,以便把这段时间内相同组的其他告警一起合并发送。(发车时间,保不齐在等待的30s内会有新的同校学生上车)
group_interval: 1m #已经发送了一个分组的告警通知之后,即使又有新的相同分组的告警到来,也需要等待至少1分钟后才会发送该分组的告警通知。(类似于发车间隔,没赶上就得等)
repeat_interval: 5m #如果同一个组中的报警信息已经发送成功了,下一次这个组发送告警的时间间隔(重复发送相同告警的时间间隔)
receiver: webhook-dingding-ops1 #默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receivers:
- name: 'webhook-dingding-ops'
webhook_configs:
- url: 'http://prom-node01.oldxu.net:5002/alert?token=906498a49ca8fdd29ae71258393f4ae25aff9ab3d47f007716ebb283f1c8e8db'
- name: 'webhook-dingding-ops1'
webhook_configs:
- url: 'http://prom-node01.oldxu.net:8060/dingtalk/webhook1/send'
- name: 'default'
email_configs:
- to: '373370405@qq.com'
send_resolved: true # 接受告警恢复的通知
html: '{{ template "email.html" . }}' # 发送邮件内容,调用该模板进行渲染
8、检查 AlertManager 的配置⽂件是否正确
[root@prom-node01 ~]# /etc/alertmanager/amtool check-config /etc/alertmanager/alertmanager.yml | |
Checking '/etc/alertmanager/alertmanager.yml' SUCCESS | |
Found: | |
- global config | |
- route | |
- 0 inhibit rules | |
- 3 receivers | |
- 1 templates | |
SUCCESS |
9、重新加载 AlertManager
curl -X POST http://localhost:9093/-/reload |
10、触发告警,验证是否能通过钉钉收到消息
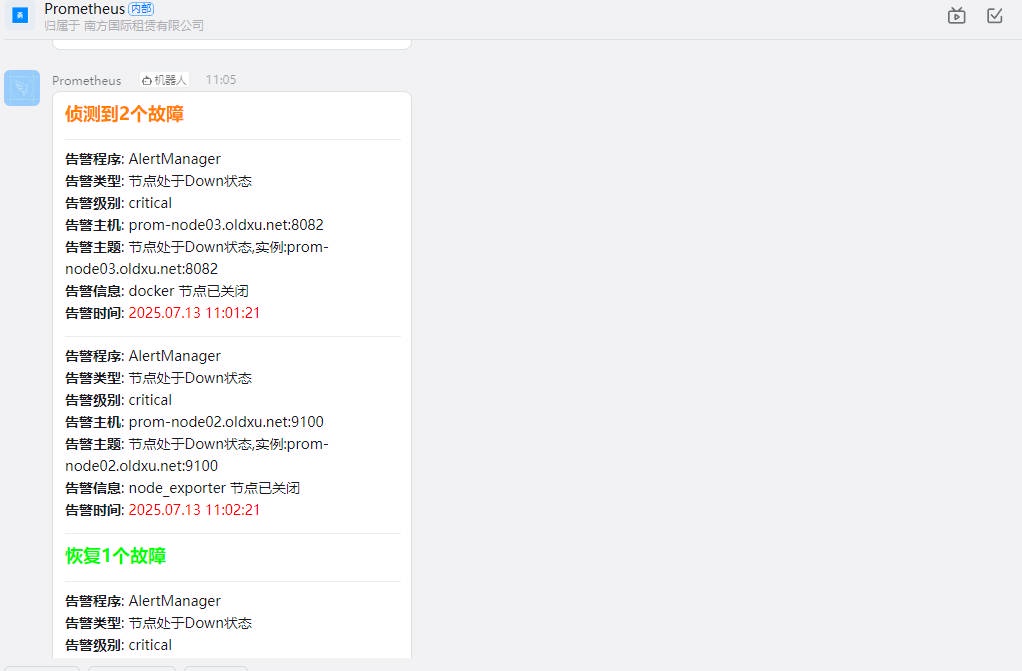
# 五. AlertManager 告警路由
# 5.1 告警路由介绍
所谓的告警路由,就是将不同的告警消息转发给不同的接收⼈,以便故障能快速的被处理和解决。
Alertmanager 的告警路由配置,使⽤的是树状结构来定义,以确保每条告警消息都能够按照定义好的路径进⾏处理。当⼀条告警消息进来后,会先进⼊根路由,然后逐级的去匹配每个⼦路由的规则,然后将消息通过媒介发送给对应的接收⼈。
例如,我们可以设置⼀个规则,将标签 severity 级别为 critical 的告警发送到钉钉,⽽剩余其他的告警则全部发送给微信。
AlertManager 告警路由场景示例:
- 1、mysql_exporter 和 redis_exporter 的 Job 告警时,就将其发送给 “钉钉的 DBA 团队”。
- 2、node_exporter 的 Job 告警时,则将告警路由到 “钉钉的 OPS 团队”。
- 3、最后,如果告警消息不符合上述任何⼀个规则,它们将默认通过微信发送给 “企业微信运维团队”。
# 5.2 告警路由实践
1、配置 AlertManager,添加子路由规则
[root@prom-node01 ~]# cat /etc/alertmanager/alertmanager.yml
global:
resolve_timeout: 2h # 已经触发了告警的消息,在多长时间内没有收到该告警的消息,则会自动将该告警标记为已解决。
smtp_smarthost: 'smtp.qq.com:587'
smtp_from: '373370405@qq.com' # 发件人邮件
smtp_auth_username: '373370405@qq.com' # 发件人用户名
smtp_auth_password: '******' # 发件人密码[授权码]
smtp_hello: 'qq.com'
smtp_require_tls: true
# 加载模板文件
templates:
- '/etc/alertmanager/template/email.tmpl' # 模板文件的实际路径
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
group_by: ['alertname'] #告警信息会根据告警名称分组,同名的告警消息会被归到一组,然后一起发送。(一个学校的一起搭⻋回家)
group_wait: 30s #当一组新告警产生时,系统会等待30秒,以便把这段时间内相同组的其他告警一起合并发送。(发车时间,保不齐在等待的30s内会有新的同校学生上车)
group_interval: 1m #已经发送了一个分组的告警通知之后,即使又有新的相同分组的告警到来,也需要等待至少1分钟后才会发送该分组的告警通知。(类似于发车间隔,没赶上就得等)
repeat_interval: 5m #如果同一个组中的报警信息已经发送成功了,下一次这个组发送告警的时间间隔(重复发送相同告警的时间间隔)
receiver: default #默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
# 子路由匹配规则
routes:
- match_re:
job: '(domain_exporter.*|blackbox_http.*)' #正则匹配
receiver: 'webhook-dingding-ops'
continue: true
- match_re:
job: 'node.*' #正则匹配
receiver: 'webhook-dingding-ops1'
continue: true
# - match:
# severity: 'critical' #精准匹配
# receiver: 'webhook-wechat'
# continue: true
receivers:
- name: 'webhook-dingding-ops'
webhook_configs:
- url: 'http://prom-node01.oldxu.net:5002/alert?token=906498a49ca8fdd29ae71258393f4ae25aff9ab3d47f007716ebb283f1c8e8db'
- name: 'webhook-dingding-ops1'
webhook_configs:
- url: 'http://prom-node01.oldxu.net:8060/dingtalk/webhook1/send'
- name: 'default'
email_configs:
- to: '373370405@qq.com'
send_resolved: true # 接受告警恢复的通知
html: '{{ template "email.html" . }}' # 发送邮件内容,调用该模板进行渲染
2、检查语法,并重新加载 AlertManager
[root@prom-node01 ~]# /etc/alertmanager/amtool check-config /etc/alertmanager/alertmanager.yml | |
Checking '/etc/alertmanager/alertmanager.yml' SUCCESS | |
Found: | |
- global config | |
- route | |
- 0 inhibit rules | |
- 3 receivers | |
- 1 templates | |
SUCCESS | |
[root@prom-node01 ~]# curl -X POST http://localhost:9093/-/reload |
# 5.3 告警路由验证
1、触发 mysql 和 redis 的告警,验证钉钉 - DBA 团队是否能收到告警消息
[root@prom-node03 ~]# systemctl stop mysqld_exporter.service redis_exporter.service |
2、触发 node 相关的告警,验证钉钉 - OPS 团队是否能收到告警消息
[root@prom-node02 ~]# systemctl stop node_exporter.service | |
[root@prom-node03 ~]# systemctl stop node_exporter.service |
3、触发 nginx 相关的告警,验证微信运维团队是否能收到告警消息
[root@prom-node03 ~]# systemctl stop nginx_exporter.service |
# 六. AlertManager 告警静默
# 6.1 告警静默介绍
在系统维护或升级过程中,通常会触发⼤量的告警。这些告警往往是维护系统的过程中引起的,⽽⾮真正出现了故障。如果我们不对告警通知进⾏调整,将会收到⼤量的告警信息,造成不必要的⼲扰。
为了应对这种情况,在维护期间,我们可以在 Alertmanager 中设置静默(silence)规则。这些规则能够禁⽌对外发送告警通知。等到维护⼯作完成后,我们再取消静默规则,恢复正常的告警通知流程。这样可以保证告警系统的有效性,同时避免了在维护期间产⽣⼤量不必要的告警信息。
告警静默配置有两种⽅式:
- 1、先告警后静默: 当告警发⽣时,我们可以直接在 WEB UI 界⾯上对其进⾏静默处理,从⽽停⽌持续发送相同告警信息,确保及时终⽌告警。
- 2、先配置静默: 在维护时可能会触发⼤量告警,这时我们可以提前创建静默规则,有效地防⽌告警⻛暴的发⽣。
# 6.2 配置告警静默
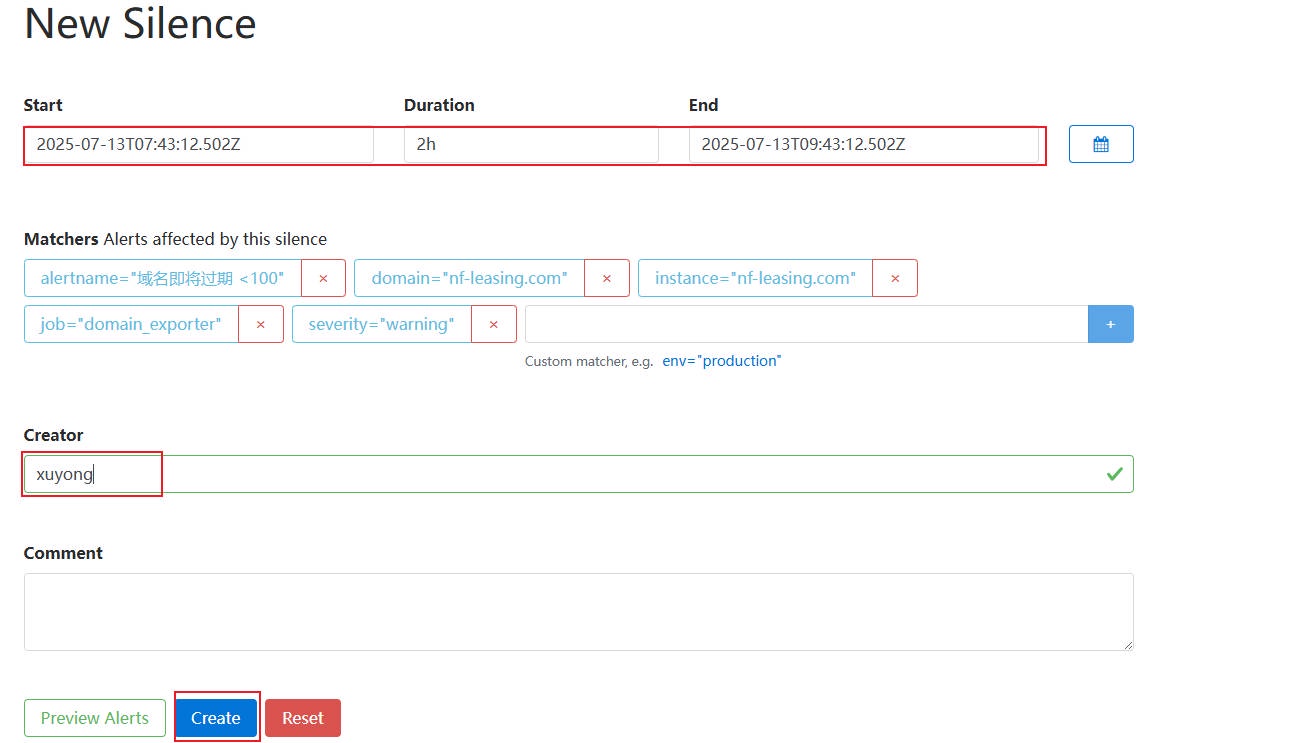
1、在 AlertManager 的 silences ⻚⾯,点击 New Silences,然后定义开始时间和结束时间(注意这个时间为 UTC 时间,如果转为北京时间要 + 8 ⼩时)
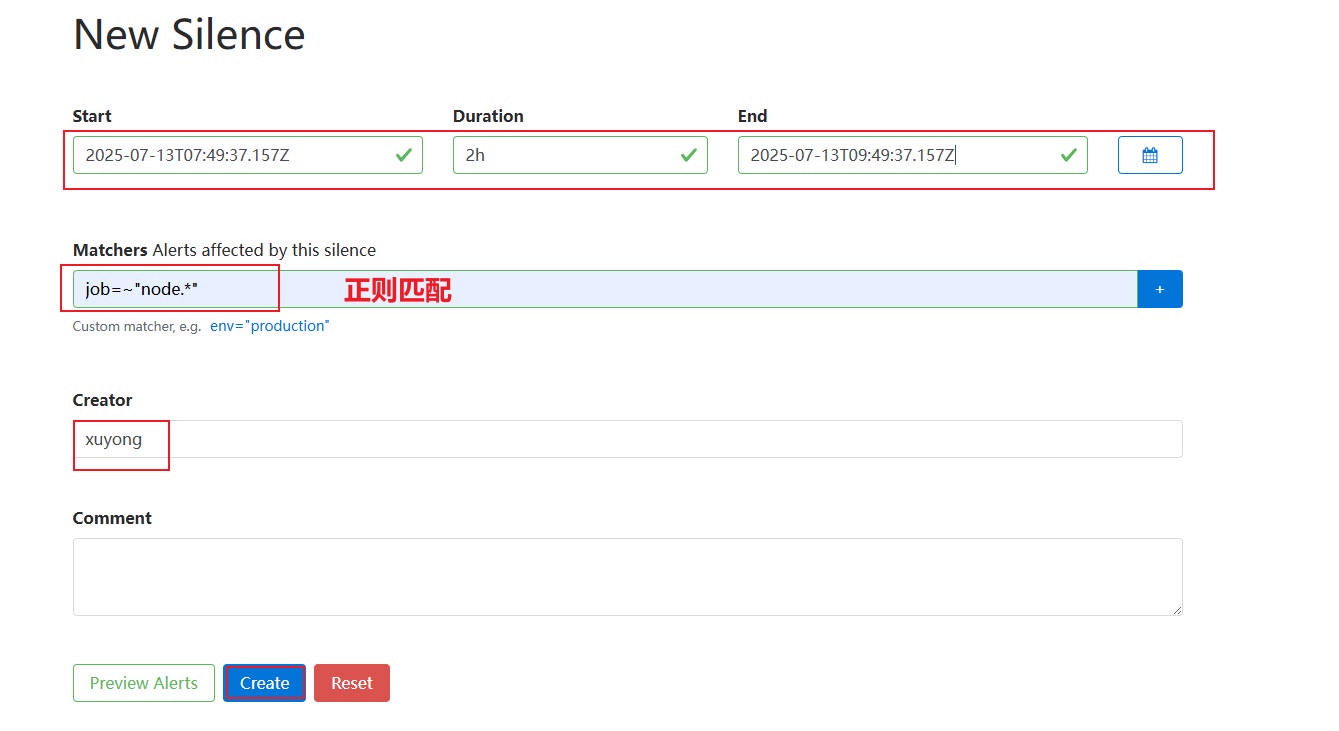
2、配置 Matchers,来定义静默规则,例如,我不希望在维护期间收到 node_exporter 这个 job 相关的任何告警,(注意:如果编写多个 Matchers 规则,它们是 “并且” 的关系)
3、检查最终的静默规则(当 State 状态由 Pending 转为 Active 则说明规则已经激活了,如果是 pengding 表示规则未到指定时间,没⽣效。)
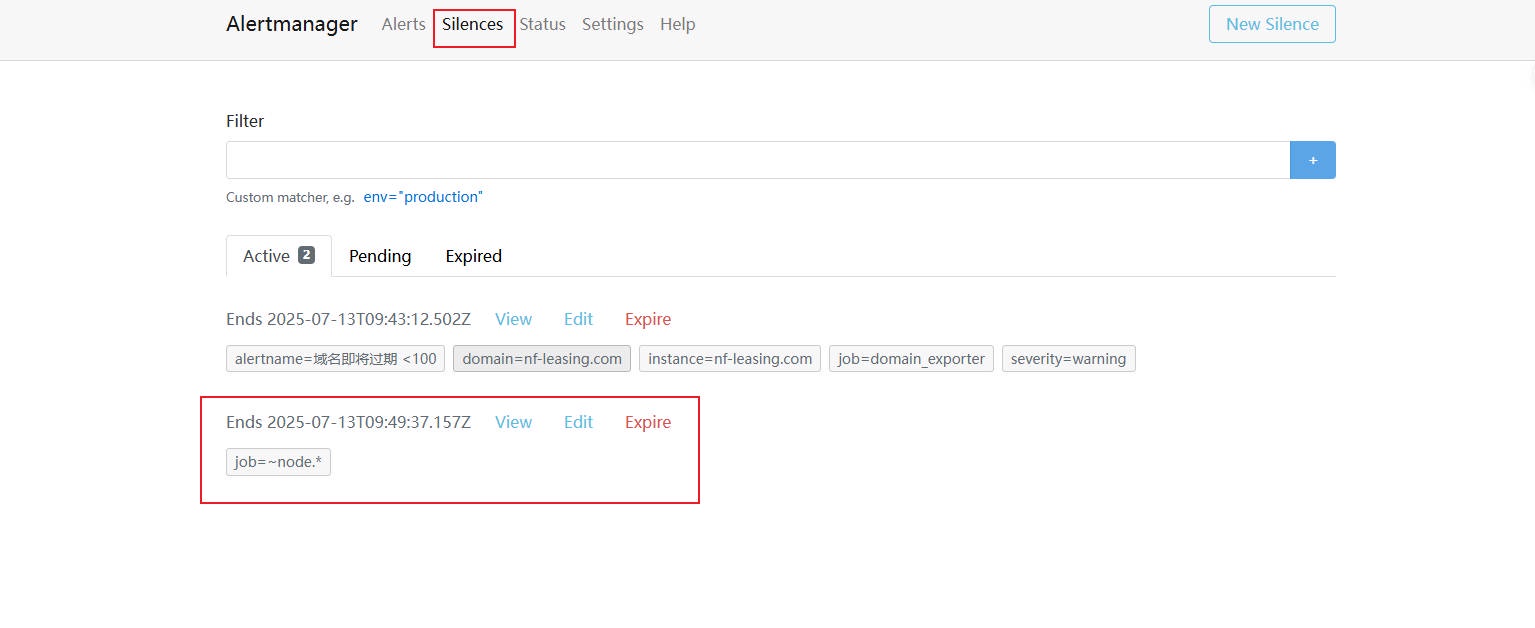
# 6.3 静默效果验证
1、通过程序模拟 Prometheus 发送告警信息,确保其中包含 job=~node_exporter ,以便与静默规则匹配。
# 下载告警程序 | |
[root@prom-node01 ~]# wget http://file.oldxu.net/prometheus/Alert/alert_test_oldxu | |
[root@prom-node01 ~]# chmod +x alert_test_oldxu | |
[root@prom-node03 ~]# docker run -it --rm -v `pwd`:/app/program ubuntu | |
root@4c83c1816d0b:/# cd /app/program/ | |
# alertname=nodedown(--alertURL 指定 alertmanager 服务器所在的地址、端⼝以及接⼝) | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=nodedown,instance=prom-node01.oldxu.net,severity=critical,job=node_exporter" | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=nodedown,instance=prom-node02.oldxu.net,severity=critical,job=node_exporter" | |
# alertname=cpuhigh | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=cpuhigh,instance=prom-node01.oldxu.net,severity=critical,job=node_exporter" | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=cpuhigh,instance=prom-node02.oldxu.net,severity=critical,job=node_exporter" |
2、访问 AlertManager ⻚⾯,点击 Silenced,然后查看被静默的告警信息
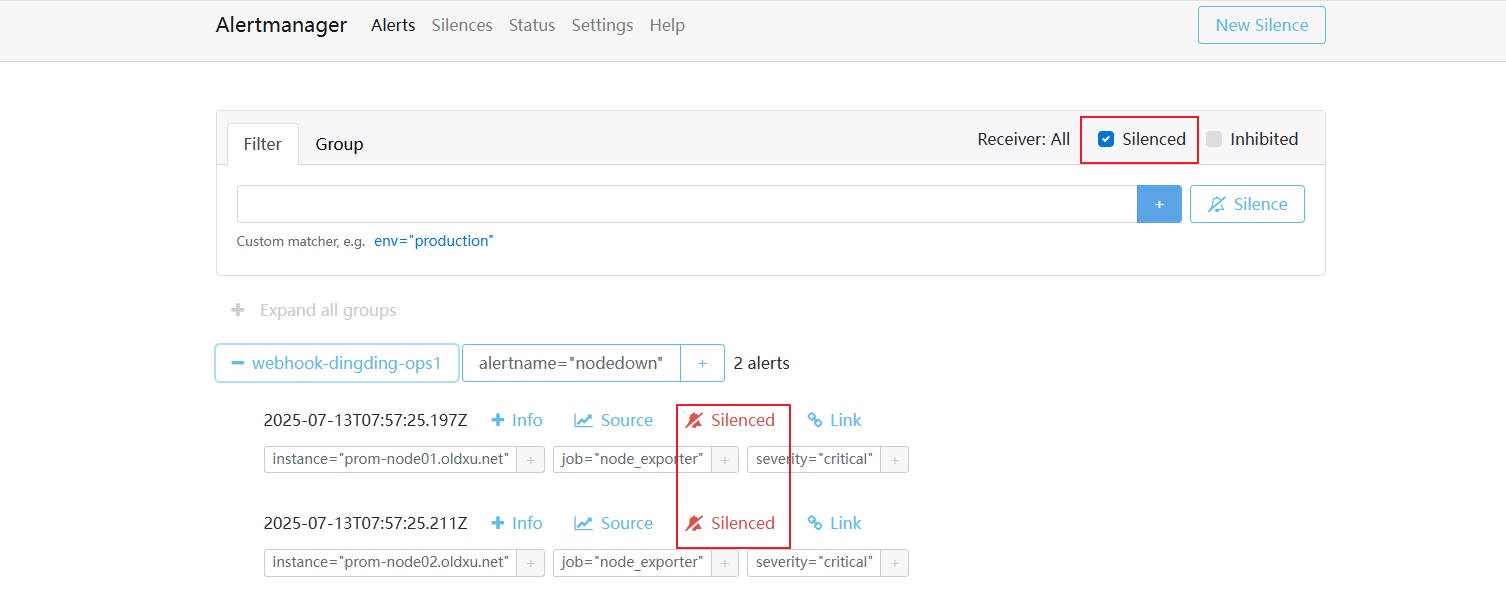
# 七. AlertManager 告警抑制
# 7.1 告警抑制介绍
当⼀个节点发⽣故障后,那么运⾏在该节点上的服务(nginx、tomcat、redis)都会失去响应,并且各⾃触发告警。因此为了避免被⼤量的告警信息淹没,我们可以设定⼀个抑制规则:当检测到节点故障,则⾃动抑制那些因节点故障⽽产⽣的次要告警,从⽽让⽤户将精⼒集中在真正的故障所在。
要实现告警抑制(Inhibition),就需要定义⼀些规则告诉 Alertmanager 在什么情况下应该阻⽌告警发送通知。避免重复或不必要的告警,抑制规则由以下⼏个关键参数构成:
- source_match 和 source_matchers(正则匹配):源告警,表示已经触发并且被识别为重要的告警。
- target_match 和 target_matchers(正则匹配):⽬标告警,则是那些可能 “由源告警所引起的告警”。当源告警被触发时,我们不希望这些⽬标告警发送通知,因为它们是源告警故障引起的告警。
- equal:⽤于指定源告警和⽬标告警之间必须匹配的标签,以确保抑制的相关性。
示例配置:如果检测到节点故障告警,则⾃动抑制该节点上所有服务的告警。
inhibit_rules: | |
- source_matchers: | |
- alertname = "NodeDown" # 源告警是节点故障告警。 | |
target_matchers: | |
- job =~ ".*" # ⽬标告警可以是任何 job 产⽣的,因为⼀个节点上的服务会被划分到不同的 job | |
equal: ["instance"] # 确保只有当源告警和⽬标告警具有相同的 instance 的值时,⽬标告警才会被抑制。 |
# 7.2 告警抑制场景 - 1
1、模拟节点故障,并且模拟因为节点故障从⽽造成的其他级联故障;
# 下载告警程序 | |
[root@prom-node01 ~]# wget http://file.oldxu.net/prometheus/Alert/alert_test_oldxu | |
[root@prom-node01 ~]# chmod +x alert_test_oldxu | |
[root@prom-node03 ~]# docker run -it --rm -v `pwd`:/app/program ubuntu | |
root@4c83c1816d0b:/# cd /app/program/ | |
# 主要故障 | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=NodeDown,instance=prom-node01.oldxu.net,job=node_exporter" | |
# 级联故障 | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=tomcatDown,instance=prom-node01.oldxu.net,job=tomcat_exporter" | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=NginxDown,instance=prom-node01.oldxu.net,job=nginx_exporter" |
2、正常情况下我们会收到 3 条告警消息,但最为重要的就是节点 Down 机,其他告警消息都是因为节点 Down ⽽产⽣的级联故障。
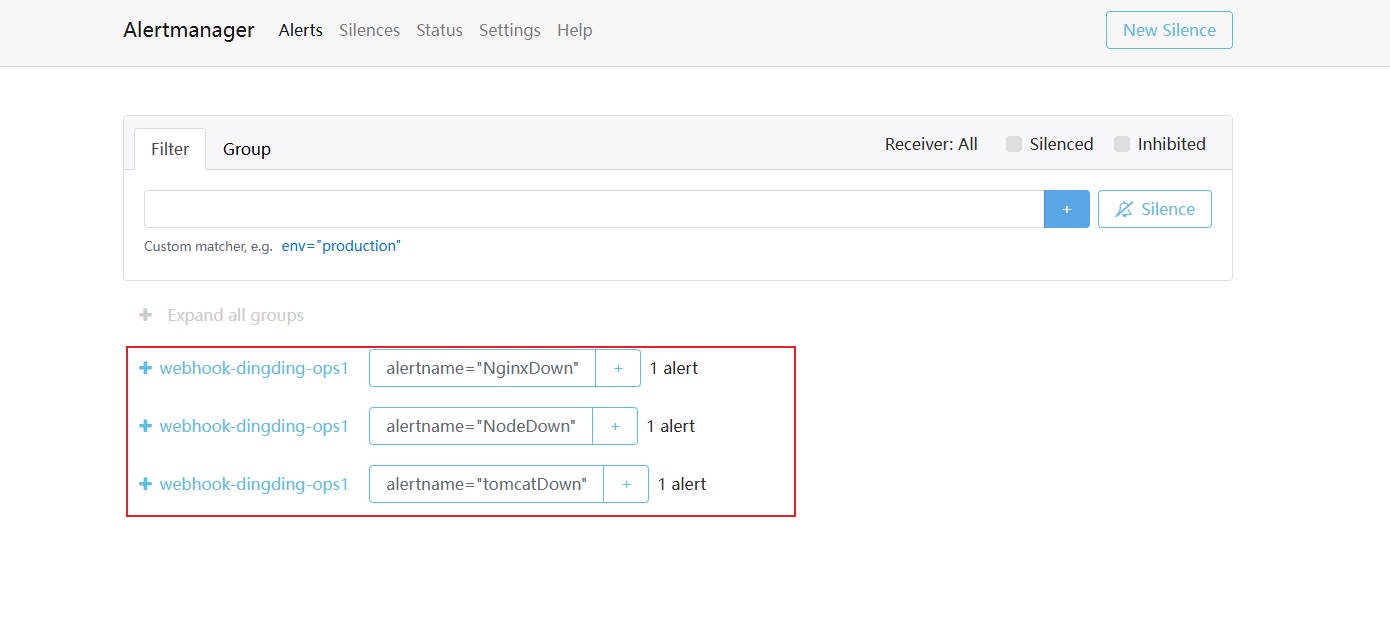
3、配置抑制规则,当节点出现故障,则抑制该节点上,其他应⽤因为节点故障⽽发出的级联故障
[root@prom-node01 ~]# vim /etc/alertmanager/alertmanager.yml | |
inhibit_rules: | |
- source_matchers: | |
- alertname = "NodeDown" # 假设当节点故障时,触发的告警名为 "NodeDown" | |
target_matchers: | |
- job =~ ".*" # 则抑制该节点上所有应⽤发送的故障,不论他是哪个 job 产⽣的 | |
equal: ["instance"] # instance 必须相等,才能表示是同⼀个节点上的告警 | |
[root@prom-node01 ~]# /etc/alertmanager/amtool check-config /etc/alertmanager/alertmanager.yml | |
[root@prom-node01 ~]# curl -X POST http://localhost:9093/-/reload |
4、再次模拟节点故障,以及节点故障所造成的应⽤级联故障
# 主要故障 | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=NodeDown,instance=prom-node01.oldxu.net,job=node_exporter" | |
# 级联故障 | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=tomcatDown,instance=prom-node01.oldxu.net,job=tomcat_exporter" | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=NginxDown,instance=prom-node01.oldxu.net,job=nginx_exporter" |
5、验证最终
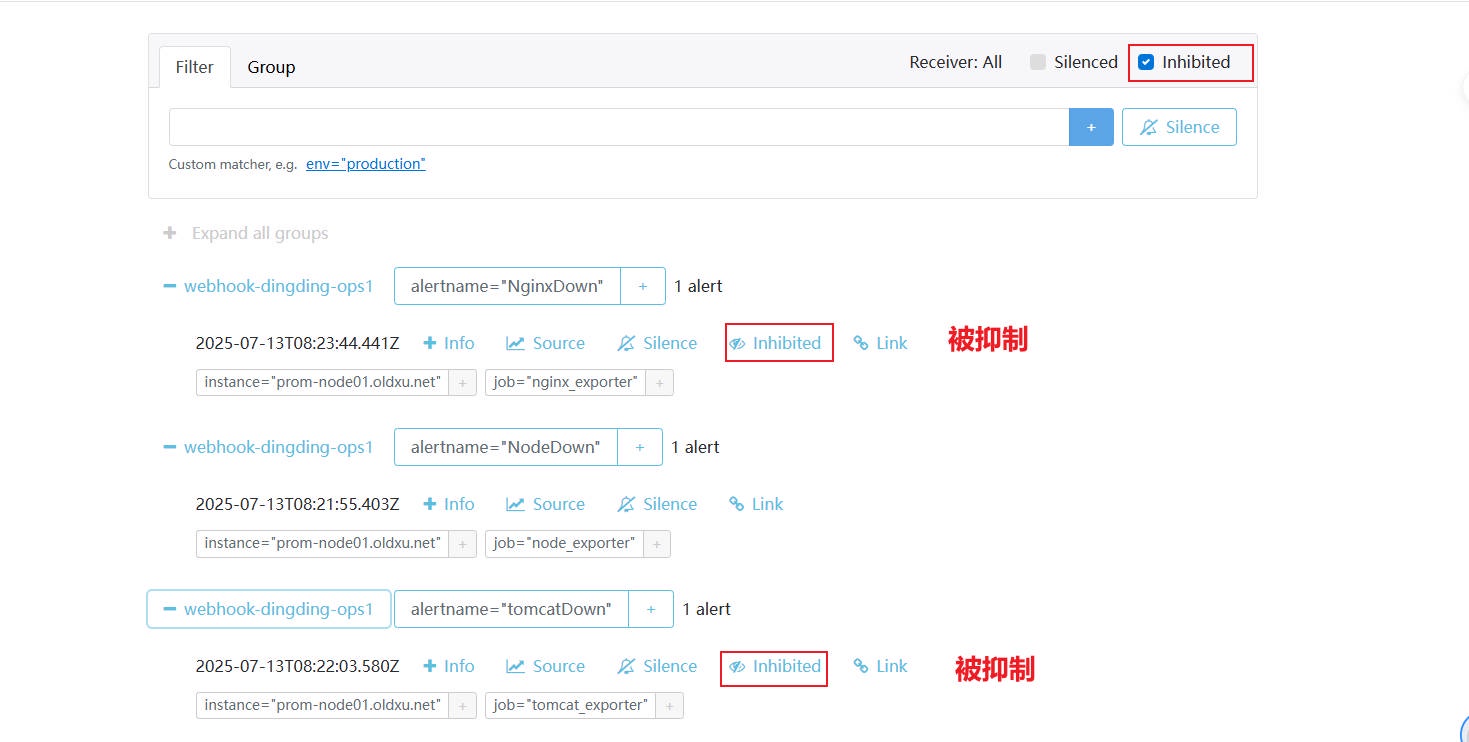
# 7.3 告警抑制场景 - 2
1、假设我们运⾏了 MySQL 主从,我们的告警规则如下:
groups: | |
- name: database-alerts | |
rules: | |
- alert: 主库down机了 | |
expr: up{service="database", role="master"} == 0 | |
for: 5m | |
labels: | |
severity: 'critical' | |
service: 'database' | |
role: 'master' | |
annotations: | |
summary: "master database down" | |
- alert: 从库down机了 | |
expr: up{service="database", role="slave"} == 0 | |
for: 5m | |
labels: | |
severity: 'warning' | |
service: 'database' | |
role: 'slave' | |
annotations: | |
summary: "slave database down" |
2、接下来,模拟主库异常和从库异常,看是否会收到两条告警消息。
# alertname = 节点故障(--alertURL 指定 alertmanager 服务器所在的地址、端⼝以及接⼝) | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" \ | |
--label="alertname=主库down机了,instance=mysql-master.oldxu.net,severity=critical,role=master,service=database,job=mysql_exporter" | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" \ | |
--label="alertname=从库down机了,instance=mysql-slave.oldxu.net,severity=critical,role=slave,service=database,job=mysql_exporter" |
3、配置抑制规则,当主库出现故障,则抑制从库的故障
[root@prom-node01 ~]# vim /etc/alertmanager/alertmanager.yml | |
inhibit_rules: | |
- source_match: | |
service: "database" | |
role: "master" | |
target_match: | |
role: "slave" | |
equal: ["service"] | |
[root@prom-node01 ~]# curl -X POST http://localhost:9093/-/reload |
# 八. AleartManager ⾼可⽤
# 8.1 AlertManager 传统架构
在⼤多数情况下,AlertManager 组件通常以单点架构存在,如下图所示。如果单点的 AlertManager 发⽣故障,将导致所有消息都⽆法及时发送,也就意味着系统即使出现了故障,我们也⽆法第⼀时间获取到对应的告警信息。
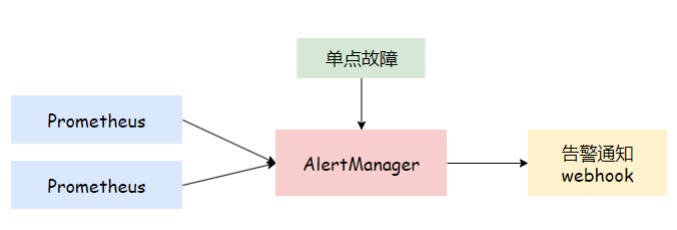
# 8.2 AlertManager ⾼可⽤架构
为了解决多个 AlertManager 之间的信息传递问题,AlertManager 引⼊了 Gossip 机制。这种机制类似于⼈们之间的留⾔传递,
通过 Gossip 多个 AlertManager 之间可以及时共享相同的告警信息。这意味着,即使多个 AlertManager 分别接收到相同的告警信息,系统也能确保只有⼀个告警通知被发送给 Receiver。此外,即便其中⼀台 AlertManager 发⽣故障,也不会对其他节点的消息传递产⽣影响。
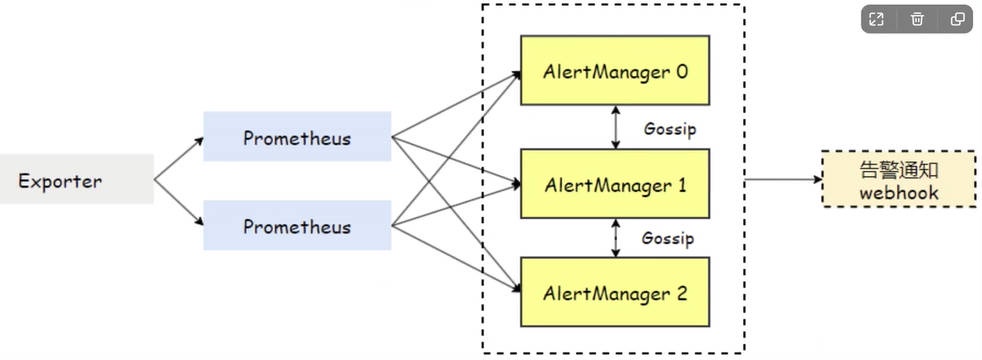
# 8.3 AlertManager ⾼可⽤配置实践
注意:需要保证每台的 /etc/alertmanager/alertmanager.yml 的配置是⾼度⼀致的。
| 主机名称 | IP 地址 | 角色 |
|---|---|---|
| prom-node01.oldxu.net | 192.168.40.221 | AlertManager-1 |
| prom-node02.oldxu.net | 192.168.40.222 | AlertManager-2 |
| prom-node03.oldxu.net | 192.168.40.223 | AlertManager-3 |
1、将 node01 节点上的,AlertManager 拷⻉⾄其他两个节点;
[root@prom-node01 ~]# scp -rp /etc/alertmanager-0.26.0.linux-amd64/ root@192.168.40.222:/etc/ | |
[root@prom-node01 ~]# scp -rp /etc/alertmanager-0.26.0.linux-amd64/ root@192.168.40.223:/etc/ | |
# node02 配置软链接 | |
[root@prom-node02 ~]# ln -s /etc/alertmanager-0.26.0.linux-amd64/ /etc/alertmanager | |
# node03 配置软链接 | |
[root@prom-node03 ~]# ln -s /etc/alertmanager-0.26.0.linux-amd64/ /etc/alertmanager |
2、在所有节点上,准备 alertmanager_ha.service 的启动配置⽂件(--cluster.listen-address: 当前实例集群服务监听地址 、--cluster.peer: 关联的其它实例地址
[root@prom-node01 ~]# systemctl stop alertmanager | |
vim /usr/lib/systemd/system/alertmanager_ha.service | |
[Unit] | |
Description=alertmanager | |
Documentation=https://prometheus.io/ | |
After=network.target | |
[Service] | |
ExecStart=/etc/alertmanager/alertmanager \ | |
--web.listen-address=:9093 \ | |
--cluster.listen-address=0.0.0.0:9094 \ | |
--cluster.peer=192.168.40.221:9094 \ | |
--cluster.peer=192.168.40.222:9094 \ | |
--cluster.peer=192.168.40.223:9094 \ | |
--cluster.peer-timeout=15s \ | |
--config.file=/etc/alertmanager/alertmanager.yml \ | |
--storage.path=/etc/alertmanager/data \ | |
--data.retention=120h | |
ExecReload=/bin/kill -HUP | |
TimeoutStopSec=20s | |
Restart=always | |
[Install] | |
WantedBy=multi-user.target | |
# systemctl daemon-reload | |
# systemctl start alertmanager_ha.service && systemctl start alertmanager_ha.service |
3、检查 AlertManager 集群状态
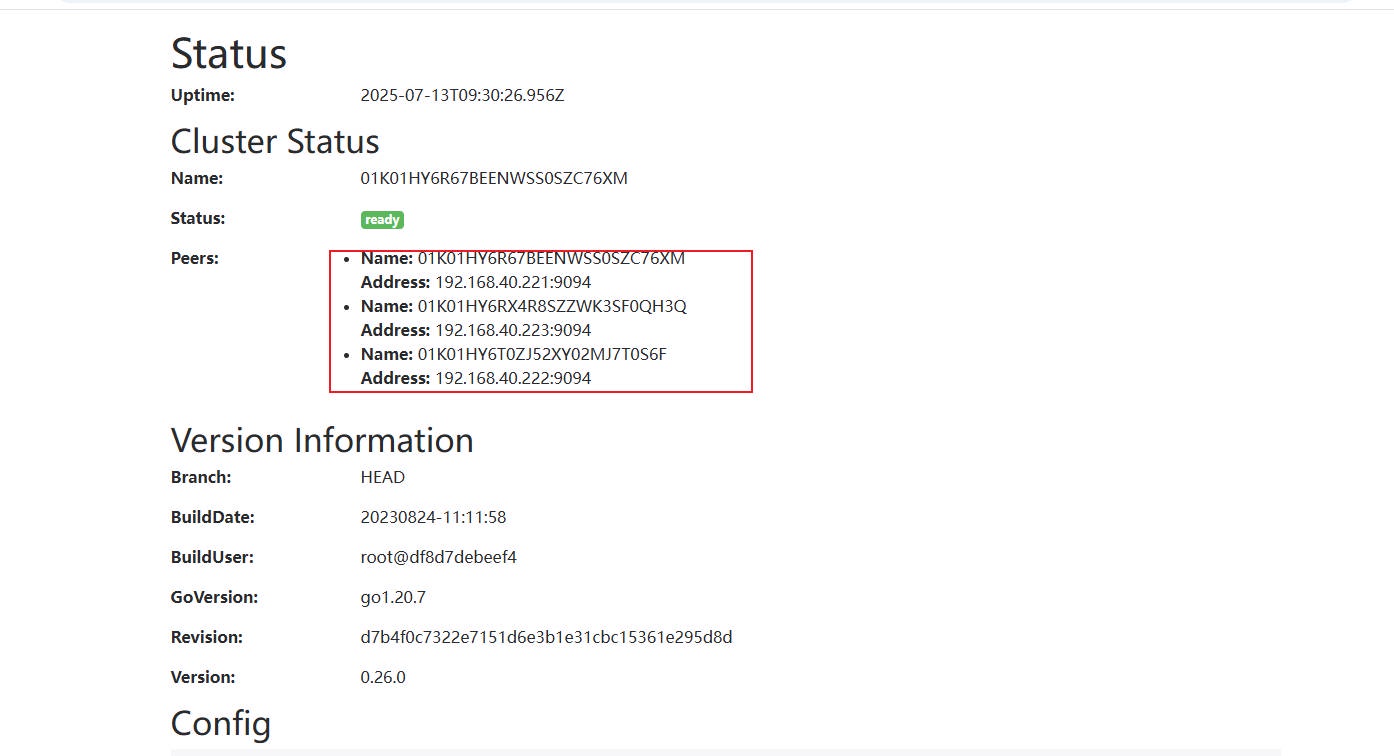
4、配置 Prometheus 对接多个 AlertManager 实例
[root@prom-node01 ~]# vim /etc/prometheus/prometheus.yml | |
alerting: | |
alertmanagers: | |
- static_configs: | |
- targets: | |
- prom-node01.oldxu.net:9093 | |
- prom-node02.oldxu.net:9093 | |
- prom-node03.oldxu.net:9093 | |
[root@prom-node01 ~]# curl -X POST http://localhost:9090/-/reload |
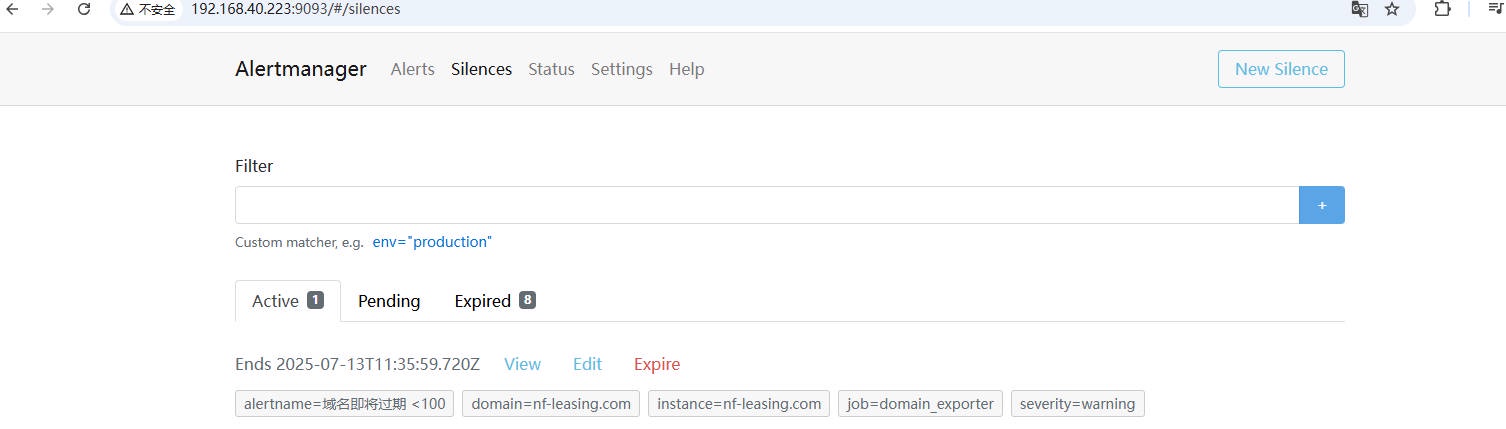
# 8.4 AlertManager ⾼可⽤结果验证
1、测试集群同步状态,当在⼀个节点上创建了⼀个静默(Silence)记录,其他节点的监控⻚⾯能够即时显示该静默的信息。
2、通过使⽤ curl 命令模拟 Prometheus,将同⼀条告警消息分别发送到两个 AlertManager 实例,验证最终是否只会收到⼀条消息。
# 下载告警程序 | |
[root@prom-node01 ~]# wget http://file.oldxu.net/prometheus/Alert/alert_test_oldxu | |
[root@prom-node01 ~]# chmod +x alert_test_oldxu | |
[root@prom-node03 ~]# docker run -it --rm -v `pwd`:/app/program ubuntu | |
root@4c83c1816d0b:/# cd /app/program/ | |
# alertname=nodedown(--alertURL 指定 alertmanager 服务器所在的地址、端⼝以及接⼝) | |
./alert_test_oldxu --alertURL="http://192.168.40.221:9093/api/v1/alerts" --label="alertname=nodedown,instance=prom-node01.oldxu.net,severity=critical,job=node_exporter" | |
./alert_test_oldxu --alertURL="http://192.168.40.222:9093/api/v1/alerts" --label="alertname=nodedown,instance=prom-node01.oldxu.net,severity=critical,job=node_exporter" |
3、根据此前的规则设定,node 相关的告警,最终会发送到 “钉钉的 OPS 团队”,并且只会有⼀条告警消息,⽽不会出现多条重复才对。

4、尝试停⽌掉某台 AlertManager 实例,验证消息是否还能正常发送。