
# Shell 文本处理工具 awk
# **1.**Awk 文本处理
# 1.1 什么是 awk
- awk 不仅仅是一个文本处理工具,通常用于处理数据并生成结果报告。
- 当然 awk 也是一门编程语言,是 linux 上功能最强大的数据处理工具之一。
# 1.2 为何需要正则表达式
- 第一种形式:awk 'BEGIN {} pattern {commands} END {}' file_name
- 第二种形式:standard output | awk BEGIN {} pattern {commands} END {}
- 第三种形式:awk -f awk-script-file filenames
| 语法格式 | 含义 |
|---|---|
| BEGIN {} | 正式处理数据之前执行 |
| pattern | 匹配模式,正则表达式;grep |
| 处理命令,可能多行 | |
| END{} | 处理完所有匹配数据后执行 |
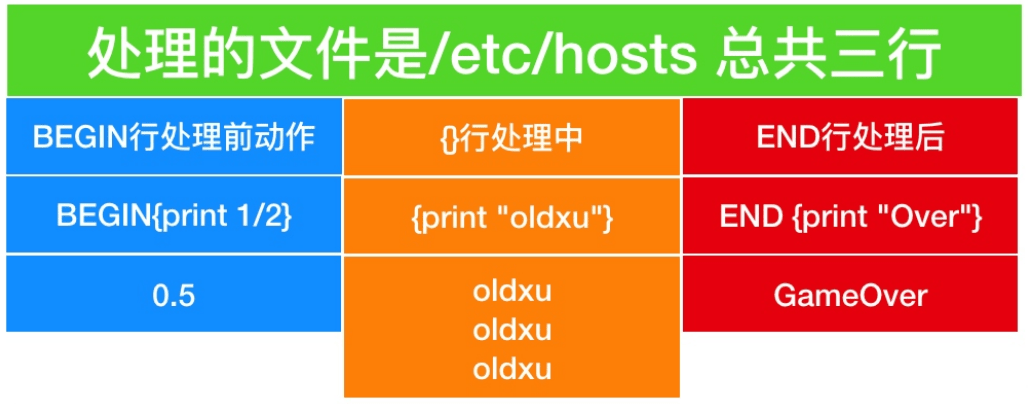
含义解释:
- BEGIN 发生在读文件之前,所有会在处理之前就执行了 1/2。
- {} 表示处理文件的过程,由于文件内有三行,所以会执行三次 print。
- END {} 表示文件处理完毕后的动作。
[root@web01 ~]# awk 'BEGIN{print 1/2} {print "oldxu"} END {print "Over"}' /etc/hosts | |
0.5 | |
oldxu | |
oldxu | |
oldxu | |
Over |
# 1.3 Awk 工作原理
awk -F : '{print $1,$3}' /etc/passwd
- 1.awk 将文件中的每一行作为输入,并将每一行赋给内部变量 $0, 以换行符结束
- 2.awk 开始进行字段分解,每个字段存储在已编号的变量中,从 $1 开始 [默认空格分割]
- 3.awk 默认字段分隔符是由内部 FS 变量来确定,可以使用 - F 修订
- 4.awk 行处理时使用了 print 函数打印分割后的字段
- 5.awk 在打印后的字段加上空格,因为 $1,$3 之间有一个逗号。逗号被映射至 OFS 内部变量中,称为输出字段分隔符, OFS 默认为空格
- 6.awk 输出之后,将从文件中获取另一行,并将其存储在 $0 中,覆盖原来的内容,然后将新的字符串分隔成字段并进行处理。该过程将持续到所有行处理完毕
AWK 变量总结:
- 1. 读入一行文件,默认是以 换行作为读入分隔符的(RS),读入进来后,会赋值给 $0,同时会为其编号赋值给 NR 变量;
- 2. 检查 FS 变量是否有指定字段分隔符,按照字段分隔符拆分成列的形式,将每一列的内容赋值给对应的 $1 $2 $3 等内部变量。同时会将分隔后的总列数赋值给 NF 变量;
- 3. 输出内容,输出时候会使用 print,$1,$3 这个逗号是输出字段分隔符,由 OFS 变量控制,默认是空;
- 4. 输出内容默认是按照换行符展示,由 ORS 控制,控制输出行分隔符,默认是换行符;
# 1.4 Awk 内部变量
| 内置变量 | 含义 |
|---|---|
| $0 | 整行内容 |
| $1-$n | 当前行的第 1-n 个字段 |
| NF | 当前行的字段个数,也就是多少列 |
| NR | 当前的行号,从 1 开始计数 |
| FS | 输入字段分隔符。不指定默认以空格或 tab 键分割 |
| RS | 输入行分隔符。默认回车换行 |
| OFS | 输出字段分隔符。默认为空格 |
| ORS | 输出行分隔符。默认为回车换行 |
要想了解 awk 的一些内部变量需要先准备如下数据文件:
[root@web01 ~]# cat file.txt | |
ll 1990 50 51 61 | |
kk 1991 60 52 62 | |
hh 1992 70 53 63 | |
jj 1993 80 54 64 | |
mm 1994 90 65 |
# 1.4.1 FS 指定分隔符
awk 通过内置变量,FS 来指定字段分割符, 默认以空白行作为分隔符
1. 输出文件中的第一列
[root@web01 ~]# awk '{print $1}' file.txt | |
ll | |
kk | |
hh | |
jj | |
mm |
2. 修改文件,然后指定多个分隔符,获取第一列内容
[root@web01 ~]# cat file.txt | |
ll:1990 50 51 61 | |
kk:1991 60 52 62 | |
hh 1992 70 53 63 | |
jj 1993 80 54 64 | |
mm 1994 90 55 65 | |
#以冒号或空格为分隔符 | |
[root@web01 ~]# awk -F '[: ]' '{print $2}' file.txt | |
1990 | |
1991 | |
1992 | |
1993 | |
1994 |
3. 再次修改文件
[root@web01 ~]# cat awk_file.txt | |
ll::1990 50 51 61 | |
kk:1991 60 52 62 | |
hh 1992 70 53 63 | |
jj 1993 80 54 64 | |
mm 1994 90 55 65 | |
#[:]+ 连续的多个冒号当一个分隔符,连续的多个空格当一个分隔符,连续空格和冒号也当做一个字符来处理 | |
[root@web01 ~]# awk -F '[: ]+' '{print $2}' file.txt | |
1990 | |
1991 | |
1992 | |
1993 | |
1994 |
# 1.4.2 NF 获取最后一列
awk 通过内置变量,NF 保存每行的最后一列内容
1. 通过 print 打印,NF 和 $NF,你发现了什么?
[root@web01 ~]# awk '{print $NF,NF}' file.txt | |
61 5 | |
62 5 | |
63 5 | |
64 5 | |
65 5 |
2. 如果将文件第五行的 65 置为空,那么该如何在获取最后一列的数字?
[root@web01 ~]# awk '{print $NF}' file.txt | |
61 | |
62 | |
63 | |
64 | |
55 |
3. 如果一个文件很长,靠数列数需要很长的时间,那如何快速打印倒数第二列
[root@web01 ~]# awk '{print $(NF-1)}' file.txt | |
51 | |
52 | |
53 | |
54 | |
90 |
# 1.4.3 NR 获取每行行号
awk 通过内置变量,NR 获取每行行号
1. 使用 print 打印 NR 变量,会发现 NR 会记录每行文件的行号
[root@web01 ~]# awk '{print NR,$0}' file.txt | |
1 ll 1990 50 51 61 | |
2 kk 1991 60 52 62 | |
3 hh 1992 70 53 63 | |
4 jj 1993 80 54 64 | |
5 mm 1994 90 55 |
2. 如果想打印第二行到第三行的内容,怎么做?
[root@web01 ~]# awk 'NR>1&&NR<4 {print NR,$0}' file.txt | |
2 kk 1991 60 52 62 | |
3 hh 1992 70 53 63 | |
# 如果想打印第三行,怎么做 | |
[root@web01 ~]# awk 'NR==3 {print NR,$0}' file.txt | |
3 hh 1992 70 53 63 |
3. 如果想打印第三行,同时还要打印第一列
[root@web01 ~]# awk 'NR==3 {print NR,$1}' file.txt | |
3 hh |
# 1.4.4 RS 读入行分隔符
awk 通过内置变量 RS,对读入的文本进行分隔符指定;
1. 准备文件内容
[root@web01 ~]# cat file2.txt | |
Linux|Shell|Nginx--docker|Gitlab|jenkins--mysql|redis|mongodb |
2. 读入文件,并以 -- 作为读入分隔符,然后将文件拆分为三列;
[root@web01 ~]# awk 'BEGIN{RS="--"}{print $0}' file2.txt | |
Linux|Shell|Nginx | |
docker|Gitlab|jenkins | |
mysql|redis|mongodb |
# 1.4.5 OFS 输出字段分隔符
awk 内置变量 OFS,输出字段分隔符,初始情况下 OFS 变量是空格。
[root@web01 ~]# awk 'BEGIN{RS="--";FS="|";OFS=":"} {print $1,$3}' file2.txt | |
Linux:Nginx | |
docker:jenkins | |
mysql:mongodb |
# 1.4.6 ORS 输出行分隔符
awk 内置变量 ORS,输出行分隔符,默认行分割符为 \n
[root@web01 ~]# awk 'BEGIN{RS="--";FS="|";OFS=":";ORS="==="} {print $1,$3}' file2.txt | |
Linux:Nginx===docker:jenkins===mysql:mongodb |
# 1.5 Awk 格式输出 Printf
awk 可以通过 printf 函数生成非常漂亮的数据报表。
# 1.5.1 printf 语法
| 格式符 | 含义 |
|---|---|
| %s | 打印字符串 |
| %d | 打印十进制数(整数) |
| %f | 打印一个浮点数(小数) |
| %x | 打印十六进制数 |
| 修饰符 | 含义 |
| - | 左对齐 |
| + | 右对齐 |
# 1.5.2 printf 示例
1.printf 默认没有分隔符。
[root@web01 ~]# awk 'BEGIN{FS=":"}{printf $1}' /etc/passwd | |
rootbindaemonadmlpsyncshutdownhaltmailoperatorgamesftpnobodysystemd-networkdbuspolkitdtssabrtsshdpostfixrpcrpcusernfsnobodyntpnginxwwwapachexuyongtestzhangwujizhaominxiexunyangxiao |
2. 加入换行,格式化输出。
[root@web01 ~]# awk 'BEGIN{FS=":"}{printf "%s\n",$1}' /etc/passwd | |
root | |
bin | |
daemon | |
adm | |
lp | |
sync | |
shutdown |
3. 使用占位符美化输出。
[root@web01 ~]# awk 'BEGIN{FS=":"} {printf "%20s %20s\n",$1,$7}' /etc/passwd | |
root /bin/bash | |
bin /sbin/nologin | |
daemon /sbin/nologin | |
adm /sbin/nologin | |
lp /sbin/nologin |
4. 默认右对齐,- 表示左对齐。
[root@web01 ~]# awk 'BEGIN{FS=":"} {printf "%-20s %-20s\n",$1,$7}' /etc/passwd | |
root /bin/bash | |
bin /sbin/nologin | |
daemon /sbin/nologin | |
adm /sbin/nologin | |
lp /sbin/nologin |
# 1.5.3 printf 实践
需求:美化一个成绩表
[root@web01 ~]# cat >>student.txt<<EOF | |
oldxu 80 90 96 98 | |
xiaowang 93 98 92 91 | |
xiaohong 78 76 87 92 | |
xiaoming 86 89 68 92 | |
xiaoxiao 85 95 75 90 | |
EOF |
编写 awk 处理脚本
[root@web01 ~]# cat student.awk | |
BEGIN { | |
printf "%-10s%-10s%-10s%-10s%-10s\n", | |
"Name","Yuwen","Shuxue","yinyu","qita" | |
} | |
{ | |
printf "%-10s%-10d%-10d%-10d%-10d\n", | |
$1,$2,$3,$4,$5 | |
} |
最终处理的结果
[root@web01 ~]# awk -f student.awk student.txt | |
Name Yuwen Shuxue yinyu qita | |
oldxu 80 90 96 98 | |
xiaowang 93 98 92 91 | |
xiaohong 78 76 87 92 | |
xiaoming 86 89 68 92 | |
xiaoxiao 85 95 75 90 |
美化添加合计
[root@web01 ~]# cat student.awk | |
BEGIN { | |
printf "%-10s%-10s%-10s%-10s%-10s%-10s\n", | |
"Name","Yuwen","Shuxue","yinyu","qita","total" | |
} | |
{ | |
total=$2+$3+$4+$5 | |
printf "%-10s%-10d%-10d%-10d%-10d%-10d\n", | |
$1,$2,$3,$4,$5,total | |
} | |
[root@web01 ~]# awk -f student.awk student.txt | |
Name Yuwen Shuxue yinyu qita total | |
oldxu 80 90 96 98 364 | |
xiaowang 93 98 92 91 374 | |
xiaohong 78 76 87 92 333 | |
xiaoming 86 89 68 92 335 | |
xiaoxiao 85 95 75 90 345 |
# 1.6 Awk 模式匹配
- awk 第一种模式匹配:RegExp
- awk 第二种模式匹配:运算匹配、布尔值匹配、数学运算符匹配
# 1.6.1 RegExp 示例
1. 匹配 /etc/passwd 文件行中含有 root 字符串的所有行。
[root@web01 ~]# awk -F ':' '/root/{print $0}' /etc/passwd | |
root:x:0:0:root:/root:/bin/bash | |
operator:x:11:0:operator:/root:/sbin/nologin |
2. 匹配 /etc/passwd 文件行中以 root 开头的行。
[root@web01 ~]# awk '/^root/{print $0}' /etc/passwd | |
root:x:0:0:root:/root:/bin/bash |
3. 匹配 /etc/passwd 文件行中 /bin/bash 结尾的行。
[root@web01 ~]# awk '/\/bin\/bash$/{print $0}' /etc/passwd | |
root:x:0:0:root:/root:/bin/bash | |
www:x:666:666::/home/www:/bin/bash | |
xuyong:x:1000:1000::/home/xuyong:/bin/bash | |
test:x:1001:1001::/home/test:/bin/bash | |
zhangwuji:x:1002:1002::/home/zhangwuji:/bin/bash | |
zhaomin:x:1003:1003::/home/zhaomin:/bin/bash | |
xiexun:x:1004:1004::/home/xiexun:/bin/bash | |
yangxiao:x:1005:1005::/home/yangxiao:/bin/bash |
4. 提取网卡 IP 地址
[root@web01 ~]# ifconfig ens192 |awk '/inet /{print $2}' | |
192.168.1.7 |
# 1.6.2 匹配运算符示例
匹配运算符:
- <:大于
- >:大于
- <=:小于等于
- >=:大于等于
- ==:等于
- !=:不等于
- ~:正则匹配
- !~:不匹配正则
1. 以:为分隔符,匹配 /etc/passwd 文件中第 3 个字段小于 50 的行
[root@web01 ~]# awk -F ":" '$3<2{print $0}' /etc/passwd | |
root:x:0:0:root:/root:/bin/bash | |
bin:x:1:1:bin:/bin:/sbin/nologin |
2. 以:为分隔符,匹配 /etc/passwd 文件中第 3 个字段大于 50 的行
[root@web01 ~]# awk -F ":" '$3>1000 {print $0}' /etc/passwd | |
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin | |
test:x:1001:1001::/home/test:/bin/bash | |
zhangwuji:x:1002:1002::/home/zhangwuji:/bin/bash | |
zhaomin:x:1003:1003::/home/zhaomin:/bin/bash | |
xiexun:x:1004:1004::/home/xiexun:/bin/bash | |
yangxiao:x:1005:1005::/home/yangxiao:/bin/bash |
3. 以:为分隔符,匹配 /etc/passwd 文件中第 7 个字段为 /bin/bash 的行
[root@web01 ~]# awk -F ":" '$7=="/bin/bash" {print $0}' /etc/passwd | |
root:x:0:0:root:/root:/bin/bash | |
www:x:666:666::/home/www:/bin/bash | |
xuyong:x:1000:1000::/home/xuyong:/bin/bash | |
test:x:1001:1001::/home/test:/bin/bash | |
zhangwuji:x:1002:1002::/home/zhangwuji:/bin/bash | |
zhaomin:x:1003:1003::/home/zhaomin:/bin/bash | |
xiexun:x:1004:1004::/home/xiexun:/bin/bash | |
yangxiao:x:1005:1005::/home/yangxiao:/bin/bash |
4. 以:为分隔符,匹配 /etc/passwd 文件中第 7 个字段不为 /bin/bash 的行
[root@web01 ~]# awk -F ":" '$7!="/bin/bash" {print $0}' /etc/passwd | |
bin:x:1:1:bin:/bin:/sbin/nologin | |
daemon:x:2:2:daemon:/sbin:/sbin/nologin |
5. 以:为分隔符,匹配 /etc/passwd 文件中第 3 个字段包含 3 个数字以上的行
[root@web01 ~]# awk -F ":" '$3 ~ /[0-9]{3,}/{print $0}' /etc/passwd | |
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin | |
polkitd:x:999:998:User for polkitd:/:/sbin/nologin | |
abrt:x:173:173::/etc/abrt:/sbin/nologin | |
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin | |
nginx:x:998:996:nginx user:/var/cache/nginx:/sbin/nologin | |
www:x:666:666::/home/www:/bin/bash | |
xuyong:x:1000:1000::/home/xuyong:/bin/bash | |
test:x:1001:1001::/home/test:/bin/bash | |
zhangwuji:x:1002:1002::/home/zhangwuji:/bin/bash | |
zhaomin:x:1003:1003::/home/zhaomin:/bin/bash | |
xiexun:x:1004:1004::/home/xiexun:/bin/bash | |
yangxiao:x:1005:1005::/home/yangxiao:/bin/bash |
# 1.6.3 布尔运算匹配符示例
布尔运算:
- &&:与
- |:或
- !:非
1. 以:为分隔符,匹配 passwd 文件中包含 ftp 或 mail 的行。
[root@web01 ~]# awk 'BEGIN{FS=":"}$1=="ftp" || $1=="mail" {print $0}' /etc/passwd | |
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin | |
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin |
2. 以:为分隔符,匹配 passwd 文件中第 3 个字段小于 50 并且第 4 个字段大于 50 的所有行信息。
[root@web01 ~]# awk 'BEGIN{FS=":"}$3<50 && $4>50{print $0}' /etc/passwd | |
games:x:12:100:games:/usr/games:/sbin/nologin |
3. 匹配没有 /sbin/nologin 的行。
[root@web01 ~]# awk 'BEGIN{FS=":"} $0 !~ /\/sbin\/nologin/{print $0}' /etc/passwd | |
root:x:0:0:root:/root:/bin/bash | |
sync:x:5:0:sync:/sbin:/bin/sync | |
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown | |
halt:x:7:0:halt:/sbin:/sbin/halt | |
www:x:666:666::/home/www:/bin/bash | |
xuyong:x:1000:1000::/home/xuyong:/bin/bash | |
test:x:1001:1001::/home/test:/bin/bash | |
zhangwuji:x:1002:1002::/home/zhangwuji:/bin/bash | |
zhaomin:x:1003:1003::/home/zhaomin:/bin/bash | |
xiexun:x:1004:1004::/home/xiexun:/bin/bash | |
yangxiao:x:1005:1005::/home/yangxiao:/bin/bash |
# 1.6.4 数学运算符匹配示例
加减乘除运算符:
- +:加
- -:减
- *:乘
- /:除
- %:模
1. 计算学生课程分数平均值,学生课程文件内容如下:
[root@web01 ~]# cat student.txt | |
oldxu 80 90 96 98 | |
xiaowang 93 98 92 91 | |
xiaohong 78 76 87 92 | |
xiaoming 86 89 68 92 | |
xiaoxiao 85 95 75 90 |
2. 编写 awk 脚本,实现学员成绩平均值
[root@web01 ~]# cat student.awk | |
BEGIN { | |
printf "%-10s%-10s%-10s%-10s%-10s%-10s\n", | |
"Name","Yuwen","Shuxue","yinyu","qita","Avg" | |
} | |
{ | |
total=$2+$3+$4+$5 | |
avg=total/(NF-1) | |
printf "%-10s%-10d%-10d%-10d%-10d%-10d\n", | |
$1,$2,$3,$4,$5,avg | |
} |
3. 执行脚本并观察结果
[root@web01 ~]# awk -f student.awk student.txt | |
Name Yuwen Shuxue yinyu qita Avg | |
oldxu 80 90 96 98 91 | |
xiaowang 93 98 92 91 93 | |
xiaohong 78 76 87 92 83 | |
xiaoming 86 89 68 92 83 | |
xiaoxiao 85 95 75 90 86 |
# 1.7 Awk 条件判断
# 1.7.1 单分支判断
if 语句格式:
1. 以:为分隔符,打印当前管理员用户名称
[root@web01 ~]# awk -F ':' '{ if($3==0){print $1 " is adminisitrator"} }' /etc/passwd | |
root is adminisitrator |
2. 以:为分隔符,统计系统用户数量
[root@web01 ~]# awk -F ':' '{if ($3>0 && $3<1000){i++}} END {print "一共有",i,"系统用户"}' /etc/passwd | |
一共有 25 系统用户 |
3. 以:为分隔符,统计普通用户数量
[root@web01 ~]# awk -F: '{if ($3>1000) {i++}} END {print "一共有",i,"普通用户"}' /etc/passwd | |
一共有 6 普通用户 |
4. 以:为分隔符,只打印 /etc/passwd 中第 3 个字段的数值在 50-100 范围内的行
[root@web01 ~]# awk 'BEGIN{FS=":"}{if($3>50 && $3<100) print $0}' /etc/passwd | |
nobody:x:99:99:Nobody:/:/sbin/nologin | |
dbus:x:81:81:System message bus:/:/sbin/nologin | |
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin | |
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin | |
postfix:x:89:89::/var/spool/postfix:/sbin/nologin |
# 1.7.2 双分支判断
if...else 语句格式: {if (表达式){语句;语句;... }else {语句;语句;...}}
1. 以:为分隔符,判断第三列如果等于 0,则打印该用户名称,如果不等于 0 则打印第七列。
[root@web01 ~]# awk 'BEGIN{FS=":"} { if($3==0) { print $1 } else { print $7 } }' /etc/passwd |
2. 以:为分隔符,判断第三列如果等于 0,那么则打印管理员出现的个数,否则都视为系统用户,并打印它的个数
[root@web01 ~]# awk 'BEGIN {FS=":";OFS="\n"} { if ($3==0) { i++ } else { j++ } } END { print i"个管理员" , j"个系统用户" }' /etc/passwd | |
1 个管理员 | |
32 个系统用户 |
# 1.7.3 多分支判断
if...else if...else 语句格式: {if (表达式 1) {语句;语句;...} else if (表达式 2) {语句;语句;... } else{语句;语句;... }}
1. 使用 awk if 打印出当前 /etc/passwd 文件管理员有多少个,系统用户有多少个,普通用户有多少个
[root@web01 ~]# cat count_passwd.awk | |
BEGIN { | |
FS=":" | |
OFS="\n" | |
} | |
{ | |
if ($3==0) { | |
i++ | |
} | |
else if ($3>=201 && $3<1000) { | |
j++ | |
} | |
else { | |
k++ | |
} | |
} | |
END { | |
print i"个管理员", j"个系统用户", k"个普通用户" | |
} | |
[root@web01 ~]# awk -f count_passwd.awk /etc/passwd | |
1个管理员 | |
3个系统用户 | |
29个普通用户 |
2. 打印 /etc/passwd 文件中 UID 小于 50 的、或 UID 小于 50 大于 100、或 UID 大于 100 的用户名以及 UID
[root@web01 ~]# cat count_password_2.awk | |
BEGIN { | |
FS=":" | |
} | |
{ | |
if ($3<50) { | |
printf "%-20s%-10s%-10d\n" , "UID<50",$1,$3 | |
} | |
else if ($3>50 && $3<100) { | |
printf "%-20s%-10s%-10s\n" , "UID>50 && UID<100",$1,$3 | |
} | |
else { | |
printf "%-20s%-10s%-10s\n" , "UID>100",$1,$3 | |
} | |
} | |
[root@web01 ~]# awk -f count_password_2.awk /etc/passwd | |
UID<50 root 0 | |
UID<50 bin 1 | |
UID<50 daemon 2 | |
UID<50 adm 3 | |
UID<50 lp 4 | |
UID<50 sync 5 | |
UID<50 shutdown 6 | |
UID<50 halt 7 | |
UID<50 mail 8 | |
UID<50 operator 11 | |
UID<50 games 12 | |
UID<50 ftp 14 | |
UID>50 && UID<100 nobody 99 | |
UID>100 systemd-network192 | |
UID>50 && UID<100 dbus 81 | |
UID>100 polkitd 999 | |
UID>50 && UID<100 tss 59 | |
UID>100 abrt 173 | |
UID>50 && UID<100 sshd 74 | |
UID>50 && UID<100 postfix 89 | |
UID<50 rpc 32 | |
UID<50 rpcuser 29 | |
UID>100 nfsnobody 65534 | |
UID<50 ntp 38 | |
UID>100 nginx 998 | |
UID>100 www 666 | |
UID<50 apache 48 | |
UID>100 xuyong 1000 | |
UID>100 test 1001 | |
UID>100 zhangwuji 1002 | |
UID>100 zhaomin 1003 | |
UID>100 xiexun 1004 | |
UID>100 yangxiao 1005 |
# 1.8 Awk 循环语句
# 1.8.1 while 循环
while 循环:while (条件表达式) 动作
[root@web01 ~]# awk 'BEGIN{ i=1; while(i<=10){print i; i++} }' | |
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
[root@web01 ~]# awk -F: '{i=1; while(i<=NF) {print $i; i++}}' /etc/passwd | |
[root@web01 ~]# awk -F: '{i=1; while(i<=10) {print $0; i++}}' /etc/passwd | |
[[root@web01 ~]# cat b.txt | |
111 222 | |
333 444 555 | |
666 777 888 999 | |
[root@web01 ~]# awk '{i=1;while(i<=NF) {print $i; i++}}' b.txt | |
111 | |
222 | |
333 | |
444 | |
555 | |
666 | |
777 | |
888 | |
999 |
# 1.8.2 for 循环
for 循环:for (初始化计数器;计数器测试;计数器变更) 动作
[root@web01 ~]# awk 'BEGIN{for(i=1;i<=5;i++){print i} }' | |
1 | |
2 | |
3 | |
4 | |
5 | |
#将每行打印 10 次 | |
[root@web01 ~]# awk -F: '{for(i=1;i<=10;i++) {print $0} }' /etc/passwd | |
[root@web01 ~]# awk -F: '{for(i=1;i<=NF;i++) {print $i} }' /etc/passwd |
# 1.8.3 循环场景示例
需求:计算 1+2+3+4+...+100 的和,请使用 while、for 两种循环方式实现
# while 循环 | |
[root@web01 ~]# cat awk_while_count.awk | |
BEGIN { | |
while ( i<=100 ) { | |
sum=sum+i | |
i++ | |
} | |
print sum | |
} | |
[root@web01 ~]# awk -f awk_while_count.awk | |
5050 | |
# for 循环 | |
[root@web01 ~]# cat awk_for_count.awk | |
BEGIN { | |
sum=0 | |
for (i=1;i<=100;i++) { | |
sum=sum+i | |
#sum+=i | |
} | |
print sum | |
} | |
[root@web01 ~]# awk -f awk_for_count.awk | |
5050 |
# 2.Awk 数组
# 2.1 什么是 awk 数组
- 数组其实也算是变量,传统的变量只能存储一个值,但数组可以存储多个值。
- 不区分 关联数组 普通数组;
# 2.2 awk 数组应用场景
通常用来统计、比如:统计网站访问 TOP10、网站 Url 访问 TOP10 等等等
# 2.3 awk 数组统计技巧
1. 在 awk 中,使用数组时,不仅可以使用 1 2 3 ..n 作为数组索引,也可以使用字符串作为数组索引。
2. 要统计某个字段的值,就将该字段作为数组的索引,然后对索引进行遍历。
- 1. 统计谁旧将谁作为索引的名称;
- 2. 然后让其相同的进行自增;
- 3. 遍历索引名称,获取对应出现的值,也就是次数;
# 2.4 awk 数组的语法
语法:array_name [index]=value
1. 统计 /etc/passwd 中各种类型 shell 的数量。
[root@web01 awk]# cat awk_passwd_type.awk | |
BEGIN { | |
FS=":" | |
} | |
# 1. 赋值 (没有写 while 循环,是因为 awk 本身就是循环读入文件) | |
{ | |
shell[$NF]++ | |
} | |
#2. 循环玩所有的文件后,才会取执行 END 阶段; | |
# shell 循环它,就是在循环数组的索引名称 | |
END { | |
for ( i in shell) { | |
print i,shell[i] | |
} | |
} | |
[root@web01 awk]# awk -f awk_passwd_type.awk /etc/passwd | |
/bin/sync 1 | |
/bin/bash 8 | |
/sbin/nologin 22 | |
/sbin/halt 1 | |
/sbin/shutdown 1 |
2. 统计主机上所有的 tcp 链接状态数,按照每个 tcp 状态分类。
[root@web01 awk]# netstat -an | grep tcp | awk '{arr[$6]++} END{for (i in arr) print i,arr[i]}' | |
LISTEN 8 | |
ESTABLISHED 1 |
# 2.5 Awk 数组 - Nginx 日志示例
使用 awk 完成对 Nginx 的日志分析,日志格式如下:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' | |
'$status$body_bytes_sent "$http_referer" ' | |
'"$http_user_agent" "$http_x_forwarded_for"'; | |
[root@web01 nginx]# cat access.1w_oldxu.log |head -n 5 | |
183.162.52.7 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/getadv HTTP/1.1" 200 813 "www.ixuyong.com" "-" cid=0×tamp=1478707261865&uid=2871142&marking=androidbanner&secrect=a6e8e14701ffe9f6063934780d9e2e6d&token=f51e97d1cb1a9caac669ea8acc162b96 "ixuyong/5.0.0 (Android 5.1.1; Xiaomi Redmi 3 Build/LMY47V),Network 2G/3G" "-" 10.100.134.244:80 200 0.027 0.027 | |
10.100.0.1 - - [10/Nov/2016:00:01:02 +0800] "HEAD / HTTP/1.1" 301 0 "117.121.101.40" "-" - "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.16.2.3 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-" - - - 0.000 | |
117.35.88.11 - - [10/Nov/2016:00:01:02 +0800] "GET /article/ajaxcourserecommends?id=124 HTTP/1.1" 200 2345 "www.ixuyong.com" "http://www.ixuyong.com/code/1852" - "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36" "-" 10.100.136.65:80 200 0.616 0.616 | |
182.106.215.93 - - [10/Nov/2016:00:01:02 +0800] "POST /socket.io/1/ HTTP/1.1" 200 94 "chat.ixuyong.com" "-" - "android-websockets-2.0" "-" 10.100.15.239:80 200 0.004 0.004 | |
10.100.0.1 - - [10/Nov/2016:00:01:02 +0800] "HEAD / HTTP/1.1" 301 0 "117.121.101.40" "-" - "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.16.2.3 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-" - - - 0.000 |
# 2.5.1 统计访问地址前 TOP10
[root@web01 nginx]# cat nginx_top_10_1 | |
{ | |
cip[$1]++ | |
} | |
END { | |
for ( i in cip ) { | |
print cip[i],i | |
} | |
} | |
[root@web01 nginx]# awk -f nginx_top_10_1 access.1w_oldxu.log |sort -rn |head -10 | |
4714 10.100.0.1 | |
94 122.234.145.54 | |
56 171.34.14.120 | |
51 115.34.187.133 | |
50 58.61.60.183 | |
48 27.38.56.2 | |
44 119.131.143.179 | |
43 58.217.137.221 | |
39 117.174.26.235 | |
37 223.73.113.60 |
# 2.5.2 统计访问页面前 TOP10
[root@web01 nginx]# cat nginx_page_10_1 | |
{ | |
page[$7]++ | |
} | |
END { | |
for ( i in page ) { | |
print page[i],i | |
} | |
} | |
[root@web01 nginx]# awk -f nginx_page_10_1 access.1w_oldxu.log |sort -rn | head -10 | |
4733 / | |
746 /course/ajaxmediauser/ | |
467 /course/ajaxmediauser | |
307 /socket.io/1/ | |
132 /u/card | |
109 /favicon.ico | |
103 /api3/savemediafinish | |
96 /api3/getinvitemeuserlist | |
94 /api3/latest | |
93 /u/loading |
# 2.5.3 统计访问次数大于 50 的 IP
[root@web01 nginx]# cat nginx_top_10_2 | |
{ | |
cip[$1]++ | |
} | |
END { | |
for ( i in cip ) { | |
if ( cip[i] > 50 ) { | |
print cip[i],i | |
} | |
} | |
} | |
[root@web01 nginx]# awk -f nginx_top_10_2 access.1w_oldxu.log |sort -rn | |
4714 10.100.0.1 | |
94 122.234.145.54 | |
56 171.34.14.120 | |
51 115.34.187.133 |
# 2.5.4 统计每个 URL 访问内容总大小
[root@web01 nginx]# cat nginx_page_total | |
{ | |
request[$7]+=$10 | |
count[$7]++ | |
} | |
END { | |
for ( i in request ) { | |
print request[i]/1024"kb",i,count[i] | |
} | |
} | |
[root@web01 nginx]# awk -f nginx_page_total access.1w_oldxu.log |sort -rn |head -10 | |
6144kb /f6e16e5d-ad78-42aa-acff-8af555fc4580/H.mp4 12 | |
5632kb /392d975e-ba78-4990-a30e-0b66c2dd5a03/H.mp4 11 | |
3072kb /894a9b9a-7ff0-4f2e-b46e-5c2f5b4b4311/M.mp4 6 | |
2602.81kb / 4733 | |
1697.21kb /static/module/class/content/img/49/section.png 1 | |
1295.42kb /582133e8000111a404680172.jpg 2 | |
1058.53kb /m/build/bundle.js 8 | |
1024kb /c3302c4e-54c8-42b5-8c7a-0ca642d9b106/L.mp4 2 | |
1024kb /b94b4de3-e0d4-4e05-b568-d4f4e51ae15e/M.mp4 2 | |
1024kb /b3631c9e-0c5b-44ff-b7f5-59d9704267fb/L.mp4 2 |
# 2.5.5 统计状态码为 404 出现的次数
[root@oldxu ~]# cat ngx_status_top_404 | |
{ | |
status[$9]++ | |
} | |
END{ | |
for ( item in status) { | |
if (item == 404 ) { | |
print item,status[item] | |
} | |
} | |
} | |
[root@web01 nginx]# cat ngx_status_top_404 | |
{ | |
status[$9]++ | |
} | |
END{ | |
for ( item in status) { | |
if (item == 404 ) { | |
print item,status[item] | |
} | |
} | |
} | |
[root@web01 nginx]# awk -f ngx_status_top_404 access.1w_oldxu.log | |
404 77 |
# 2.6 Awk 数组 - MySQL 日志示例
# 2.6.1 模拟数据脚本
1. 模拟生产环境数据脚本,需要跑大约 30~60s (等待一段时间 ctrl+c 结束即可 *)*
[root@web01 nginx]# cat insert.sh | |
#!/bin/bash | |
function create_random() | |
{ | |
min=$1 | |
max=$(($2-$min+1)) | |
num=$(date +%s%N) | |
echo $(($num%$max+$min)) | |
} | |
INDEX=1 | |
while true | |
do | |
for user in oldxu xiaowang xiaohong xiaoming xiaoqiang xiaoxiao | |
do | |
COUNT=$RANDOM | |
NUM1=`create_random 1 $COUNT` | |
NUM2=`expr $COUNT - $NUM1` | |
echo "`date '+%Y-%m-%d %H:%M:%S'` $INDEX user: $user insert $COUNT records into datebase:product table:detail, insert $NUM1 records successfully,failed $NUM2 records" >> ./db.log.`date +%Y%m%d` | |
INDEX=`expr $INDEX + 1` | |
done | |
done |
数据格式如下:
[root@web01 nginx]# cat db.log.20210928 | head -10 | |
2021-09-28 15:34:09 1 user: oldxu insert 27947 records into datebase:product table:detail, insert 7129 records successfully,failed 20818 records | |
2021-09-28 15:34:09 1 user: oldxu insert 27947 records into datebase:product table:detail, insert 7129 records successfully,failed 20818 records | |
2021-09-28 15:34:09 2 user: xiaowang insert 16074 records into datebase:product table:detail, insert 3197 records successfully,failed 12877 records | |
2021-09-28 15:34:09 3 user: xiaohong insert 18478 records into datebase:product table:detail, insert 13383 records successfully,failed 5095 records | |
2021-09-28 15:34:09 4 user: xiaoming insert 18002 records into datebase:product table:detail, insert 829 records successfully,failed 17173 records | |
2021-09-28 15:34:09 5 user: xiaoqiang insert 17678 records into datebase:product table:detail, insert 10832 records successfully,failed 6846 records | |
2021-09-28 15:34:09 6 user: xiaoxiao insert 9778 records into datebase:product table:detail, insert 1700 records successfully,failed 8078 records | |
2021-09-28 15:34:09 7 user: oldxu insert 9117 records into datebase:product table:detail, insert 4888 records successfully,failed 4229 records | |
2021-09-28 15:34:09 8 user: xiaowang insert 17468 records into datebase:product table:detail, insert 904 records successfully,failed 16564 records | |
2021-09-28 15:34:09 9 user: xiaohong insert 27025 records into datebase:product table:detail, insert 5661 records successfully,failed 21364 records | |
$5 用户名称 | |
$7 插入数据的总的次数 8302 | |
$13 有多少条数据插入成功 1166 | |
$16 有多少条数据插入失败 7136 | |
array[$5]+=$7 | |
success[$5]+=$13 | |
failed[$5]+=$16 |
# 2.6.2 awk 数组实践
需求 1:统计每个人分别插入了多少条 records 进数据库
[root@web01 nginx]# cat db_1 | |
{ | |
total_insert[$5]+=$7 | |
#插入次数 | |
count[$5]++ | |
} | |
END { | |
for ( i in total_insert ) { | |
print i,total_insert[i],count[i] | |
} | |
} | |
[root@web01 nginx]# awk -f db_1 db.log.20210928 | |
xiaoxiao 94883429 5749 | |
xiaoming 94932475 5749 | |
xiaohong 95591046 5749 | |
xiaoqiang 94070766 5749 | |
oldxu 93651798 5750 | |
xiaowang 93964965 5749 |
需求 2:统计每个人分别插入成功了多少 record,失败了多少 record
root@web01 nginx]# cat db_2 | |
{ | |
total[$5]+=$7 | |
success[$5]+=$13 | |
failed[$5]+=$16 | |
} | |
END { | |
for ( i in success ) { | |
print i,total[i],success[i],failed[i] | |
} | |
} | |
[root@web01 nginx]# awk -f db_2 db.log.20210928 | |
xiaoxiao 94883429 46698127 48185302 | |
xiaoming 94932475 47092399 47840076 | |
xiaohong 95591046 48906546 46684500 | |
xiaoqiang 94070766 47014395 47056371 | |
oldxu 93651798 46668476 46983322 | |
xiaowang 93964965 46679555 47285410 |
需求 3:将需求 1 和需求 2 结合起来,一起输出,输出每个人分别插入多少条数据,多少成功,多少失败,并且要格式化输出,加上标题
[root@web01 nginx]# cat db_3 | |
BEGIN { | |
printf "%-10s%-20s%-20s%-20s\n", | |
"User","Total", "Success", "Failed" | |
} | |
{ | |
total[$5]+=$7 | |
success[$5]+=$13 | |
failed[$5]+=$16 | |
} | |
END { | |
for ( i in success ) { | |
printf "%-10s%-20d%-20d%-20d\n", i,total[i],success[i],failed[i] | |
} | |
} | |
[root@web01 nginx]# awk -f db_3 db.log.20210928 | |
User Total Success Failed | |
xiaoxiao 94883429 46698127 48185302 | |
xiaoming 94932475 47092399 47840076 | |
xiaohong 95591046 48906546 46684500 | |
xiaoqiang 94070766 47014395 47056371 | |
oldxu 93651798 46668476 46983322 | |
xiaowang 93964965 46679555 47285410 |
需求 4:在例子 3 的基础上,加上结尾,统计全部插入记录数,成功记录数,失败记录数。
[root@web01 nginx]# cat db_4 | |
BEGIN { | |
printf "%-10s%-20s%-20s%-20s\n", | |
"User","Total", "Success", "Failed" | |
} | |
{ | |
total[$5]+=$7 | |
success[$5]+=$13 | |
failed[$5]+=$16 | |
# 变量 | |
total_number+=$7 | |
success_number+=$13 | |
failed_number+=$16 | |
} | |
END { | |
for ( i in success ) { | |
printf "%-10s%-20d%-20d%-20d\n", i,total[i],success[i],failed[i] | |
} | |
printf "%-10s%-20d%-20d%-20d \n", "zongji",total_number,success_number,failed_number | |
} | |
[root@web01 nginx]# awk -f db_4 db.log.20210928 | |
User Total Success Failed | |
xiaoxiao 94883429 46698127 48185302 | |
xiaoming 94932475 47092399 47840076 | |
xiaohong 95591046 48906546 46684500 | |
xiaoqiang 94070766 47014395 47056371 | |
oldxu 93651798 46668476 46983322 | |
xiaowang 93964965 46679555 47285410 | |
zongji 567094479 283059498 284034981 |