# ELK 收集 Kubernetes 组件日志分析与实践
# 一、ELK 创建 Namespace 和 Secrets
# kubectl create ns logging | |
# kubectl create secret docker-registry harbor-admin -n logging --docker-server=registry.cn-hangzhou.aliyuncs.com --docker-username=xyapples@163.com --docker-password=passwd |
# 二、交付 Zookeeper 集群至 K8S
# 2.1 制作 ZK 集群镜像
# 2.1.1 Dockerfile
# cat Dockerfile | |
FROM openjdk:8-jre | |
# 1、拷贝 Zookeeper 压缩包和配置文件 | |
ENV VERSION=3.8.4 | |
ADD ./apache-zookeeper-${VERSION}-bin.tar.gz / | |
ADD ./zoo.cfg /apache-zookeeper-${VERSION}-bin/conf | |
# 2、对 Zookeeper 文件夹名称重新命名 | |
RUN mv /apache-zookeeper-${VERSION}-bin /zookeeper | |
# 3、拷贝 eentrpoint 的启动脚本文件 | |
ADD ./entrypoint.sh /entrypoint.sh | |
# 4、暴露 Zookeeper 端口 | |
EXPOSE 2181 2888 3888 | |
# 5、执行启动脚本 | |
CMD ["/bin/bash","/entrypoint.sh"] |
# 2.1.2 zoo.cfg
# cat zoo.cfg | |
# 服务器之间或客户端与服务器之间维持心跳的时间间隔 tickTime 以毫秒为单位。 | |
tickTime={ZOOK_TICKTIME} | |
# 集群中的 follower 服务器 (F) 与 leader 服务器 (L) 之间的初始连接心跳数 10* tickTime | |
initLimit={ZOOK_INIT_LIMIT} | |
# 集群中的 follower 服务器与 leader 服务器之间请求和应答之间能容忍的最多心跳数 5 * tickTime | |
syncLimit={ZOOK_SYNC_LIMIT} | |
# 数据保存目录 | |
dataDir={ZOOK_DATA_DIR} | |
# 日志保存目录 | |
dataLogDir={ZOOK_LOG_DIR} | |
# 客户端连接端口 | |
clientPort={ZOOK_CLIENT_PORT} | |
# 客户端最大连接数。# 根据自己实际情况设置,默认为 60 个 | |
maxClientCnxns={ZOOK_MAX_CLIENT_CNXNS} | |
# 客户端获取 zookeeper 服务的当前状态及相关信息 | |
4lw.commands.whitelist=* | |
# 三个接点配置,格式为: server. 服务编号 = 服务地址、LF 通信端口、选举端口 |
# 2.1.3 entrypoint
# cat entrypoint.sh | |
#设定变量 | |
ZOOK_BIN_DIR=/zookeeper/bin | |
ZOOK_CONF_DIR=/zookeeper/conf/zoo.cfg | |
# 2、对配置文件中的字符串进行变量替换 | |
sed -i s@{ZOOK_TICKTIME}@${ZOOK_TICKTIME:-2000}@g ${ZOOK_CONF_DIR} | |
sed -i s@{ZOOK_INIT_LIMIT}@${ZOOK_INIT_LIMIT:-10}@g ${ZOOK_CONF_DIR} | |
sed -i s@{ZOOK_SYNC_LIMIT}@${ZOOK_SYNC_LIMIT:-5}@g ${ZOOK_CONF_DIR} | |
sed -i s@{ZOOK_DATA_DIR}@${ZOOK_DATA_DIR:-/data}@g ${ZOOK_CONF_DIR} | |
sed -i s@{ZOOK_LOG_DIR}@${ZOOK_LOG_DIR:-/logs}@g ${ZOOK_CONF_DIR} | |
sed -i s@{ZOOK_CLIENT_PORT}@${ZOOK_CLIENT_PORT:-2181}@g ${ZOOK_CONF_DIR} | |
sed -i s@{ZOOK_MAX_CLIENT_CNXNS}@${ZOOK_MAX_CLIENT_CNXNS:-60}@g ${ZOOK_CONF_DIR} | |
# 3、准备 ZK 的集群节点地址,后期肯定是需要通过 ENV 的方式注入进来 | |
for server in ${ZOOK_SERVERS} | |
do | |
echo ${server} >> ${ZOOK_CONF_DIR} | |
done | |
# 4、在 datadir 目录中创建 myid 的文件,并填入对应的编号 | |
ZOOK_MYID=$(( $(hostname | sed 's#.*-##g') + 1 )) | |
echo ${ZOOK_MYID:-99} > ${ZOOK_DATA_DIR:-/data}/myid | |
#5、前台运行 Zookeeper | |
cd ${ZOOK_BIN_DIR} | |
./zkServer.sh start-foreground |
# 2.1.4 构建镜像并推送仓库
# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz | |
# docker build -t registry.cn-hangzhou.aliyuncs.com/kubernetes_public/zookeeper:3.8.4 . | |
# docker push registry.cn-hangzhou.aliyuncs.com/kubernetes_public/zookeeper:3.8.4 |
# 2.2 迁移 zookeeper 至 K8S
# 2.2.1 zookeeper-headless
# cat 01-zookeeper-headless.yaml | |
apiVersion: v1 | |
kind: Service | |
metadata: | |
name: zookeeper-svc | |
namespace: logging | |
spec: | |
clusterIP: None | |
selector: | |
app: zookeeper | |
ports: | |
- name: client | |
port: 2181 | |
targetPort: 2181 | |
- name: leader-follwer | |
port: 2888 | |
targetPort: 2888 | |
- name: selection | |
port: 3888 | |
targetPort: 3888 |
# 2.2.2 zookeeper-sts
[root@k8s-master01 01-zookeeper]# vim 02-zookeeper-sts.yaml | |
apiVersion: apps/v1 | |
kind: StatefulSet | |
metadata: | |
name: zookeeper | |
namespace: logging | |
spec: | |
serviceName: "zookeeper-svc" | |
replicas: 3 | |
selector: | |
matchLabels: | |
app: zookeeper | |
template: | |
metadata: | |
labels: | |
app: zookeeper | |
spec: | |
affinity: | |
podAntiAffinity: | |
requiredDuringSchedulingIgnoredDuringExecution: | |
- labelSelector: | |
matchExpressions: | |
- key: app | |
operator: In | |
values: ["zookeeper"] | |
topologyKey: "kubernetes.io/hostname" | |
imagePullSecrets: | |
- name: harbor-admin | |
containers: | |
- name: zookeeper | |
image: registry.cn-hangzhou.aliyuncs.com/kubernetes_public/zookeeper:3.8.4 | |
imagePullPolicy: Always | |
ports: | |
- name: client | |
containerPort: 2181 | |
- name: leader-follwer | |
containerPort: 2888 | |
- name: selection | |
containerPort: 3888 | |
env: | |
- name: ZOOK_SERVERS | |
value: "server.1=zookeeper-0.zookeeper-svc.logging.svc.cluster.local:2888:3888 server.2=zookeeper-1.zookeeper-svc.logging.svc.cluster.local:2888:3888 server.3=zookeeper-2.zookeeper-svc.logging.svc.cluster.local:2888:3888" | |
readinessProbe: # 就绪探针,不就绪则不介入流量 | |
exec: | |
command: | |
- "/bin/bash" | |
- "-c" | |
- '[[ "$(/zookeeper/bin/zkServer.sh status 2>/dev/null|grep 2181)" ]] && exit 0 || exit 1' | |
initialDelaySeconds: 5 | |
livenessProbe: # 存活探针。如果不存活则根据重启策略进行重启 | |
exec: | |
command: | |
- "/bin/bash" | |
- "-c" | |
- '[[ "$(/zookeeper/bin/zkServer.sh status 2>/dev/null|grep 2181)" ]] && exit 0 || exit 1' | |
initialDelaySeconds: 5 | |
volumeMounts: | |
- name: data | |
mountPath: /data | |
subPath: data | |
- name: data | |
mountPath: /logs | |
subPath: logs | |
- name: tz-config | |
mountPath: /usr/share/zoneinfo/Asia/Shanghai | |
- name: tz-config | |
mountPath: /etc/localtime | |
- name: timezone | |
mountPath: /etc/timezone | |
volumes: | |
- name: tz-config | |
hostPath: | |
path: /usr/share/zoneinfo/Asia/Shanghai | |
type: "" | |
- name: timezone | |
hostPath: | |
path: /etc/timezone | |
type: "" | |
volumeClaimTemplates: | |
- metadata: | |
name: data | |
spec: | |
accessModes: ["ReadWriteMany"] | |
storageClassName: "nfs-storage" | |
resources: | |
requests: | |
storage: 5Gi |
# 2.2.3 更新资源清单
[root@k8s-master01 01-zookeeper]# kubectl apply -f 01-zookeeper-headless.yaml | |
[root@k8s-master01 01-zookeeper]# kubectl apply -f 02-zookeeper-sts.yaml | |
[root@k8s-master01 01-zookeeper]# kubectl get pods -n logging | |
NAME READY STATUS RESTARTS AGE | |
zookeeper-0 1/1 Running 0 17m | |
zookeeper-1 1/1 Running 0 14m | |
zookeeper-2 1/1 Running 0 11m |
# 2.2.4 检查 zookeeper 集群状态
# for i in 0 1 2 ; do kubectl exec zookeeper-$i -n logging -- /zookeeper/bin/zkServer.sh status; done | |
ZooKeeper JMX enabled by default | |
Using config: /zookeeper/bin/../conf/zoo.cfg | |
Client port found: 2181. Client address: localhost. Client SSL: false. | |
Mode: follower | |
ZooKeeper JMX enabled by default | |
Using config: /zookeeper/bin/../conf/zoo.cfg | |
Client port found: 2181. Client address: localhost. Client SSL: false. | |
Mode: leader | |
ZooKeeper JMX enabled by default | |
Using config: /zookeeper/bin/../conf/zoo.cfg | |
Client port found: 2181. Client address: localhost. Client SSL: false. | |
Mode: follower |
# 2.2.5 连接 Zookeeper 集群
[root@k8s-master01 01-zookeeper]# kubectl exec -it zookeeper-0 -n logging -- /bin/sh | |
# /zookeeper/bin/zkCli.sh -server zookeeper-svc | |
[zk: zookeeper-svc(CONNECTED) 0] create /hello oldxu | |
Created /hello | |
[zk: zookeeper-svc(CONNECTED) 1] get /hello | |
oldxu |
# 三、 交付 Kafka 集群至 K8S
# 3.1 制作 Kafka 集群镜像
# 3.1.1 Dockerfile
# cat Dockerfile | |
FROM openjdk:8-jre | |
# 1、调整时区 | |
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \ | |
echo 'Asia/Shanghai' > /etc/timezone | |
# 2、拷贝 kafka 软件以及 kafka 的配置 | |
ENV VERSION=2.12-2.2.0 | |
ADD ./kafka_${VERSION}.tgz / | |
ADD ./server.properties /kafka_${VERSION}/config/server.properties | |
# 3、修改 kafka 的名称 | |
RUN mv /kafka_${VERSION} /kafka | |
# 4、启动脚本(修改 kafka 配置) | |
ADD ./entrypoint.sh /entrypoint.sh | |
# 5、暴露 kafka 端口 9999 是 jmx 的端口 | |
EXPOSE 9092 9999 | |
# 6、运行启动脚本 | |
CMD ["/bin/bash","/entrypoint.sh"] |
# 3.1.2 server.properties
# cat server.properties | |
############################# Server Basics ############################# | |
# broker 的 id,值为整数,且必须唯一,在一个集群中不能重复 | |
broker.id={BROKER_ID} | |
############################# Socket Server Settings ############################# | |
# kafka 监听端口,默认 9092 | |
listeners=PLAINTEXT://{LISTENERS}:9092 | |
# 处理网络请求的线程数量,默认为 3 个 | |
num.network.threads=3 | |
# 执行磁盘 IO 操作的线程数量,默认为 8 个 | |
num.io.threads=8 | |
# socket 服务发送数据的缓冲区大小,默认 100KB | |
socket.send.buffer.bytes=102400 | |
# socket 服务接受数据的缓冲区大小,默认 100KB | |
socket.receive.buffer.bytes=102400 | |
# socket 服务所能接受的一个请求的最大大小,默认为 100M | |
socket.request.max.bytes=104857600 | |
############################# Log Basics ############################# | |
# kafka 存储消息数据的目录 | |
log.dirs={KAFKA_DATA_DIR} | |
# 每个 topic 默认的 partition | |
num.partitions=1 | |
# 设置副本数量为 3, 当 Leader 的 Replication 故障,会进行故障自动转移。 | |
default.replication.factor=3 | |
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量 | |
num.recovery.threads.per.data.dir=1 | |
############################# Log Flush Policy ############################# | |
# 消息刷新到磁盘中的消息条数阈值 | |
log.flush.interval.messages=10000 | |
# 消息刷新到磁盘中的最大时间间隔,1s | |
log.flush.interval.ms=1000 | |
############################# Log Retention Policy ############################# | |
# 日志保留小时数,超时会自动删除,默认为 7 天 | |
log.retention.hours=168 | |
# 日志保留大小,超出大小会自动删除,默认为 1G | |
#log.retention.bytes=1073741824 | |
# 日志分片策略,单个日志文件的大小最大为 1G,超出后则创建一个新的日志文件 | |
log.segment.bytes=1073741824 | |
# 每隔多长时间检测数据是否达到删除条件,300s | |
log.retention.check.interval.ms=300000 | |
############################# Zookeeper ############################# | |
# Zookeeper 连接信息,如果是 zookeeper 集群,则以逗号隔开 | |
zookeeper.connect={ZOOK_SERVERS} | |
# 连接 zookeeper 的超时时间,6s | |
zookeeper.connection.timeout.ms=6000 |
# 3.1.3 entrypoint
# cat entrypoint.sh | |
# 变量 | |
KAFKA_DIR=/kafka | |
KAFKA_CONF=/kafka/config/server.properties | |
# 1、基于主机名 + 1 获取 Broker_id 这个是用来标识集群节点 在整个集群中必须唯一 | |
BROKER_ID=$(( $(hostname | sed 's#.*-##g') + 1 )) | |
LISTENERS=$(hostname -i) | |
# 2、替换配置文件内容,后期 ZK 集群的地址通过 ENV 传递 | |
sed -i s@{BROKER_ID}@${BROKER_ID}@g ${KAFKA_CONF} | |
sed -i s@{LISTENERS}@${LISTENERS}@g ${KAFKA_CONF} | |
sed -i s@{KAFKA_DATA_DIR}@${KAFKA_DATA_DIR:-/data}@g ${KAFKA_CONF} | |
sed -i s@{ZOOK_SERVERS}@${ZOOK_SERVERS}@g ${KAFKA_CONF} | |
# 3、启动 Kafka | |
cd ${KAFKA_DIR}/bin | |
sed -i '/export KAFKA_HEAP_OPTS/a export JMX_PORT="9999"' kafka-server-start.sh | |
./kafka-server-start.sh ../config/server.properties |
# 3.1.4 构建镜像并推送仓库
# wget https://archive.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz | |
# docker build -t registry.cn-hangzhou.aliyuncs.com/kubernetes_public/kafka:2.12.2 . | |
# docker push registry.cn-hangzhou.aliyuncs.com/kubernetes_public/kafka:2.12.2 |
# 3.2 迁移 Kafka 集群至 K8S
# 3.2.1 kafka-headless
# cat 01-kafka-headless.yaml | |
apiVersion: v1 | |
kind: Service | |
metadata: | |
name: kafka-svc | |
namespace: logging | |
spec: | |
clusterIP: None | |
selector: | |
app: kafka | |
ports: | |
- name: client | |
port: 9092 | |
targetPort: 9092 | |
- name: jmx | |
port: 9999 | |
targetPort: 9999 |
# 3.2.2 kafka-sts
# cat 02-kafka-sts.yaml | |
apiVersion: apps/v1 | |
kind: StatefulSet | |
metadata: | |
name: kafka | |
namespace: logging | |
spec: | |
serviceName: "kafka-svc" | |
replicas: 3 | |
selector: | |
matchLabels: | |
app: kafka | |
template: | |
metadata: | |
labels: | |
app: kafka | |
spec: | |
affinity: | |
podAntiAffinity: | |
requiredDuringSchedulingIgnoredDuringExecution: | |
- labelSelector: | |
matchExpressions: | |
- key: app | |
operator: In | |
values: ["kafka"] | |
topologyKey: "kubernetes.io/hostname" | |
imagePullSecrets: | |
- name: harbor-admin | |
containers: | |
- name: kafka | |
image: registry.cn-hangzhou.aliyuncs.com/kubernetes_public/kafka:2.12.2 | |
imagePullPolicy: Always | |
ports: | |
- name: client | |
containerPort: 9092 | |
- name: jmxport | |
containerPort: 9999 | |
env: | |
- name: ZOOK_SERVERS | |
value: "zookeeper-0.zookeeper-svc:2181,zookeeper-1.zookeeper-svc:2181,zookeeper-2.zookeeper-svc:2181" | |
readinessProbe: # 就绪探针,不就绪则不介入流量 | |
tcpSocket: | |
port: 9092 | |
initialDelaySeconds: 5 | |
livenessProbe: # 存活探针。如果不存活则根据重启策略进行重启 | |
tcpSocket: | |
port: 9092 | |
initialDelaySeconds: 5 | |
volumeMounts: | |
- name: data | |
mountPath: /data | |
volumeClaimTemplates: | |
- metadata: | |
name: data | |
spec: | |
accessModes: ["ReadWriteMany"] | |
storageClassName: "nfs-storage" | |
resources: | |
requests: | |
storage: 5Gi |
# 3.2.3 更新资源清单
[root@k8s-master01 02-kafka]# kubectl apply -f 01-kafka-headless.yaml | |
[root@k8s-master01 02-kafka]# kubectl apply -f 02-kafka-sts.yaml | |
[root@k8s-master01 02-kafka]# kubectl get pods -n logging | |
NAME READY STATUS RESTARTS AGE | |
kafka-0 1/1 Running 0 5m49s | |
kafka-1 1/1 Running 0 4m43s | |
kafka-2 1/1 Running 0 3m40s | |
#查看 kafka 是否注册到 zookeeper | |
[root@k8s-master01 02-kafka]# kubectl exec -it zookeeper-0 -n logging -- /bin/bash | |
root@zookeeper-0:/# /zookeeper/bin/zkCli.sh | |
[zk: localhost:2181(CONNECTED) 2] get /brokers/ids/1 | |
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://172.16.85.201:9092"],"jmx_port":9999,"host":"172.16.85.201","timestamp":"1748162470218","port":9092,"version":4} | |
[zk: localhost:2181(CONNECTED) 3] get /brokers/ids/2 | |
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://172.16.58.205:9092"],"jmx_port":9999,"host":"172.16.58.205","timestamp":"1748162532658","port":9092,"version":4} | |
[zk: localhost:2181(CONNECTED) 4] get /brokers/ids/3 | |
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://172.16.195.1:9092"],"jmx_port":9999,"host":"172.16.195.1","timestamp":"1748162649250","port":9092,"version":4} |
# 3.2.4 检查 Kafka 集群
1.创建一个topic | |
root@kafka-0:/# /kafka/bin/kafka-topics.sh --create --zookeeper zookeeper-0.zookeeper-svc:2181,zookeeper-1.zookeeper-svc:2181,zookeeper-2.zookeeper-svc:2181 --partitions 1 --replication-factor 3 --topic oldxu | |
2.模拟消息发布 | |
root@kafka-1:/# /kafka/bin/kafka-console-producer.sh --broker-list kafka-0.kafka-svc:9092,kafka-1.kafka-svc:9092,kafka-2.kafka-svc:9092 --topic oldxu | |
>hello kubernetes | |
>hello world | |
3.模拟消息订阅 | |
root@kafka-2:/# /kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka-0.kafka-svc:9092,kafka-1.kafka-svc:9092,kafka-2.kafka-svc:9092 --topic oldxu --from-beginning | |
hello kubernetes | |
hello world |
# 四、交付 efak 至 K8S
# 4.1 制作 efak 镜像
# 4.1.1 Dockerfile
[root@manager 03-efak]# cat Dockerfile | |
FROM openjdk:8 | |
# 1、调整时区 | |
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \ | |
echo 'Asia/Shanghai' > /etc/timezone | |
# 2、拷贝 kafka 软件以及 kafka 的配置 | |
ENV VERSION=3.0.1 | |
ADD ./efak-web-${VERSION}-bin.tar.gz / | |
ADD ./system-config.properties /efak-web-${VERSION}/conf/system-config.properties | |
# 3、修改 efak 的名称 | |
RUN mv /efak-web-${VERSION} /efak | |
# 4、环境变量 | |
ENV KE_HOME=/efak | |
ENV PATH=$PATH:$KE_HOME/bin | |
# 5、启动脚本(修改 kafka 配置) | |
ADD ./entrypoint.sh /entrypoint.sh | |
# 6、暴露 kafka 端口 9999 是 jmx 的端口 | |
EXPOSE 8048 | |
# 7、运行启动脚本 | |
CMD ["/bin/bash","/entrypoint.sh"] |
# 4.1.2 system-config
# cat system-config.properties | |
###################################### | |
# 填写 zookeeper 集群列表 | |
###################################### | |
efak.zk.cluster.alias=cluster1 | |
cluster1.zk.list={ZOOK_SERVERS} | |
###################################### | |
# broker 最大规模数量 | |
###################################### | |
cluster1.efak.broker.size=20 | |
###################################### | |
# zk 客户端线程数 | |
###################################### | |
kafka.zk.limit.size=32 | |
###################################### | |
# EFAK webui 端口 | |
###################################### | |
efak.webui.port=8048 | |
###################################### | |
# kafka offset storage | |
###################################### | |
cluster1.efak.offset.storage=kafka | |
###################################### | |
# kafka jmx uri | |
###################################### | |
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi | |
###################################### | |
# kafka metrics 指标,默认存储 15 天 | |
###################################### | |
efak.metrics.charts=true | |
efak.metrics.retain=15 | |
###################################### | |
# kafka sql topic records max | |
###################################### | |
efak.sql.topic.records.max=5000 | |
efak.sql.topic.preview.records.max=10 | |
###################################### | |
# delete kafka topic token | |
###################################### | |
efak.topic.token=keadmin | |
###################################### | |
# kafka sqlite 数据库地址(需要修改存储路径) | |
###################################### | |
efak.driver=org.sqlite.JDBC | |
efak.url=jdbc:sqlite:{EFAK_DATA_DIR}/db/ke.db | |
efak.username=root | |
efak.password=www.kafka-eagle.org |
# 4.1.3 entrypoint
# cat entrypoint.sh | |
# 1、变量 | |
EFAK_DIR=/efak | |
EFAK_CONF=/efak/conf/system-config.properties | |
# 2、替换配置文件内容,后期 ZK 集群的地址通过 ENV 传递 | |
sed -i s@{EFAK_DATA_DIR}@${EFAK_DIR}@g ${EFAK_CONF} | |
sed -i s@{ZOOK_SERVERS}@${ZOOK_SERVERS}@g ${EFAK_CONF} | |
# 3、启动 efka | |
${EFAK_DIR}/bin/ke.sh start | |
tail -f ${EFAK_DIR}/logs/ke_console.out |
# 4.1.4 构建镜像并推送仓库
# wget https://github.com/smartloli/kafka-eagle-bin/archive/v3.0.1.tar.gz | |
# docker build -t registry.cn-hangzhou.aliyuncs.com/kubernetes_public/efak:3.0 . | |
# docker push registry.cn-hangzhou.aliyuncs.com/kubernetes_public/efak:3.0 |
# 4.2 迁移 efak 至 K8S
# 4.2.1 efak-deploy
# cat 01-efak-deploy.yaml | |
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
name: efak | |
namespace: logging | |
spec: | |
replicas: 1 | |
selector: | |
matchLabels: | |
app: efak | |
template: | |
metadata: | |
labels: | |
app: efak | |
spec: | |
imagePullSecrets: | |
- name: harbor-admin | |
containers: | |
- name: efak | |
image: registry.cn-hangzhou.aliyuncs.com/kubernetes_public/efak:3.0 | |
imagePullPolicy: Always | |
ports: | |
- name: http | |
containerPort: 8048 | |
env: | |
- name: ZOOK_SERVERS | |
value: "zookeeper-0.zookeeper-svc:2181,zookeeper-1.zookeeper-svc:2181,zookeeper-2.zookeeper-svc:2181" |
# 4.2.2 efak-service
# cat 02-efak-service.yaml
apiVersion: v1
kind: Service
metadata:
name: efak-svc
namespace: logging
spec:
selector:
app: efak
ports:
- port: 8048
targetPort: 8048
# 4.2.3 efak-ingress
# cat 03-efak-ingress.yaml | |
apiVersion: networking.k8s.io/v1 | |
kind: Ingress | |
metadata: | |
name: efak-ingress | |
namespace: logging | |
spec: | |
ingressClassName: "nginx" | |
rules: | |
- host: "efak.hmallleasing.com" | |
http: | |
paths: | |
- path: / | |
pathType: Prefix | |
backend: | |
service: | |
name: efak-svc | |
port: | |
number: 8048 |
# 4.2.4 更新资源清单
[root@k8s-master01 03-efak]# kubectl apply -f 01-efak-deploy.yaml | |
[root@k8s-master01 03-efak]# kubectl apply -f 02-efak-service.yaml | |
[root@k8s-master01 03-efak]# kubectl apply -f 03-efak-ingress.yaml |
# 4.2.5 访问 efka
1、初始用户名密码 admin 123456
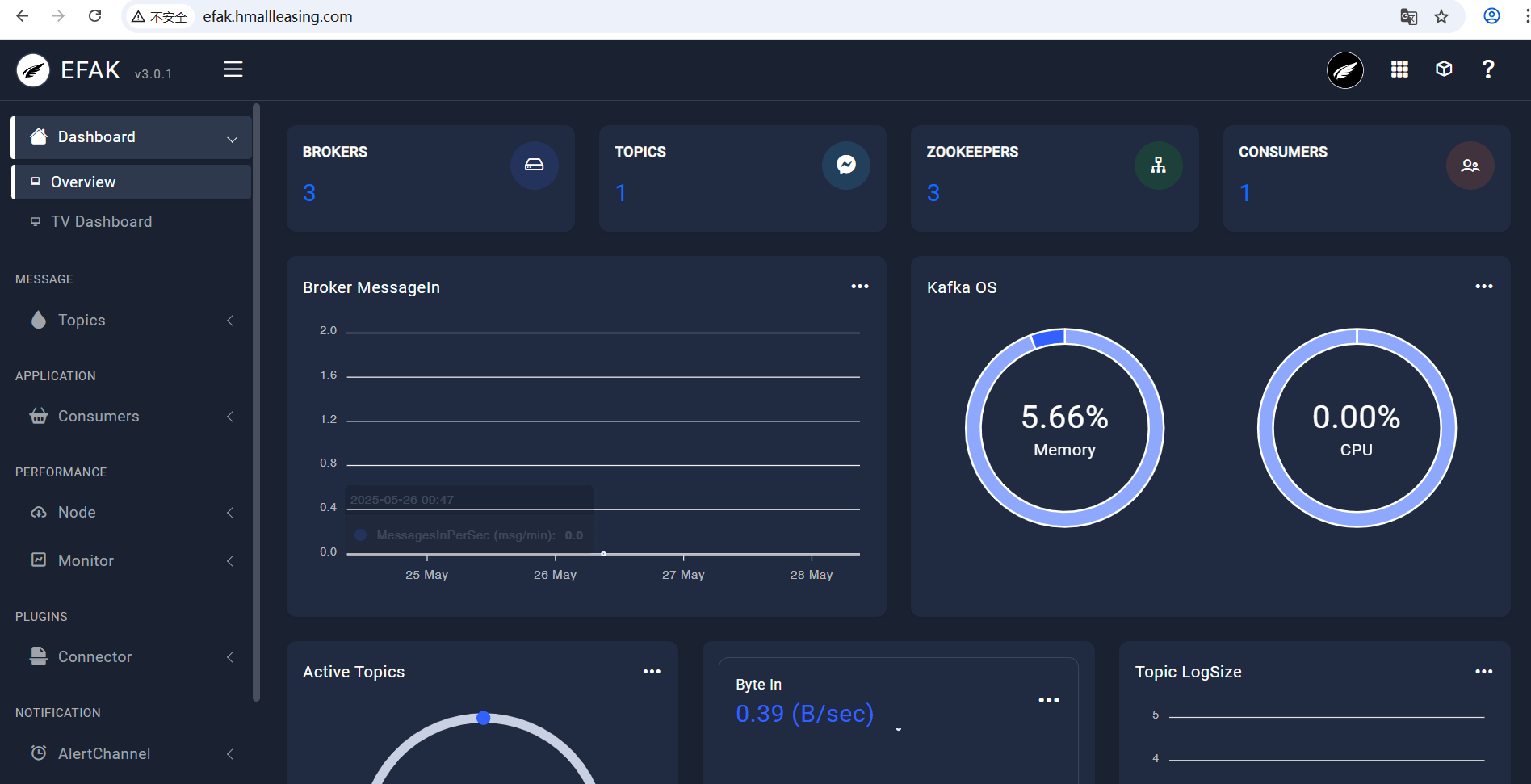
2、查看 Topics
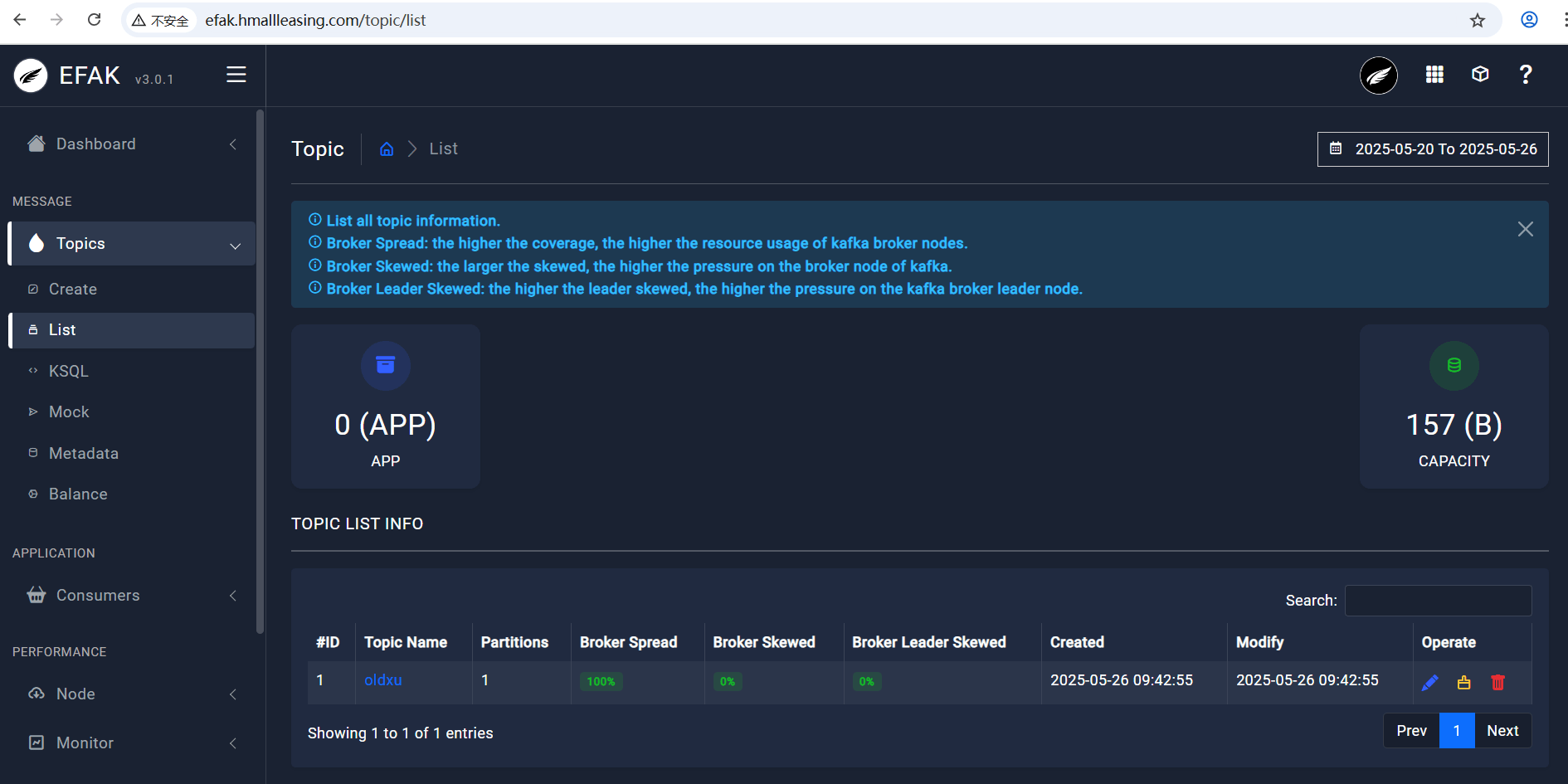
3、查看 kafka 集群状态
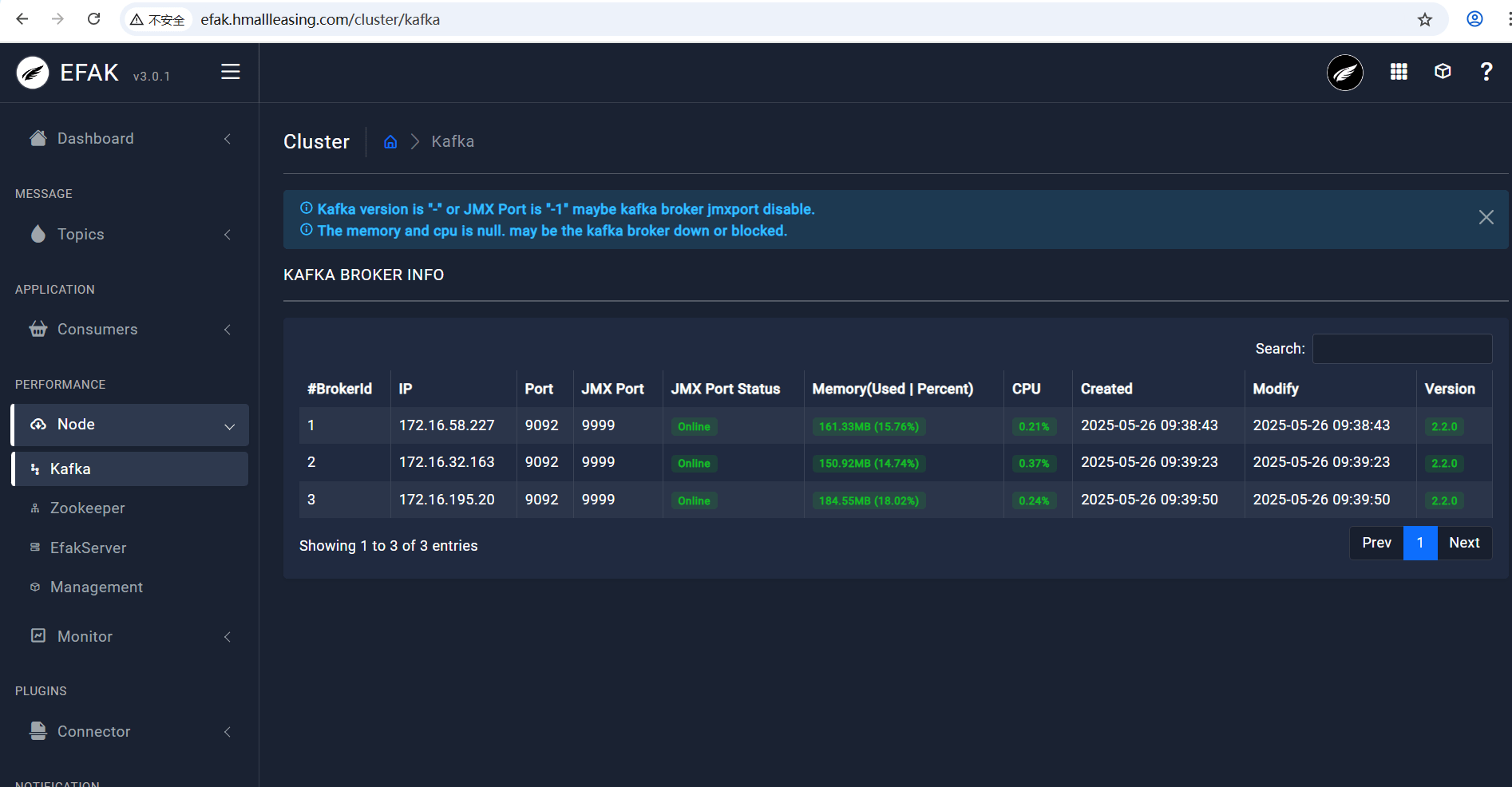
4、查看 Zookeeper 集群状态

# 五、交付 Elastic 集群
- ES 集群是由多个节点组成的,通过 cluster.name 设置 ES 集群名称,同时用于区分其它的 ES 集群。
- 每个节点通过 node.name 参数来设定所在集群的节点名称。
- 节点使用 discovery.send_hosts 参数来设定集群节点的列表。
- 集群在第一次启动时,需要初始化,同时需要指定参与选举的 master 节点 IP,或节点名称。
- 每个节点可以通过 node.master:true 设定为 master 角色,通过 node.data:true 设定为 data 角色。
[root@k8s-master01 ~]# grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml | |
# 集群名称 cluster.name: my-oldxu | |
# 节点名称 node.name: node1 | |
# 数据存储路径 path.data: /var/lib/elasticsearch | |
# 日志存储路径 path.logs: /var/log/elasticsearch | |
# 监听在本地哪个地址上 network.host: 10.0.0.100 | |
# 监听端口 http.port: 9200 | |
# 集群主机列表 discovery.seed_hosts: ["ip1", "ip2", "ip3"] | |
# 仅第一次启动集群时进行选举(可以填写 node.name 的名称)cluster.initial_master_nodes: ["node01", "node02", "node03"] |
# 5.1 下载 elastic 镜像
# docker pull elasticsearch:7.17.6 | |
# docker tag elasticsearch:7.17.6 registry.cn-hangzhou.aliyuncs.com/kubernetes_public/elasticsearch:7.17.6 | |
# docker push registry.cn-hangzhou.aliyuncs.com/kubernetes_public/elasticsearch:7.17.6 |
# 5.2 交付 ES-Service
创建 es-headlessService,为每个 ES Pod 设定固定的 DNS 名称,无论它是 Master 或是 Data,易或是 Coordinating
# cat 01-es-svc.yaml | |
apiVersion: v1 | |
kind: Service | |
metadata: | |
name: es-svc | |
namespace: logging | |
spec: | |
selector: | |
app: es | |
clusterIP: None | |
ports: | |
- name: cluster | |
port: 9200 | |
targetPort: 9200 | |
- name: transport | |
port: 9300 | |
targetPort: 9300 |
# 5.3 交付 ES-Master 节点
ES 无法使用 root 直接启动,需要授权数据目录 UID=1000,同时还需要持久化 /usr/share/elasticsearch/data ;
ES 所有节点都需要设定 vm.max_map_count 内核参数以及 ulimit;
ES 启动是通过 ENV 环境变量传参来完成的;
集群名称、节点名称、角色类型;
discovery.seed_hosts 集群地址列表;
cluster.initial_master_nodes 初始集群参与选举的 master 节点名称;
# cat 02-es-master.yaml | |
apiVersion: apps/v1 | |
kind: StatefulSet | |
metadata: | |
name: es-master | |
namespace: logging | |
spec: | |
serviceName: "es-svc" | |
replicas: 3 # es-pod 运行的实例 | |
selector: # 需要管理的 ES-Pod 标签 | |
matchLabels: | |
app: es | |
role: master | |
template: | |
metadata: | |
labels: | |
app: es | |
role: master | |
spec: # 定义 pod 规范 | |
imagePullSecrets: # 镜像拉取使用的认证信息 | |
- name: harbor-admin | |
affinity: # 设定 pod 反亲和 | |
podAntiAffinity: | |
requiredDuringSchedulingIgnoredDuringExecution: | |
- labelSelector: | |
matchExpressions: | |
- key: app | |
operator: In | |
values: ["es"] | |
- key: role | |
operator: In | |
values: ["master"] | |
topologyKey: "kubernetes.io/hostname" # 每个节点就是一个位置 | |
initContainers: # 初始化容器设定 | |
- name: fix-permissions | |
image: busybox | |
command: ["sh","-c","chown -R 1000:1000 /usr/share/elasticsearch/data ; sysctl -w vm.max_map_count=262144; ulimit -n 65536"] | |
securityContext: | |
privileged: true | |
volumeMounts: | |
- name: data | |
mountPath: /usr/share/elasticsearch/data | |
containers: # ES 主容器 | |
- name: es | |
image: registry.cn-hangzhou.aliyuncs.com/kubernetes_public/elasticsearch:7.17.6 | |
resources: | |
limits: | |
cpu: 1000m | |
memory: 4096Mi | |
requests: | |
cpu: 300m | |
memory: 1024Mi | |
ports: | |
- name: cluster | |
containerPort: 9200 | |
- name: transport | |
containerPort: 9300 | |
volumeMounts: | |
- name: data | |
mountPath: /usr/share/elasticsearch/data | |
- name: tz-config | |
mountPath: /usr/share/zoneinfo/Asia/Shanghai | |
- name: tz-config | |
mountPath: /etc/localtime | |
- name: timezone | |
mountPath: /etc/timezone | |
env: | |
- name: ES_JAVA_OPTS | |
value: "-Xms1g -Xmx1g" | |
- name: cluster.name | |
value: es-cluster | |
- name: node.name | |
valueFrom: | |
fieldRef: | |
fieldPath: metadata.name | |
- name: node.master | |
value: "true" | |
- name: node.data | |
value: "false" | |
- name: discovery.seed_hosts | |
value: "es-master-0.es-svc,es-master-1.es-svc,es-master-2.es-svc" | |
- name: cluster.initial_master_nodes | |
value: "es-master-0,es-master-1,es-master-2" | |
volumes: | |
- name: tz-config | |
hostPath: | |
path: /usr/share/zoneinfo/Asia/Shanghai | |
type: "" | |
- name: timezone | |
hostPath: | |
path: /etc/timezone | |
type: "" | |
volumeClaimTemplates: # 动态 pvc | |
- metadata: | |
name: data | |
spec: | |
accessModes: ["ReadWriteOnce"] | |
storageClassName: "nfs-storage" | |
resources: | |
requests: | |
storage: 5Gi |
# 5.4 交付 ES-Data 节点
ES 无法使用 root 直接启动,需要授权数据目录 UID=1000,同时还需要持久化 /usr/share/elasticsearch/data
ES 所有节点都需要设定 vm.max_map_count 内核参数以及 ulimit;
ES 启动是通过 ENV 环境变量传参来完成的
集群名称、节点名称、角色类型
discovery.seed_hosts 集群地址列表
# cat 03-es-data.yaml | |
apiVersion: apps/v1 | |
kind: StatefulSet | |
metadata: | |
name: es-data | |
namespace: logging | |
spec: | |
serviceName: "es-svc" | |
replicas: 2 # es-pod 运行的实例 | |
selector: # 需要管理的 ES-Pod 标签 | |
matchLabels: | |
app: es | |
role: data | |
template: | |
metadata: | |
labels: | |
app: es | |
role: data | |
spec: # 定义 pod 规范 | |
imagePullSecrets: # 镜像拉取使用的认证信息 | |
- name: harbor-admin | |
affinity: # 设定 pod 反亲和 | |
podAntiAffinity: | |
requiredDuringSchedulingIgnoredDuringExecution: | |
- labelSelector: | |
matchExpressions: | |
- key: app | |
operator: In | |
values: ["es"] | |
- key: role | |
operator: In | |
values: ["data"] | |
topologyKey: "kubernetes.io/hostname" # 每个节点就是一个位置 | |
initContainers: # 初始化容器设定 | |
- name: fix-permissions | |
image: busybox | |
command: ["sh","-c","chown -R 1000:1000 /usr/share/elasticsearch/data ; sysctl -w vm.max_map_count=262144; ulimit -n 65536"] | |
securityContext: | |
privileged: true | |
volumeMounts: | |
- name: data | |
mountPath: /usr/share/elasticsearch/data | |
containers: # ES 主容器 | |
- name: es | |
image: registry.cn-hangzhou.aliyuncs.com/kubernetes_public/elasticsearch:7.17.6 | |
resources: | |
limits: | |
cpu: 1000m | |
memory: 4096Mi | |
requests: | |
cpu: 300m | |
memory: 1024Mi | |
ports: | |
- name: cluster | |
containerPort: 9200 | |
- name: transport | |
containerPort: 9300 | |
volumeMounts: | |
- name: data | |
mountPath: /usr/share/elasticsearch/data | |
- name: tz-config | |
mountPath: /usr/share/zoneinfo/Asia/Shanghai | |
- name: tz-config | |
mountPath: /etc/localtime | |
- name: timezone | |
mountPath: /etc/timezone | |
env: | |
- name: ES_JAVA_OPTS | |
value: "-Xms1g -Xmx1g" | |
- name: cluster.name | |
value: es-cluster | |
- name: node.name | |
valueFrom: | |
fieldRef: | |
fieldPath: metadata.name | |
- name: node.master | |
value: "false" | |
- name: node.data | |
value: "true" | |
- name: discovery.seed_hosts | |
value: "es-master-0.es-svc,es-master-1.es-svc,es-master-2.es-svc" | |
volumes: | |
- name: tz-config | |
hostPath: | |
path: /usr/share/zoneinfo/Asia/Shanghai | |
type: "" | |
- name: timezone | |
hostPath: | |
path: /etc/timezone | |
type: "" | |
volumeClaimTemplates: # 动态 pvc | |
- metadata: | |
name: data | |
spec: | |
accessModes: ["ReadWriteOnce"] | |
storageClassName: "nfs-storage" | |
resources: | |
requests: | |
storage: 5Gi |
# 5.5 更新资源清单
[root@k8s-master01 04-elasticsearch]# kubectl apply -f 01-es-svc.yaml | |
[root@k8s-master01 04-elasticsearch]# kubectl apply -f 02-es-master.yaml | |
[root@k8s-master01 04-elasticsearch]# kubectl apply -f 03-es-data.yaml |
# 5.6 验证 ES 集群
#1. 解析 headlessService 获取对应 ES 集群任一节点的 IP 地址 | |
# dig @10.96.0.10 es-svc.logging.svc.cluster.local +short | |
172.16.58.229 | |
172.16.122.191 | |
172.16.195.21 | |
172.16.122.129 | |
172.16.32.164 | |
#2. 通过 curl 访问 ES,检查 ES 集群是否正常(如果仅交付 Master,没有 data 节点,集群状态可能会 Red,因为没有数据节点进行数据存储;) | |
# curl -XGET "http://172.16.122.129:9200/_cluster/health?pretty" | |
{ | |
"cluster_name" : "es-cluster", | |
"status" : "green", | |
"timed_out" : false, | |
"number_of_nodes" : 5, | |
"number_of_data_nodes" : 2, | |
"active_primary_shards" : 3, | |
"active_shards" : 6, | |
"relocating_shards" : 0, | |
"initializing_shards" : 0, | |
"unassigned_shards" : 0, | |
"delayed_unassigned_shards" : 0, | |
"number_of_pending_tasks" : 0, | |
"number_of_in_flight_fetch" : 0, | |
"task_max_waiting_in_queue_millis" : 0, | |
"active_shards_percent_as_number" : 100.0 | |
} | |
#3. 查看 ES 各个节点详情 | |
# curl -XGET "http://172.16.122.129:9200/_cat/nodes" | |
172.16.122.129 16 33 20 0.38 0.56 0.38 ilmr - es-master-2 | |
172.16.58.229 66 33 22 0.64 0.66 0.44 ilmr * es-master-1 | |
172.16.122.191 52 34 15 0.38 0.56 0.38 cdfhilrstw - es-data-0 | |
172.16.195.21 38 35 19 0.38 0.53 0.36 cdfhilrstw - es-data-1 | |
172.16.32.164 31 33 12 0.28 0.50 0.59 ilmr - es-master-0 |
# 六、交付 Kibana 可视化
# 6.1 下载 kibana 镜像
# docker pull kibana:7.17.6 | |
# docker tag kibana:7.17.6 registry.cn-hangzhou.aliyuncs.com/kubernetes_public/kibana:7.17.6 | |
# docker push registry.cn-hangzhou.aliyuncs.com/kubernetes_public/kibana:7.17.6 |
# 6.2 kibana-deploy
- Kibana 需要连接 ES 集群,通过 ELASTICSEARCH_HOSTS 变量来传递 ES 集群地址
- kibana 通过 I18N_LOCALE 来传递语言环境
- Kibana 通过 SERVER_PUBLICBASEURL 来传递服务访问的公开地址
# cat 01-kibana-deploy.yaml | |
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
name: kibana | |
namespace: logging | |
spec: | |
replicas: 1 | |
selector: | |
matchLabels: | |
app: kibana | |
template: | |
metadata: | |
labels: | |
app: kibana | |
spec: | |
imagePullSecrets: | |
- name: harbor-admin | |
containers: | |
- name: kibana | |
image: registry.cn-hangzhou.aliyuncs.com/kubernetes_public/kibana:7.17.6 | |
resources: | |
limits: | |
cpu: 1000m | |
ports: | |
- containerPort: 5601 | |
env: | |
- name: ELASTICSEARCH_HOSTS | |
value: '["http://es-data-0.es-svc:9200","http://es-data-1.es-svc:9200"]' | |
- name: I18N_LOCALE | |
value: "zh-CN" | |
- name: SERVER_PUBLICBASEURL | |
value: "http://kibana.hmallleasing.com" #kibana 访问 UI | |
volumeMounts: | |
- name: tz-config | |
mountPath: /usr/share/zoneinfo/Asia/Shanghai | |
- name: tz-config | |
mountPath: /etc/localtime | |
- name: timezone | |
mountPath: /etc/timezone | |
volumes: | |
- name: tz-config | |
hostPath: | |
path: /usr/share/zoneinfo/Asia/Shanghai | |
type: "" | |
- name: timezone | |
hostPath: | |
path: /etc/timezone | |
type: "" |
# 6.3 kibana-svc
# cat 02-kibana-svc.yaml | |
apiVersion: v1 | |
kind: Service | |
metadata: | |
name: kibana-svc | |
namespace: logging | |
spec: | |
selector: | |
app: kibana | |
ports: | |
- name: web | |
port: 5601 | |
targetPort: 5601 |
# 6.4 kibana-ingress
# cat 03-kibana-ingress.yaml | |
apiVersion: networking.k8s.io/v1 | |
kind: Ingress | |
metadata: | |
name: kibana-ingress | |
namespace: logging | |
spec: | |
ingressClassName: "nginx" | |
rules: | |
- host: "kibana.hmallleasing.com" | |
http: | |
paths: | |
- path: / | |
pathType: Prefix | |
backend: | |
service: | |
name: kibana-svc | |
port: | |
number: 5601 |
# 6.5 更新资源清单
[root@k8s-master01 05-kibana]# kubectl apply -f 01-kibana-deploy.yaml | |
[root@k8s-master01 05-kibana]# kubectl apply -f 02-kibana-svc.yaml | |
[root@k8s-master01 05-kibana]# kubectl apply -f 03-kibana-ingress.yaml | |
[root@k8s-master01 05-kibana]# kubectl get pods -n logging | |
NAME READY STATUS RESTARTS AGE | |
efak-5cdc74bf59-nrhb4 1/1 Running 0 5h33m | |
es-data-0 1/1 Running 0 16m | |
es-data-1 1/1 Running 0 15m | |
es-master-0 1/1 Running 0 17m | |
es-master-1 1/1 Running 0 15m | |
es-master-2 1/1 Running 0 12m | |
kafka-0 1/1 Running 0 5h39m | |
kafka-1 1/1 Running 0 5h39m | |
kafka-2 1/1 Running 0 5h38m | |
kibana-5ccc46864b-ndzx9 1/1 Running 0 118s | |
zookeeper-0 1/1 Running 0 5h42m | |
zookeeper-1 1/1 Running 0 5h42m | |
zookeeper-2 1/1 Running 0 5h41m |
# 6.6 访问 kibana
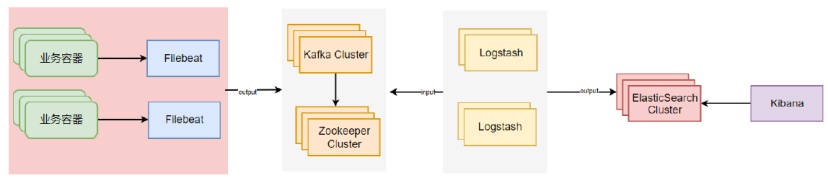
# 七、DaemonSet 运行日志 Agent 实践
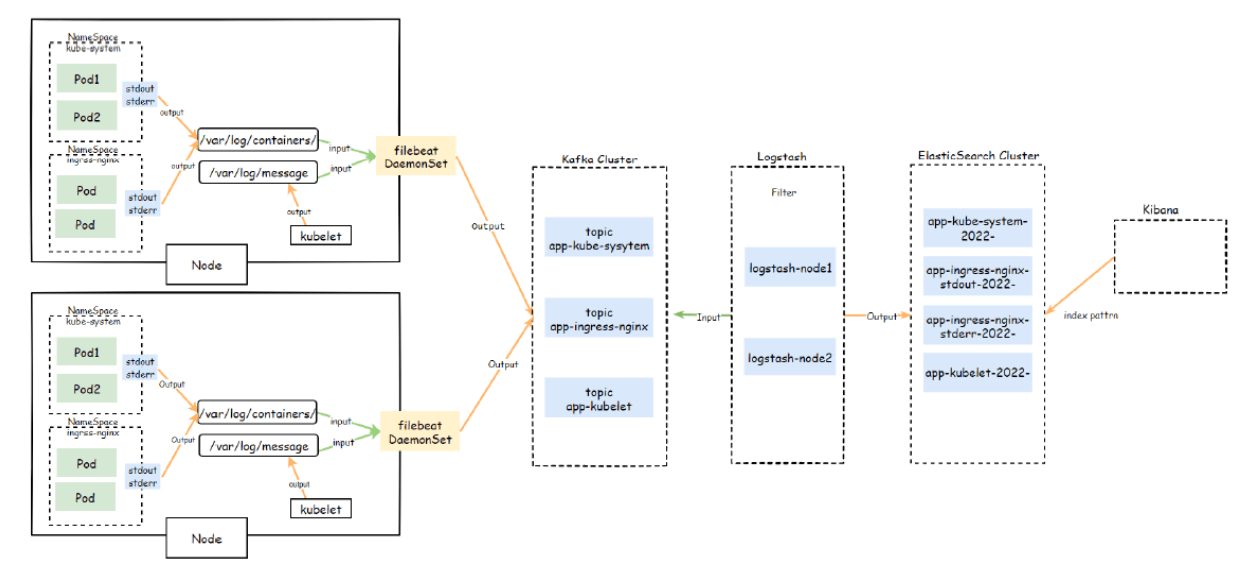
# 7.1 部署架构说明
对于那些将日志输出到,stdout 与 stderr 的 Pod,可以直接使用 DaemonSet 控制器在每个 Node 节点上运行一个 filebeat、logstash、fluentd 容器进行统一的收集,而后写入到日志存储系统
# 7.2 创建 ServiceAccount
kubectl create serviceaccount filebeat -n logging |
# 7.3 创建 ClusterRole
kubectl create clusterrole filebeat --verb=get,list,watch --resource=namespace,pods,nodes |
# 7.4 创建 ClusterRolebinding
kubectl create clusterrolebinding filebeat --serviceaccount=logging:filebeat --clusterrole=filebeat |
# 7.5 交付 Filebeat
# 7.5.1 下载 filebeat 镜像
# docker pull docker.elastic.co/beats/filebeat:7.17.6 | |
# docker tag docker.elastic.co/beats/filebeat:7.17.6 registry.cn-hangzhou.aliyuncs.com/kubernetes_public/filebeat:7.17.6 | |
# docker push registry.cn-hangzhou.aliyuncs.com/kubernetes_public/filebeat:7.17.6 |
# 7.5.2 交付 filebeat
- 从 ConfigMap 中挂载 filebeat.yaml 配置文件;
- 挂载 /var/log、/var/lib/docker/containers 日志相关目录;
- 使用 hostPath 方式挂载 /usr/share/filebeat/data 数据目录,该目录下有一个 registry 文件,里面记录了 filebeat 采集日志位置的相关内容,比如文件 offset、source、timestamp 等,如果 Pod 发生异常后 K8S 自动将 Pod 进行重启,不挂载的情况下 registry 会被重置,将导致日志文件又从 offset=0 开始采集,会造成重复收集日志。
[root@k8s-master01 07-filebeat-daemoset]# cat 02-filebeat-ds.yaml | |
apiVersion: apps/v1 | |
kind: DaemonSet | |
metadata: | |
name: filebeat | |
namespace: logging | |
spec: | |
selector: | |
matchLabels: | |
app: filebeat | |
template: | |
metadata: | |
labels: | |
app: filebeat | |
spec: | |
serviceAccountName: "filebeat" | |
tolerations: | |
- key: node-role.kubernetes.io/master | |
operator: "Exists" | |
effect: "NoSchedule" | |
imagePullSecrets: | |
- name: harbor-admin | |
containers: | |
- name: filebeat | |
image: registry.cn-hangzhou.aliyuncs.com/kubernetes_public/filebeat:7.17.6 | |
args: [ | |
"-c","/etc/filebeat.yml", | |
"-e" | |
] | |
securityContext: | |
runAsUser: 0 | |
resources: | |
limits: | |
memory: 300Mi | |
volumeMounts: | |
- name: config # 从 ConfigMap 中读取 | |
mountPath: /etc/filebeat.yml | |
subPath: filebeat.yml | |
- name: varlog | |
mountPath: /var/log | |
readOnly: true | |
- name: varlibdockercontainers | |
mountPath: /var/lib/docker/containers | |
readOnly: true | |
- name: data | |
mountPath: /usr/share/filebeat/data | |
- name: tz-config | |
mountPath: /usr/share/zoneinfo/Asia/Shanghai | |
- name: tz-config | |
mountPath: /etc/localtime | |
- name: timezone | |
mountPath: /etc/timezone | |
volumes: | |
- name: config | |
configMap: | |
name: filebeat-config | |
- name: varlog | |
hostPath: | |
path: /var/log | |
- name: varlibdockercontainers | |
hostPath: | |
path: /var/lib/docker/containers | |
- name: data | |
hostPath: | |
path: /var/lib/filebeat-data | |
type: DirectoryOrCreate | |
- name: tz-config | |
hostPath: | |
path: /usr/share/zoneinfo/Asia/Shanghai | |
type: "" | |
- name: timezone | |
hostPath: | |
path: /etc/timezone | |
type: "" |
# 7.5.3 Filebeat 配置文件
# cat 01-filebeat-configmap.yaml | |
apiVersion: v1 | |
kind: ConfigMap | |
metadata: | |
name: filebeat-config | |
namespace: logging | |
data: | |
filebeat.yml: |- | |
# ============================== Filebeat inputs ============================== | |
logging.level: warning | |
filebeat.inputs: | |
- type: log | |
enabled: true | |
encoding: utf-8 | |
paths: /var/log/messages | |
include_lines: ['kubelet'] # 获取与 kubelet 相关的日志 | |
fields: # 添加 filebeat 字段 | |
namespace: kubelet | |
fields_under_root: true | |
# ============================== Filebeat autodiscover ============================ | |
filebeat.autodiscover: | |
providers: | |
- type: kubernetes | |
templates: | |
- condition: # 匹配 kube-system 名称空间下所有日志 | |
equals: | |
kubernetes.namespace: kube-system | |
config: | |
- type: container | |
stream: all # 收集 stdout、stderr 类型日志,all 是所有 | |
encoding: utf-8 | |
paths: /var/log/containers/*-${data.kubernetes.container.id}.log | |
exclude_lines: ['info'] # 排除 info 相关的日志 | |
- condition: # 收集 ingress-nginx 命名空间下 stdout 日志 | |
equals: | |
kubernetes.namespace: ingress-nginx | |
config: | |
- type: container | |
stream: stdout | |
encoding: utf-8 | |
paths: /var/log/containers/*-${data.kubernetes.container.id}.log | |
json.keys_under_root: true # 默认将 json 解析存储至 messages,true 则不存储至 message | |
json.overwrite_keys: true # 覆盖默认 message 字段,使用自定义 json 格式的 key | |
#exclude_lines: ['kibana'] # 与 kibana 相关的则排除 | |
- condition: # 收集 ingress-nginx 命名空间下 stderr 日志 | |
equals: | |
kubernetes.namespace: ingress-nginx | |
config: | |
- type: container | |
stream: stderr | |
encoding: utf-8 | |
paths: | |
- /var/log/containers/*-${data.kubernetes.container.id}.log | |
# ============================== Filebeat Processors =========================== | |
processors: | |
- rename: # 重写 kubernetes 源数据信息 | |
fields: | |
- from: "kubernetes.namespace" | |
to: "namespace" | |
- from: "kubernetes.pod.name" | |
to: "podname" | |
- from: "kubernetes.pod.ip" | |
to: "podip" | |
- drop_fields: # 删除无用的字段 | |
fields: ["host","agent","ecs","input","container","kubernetes"] | |
# ================================== Kafka Output =================================== | |
output.kafka: | |
hosts: ["kafka-0.kafka-svc:9092","kafka-1.kafka-svc:9092","kafka-2.kafka-svc:9092"] | |
topic: "app-%{[namespace]}" # %{[namespace]} 会自动将其转换为 namespace 对应的值 | |
required_acks: 1 # 保证消息可靠,0 不保证,1 等待写入主分区(默认)-1 等待写入副本分区 | |
compression: gzip # 压缩 | |
max_message_bytes: 1000000 # 每条消息最大的长度,多余的被删除 |
# 7.5.4 收集 ingress-nginx 名称空间
修改 Ingress 日志输出格式
# kubectl edit configmap -n ingress-nginx ingress-nginx-controller | |
apiVersion: v1 | |
data: | |
... | |
log-format-upstream: '{"timestamp":"$time_iso8601","domain":"$server_name","hostname":"$hostname","remote_user":"$remote_user","clientip":"$remote_addr","proxy_protocol_addr":"$proxy_protocol_addr","@source":"$server_addr","host":"$http_host","request":"$request","args":"$args","upstreamaddr":"$upstream_addr","status":"$status","upstream_status":"$upstream_status","bytes":"$body_bytes_sent","responsetime":"$request_time","upstreamtime":"$upstream_response_time","proxy_upstream_name":"$proxy_upstream_name","x_forwarded":"$http_x_forwarded_for","upstream_response_length":"$upstream_response_length","referer":"$http_referer","user_agent":"$http_user_agent","request_length":"$request_length","request_method":"$request_method","scheme":"$scheme","k8s_ingress_name":"$ingress_name","k8s_service_name":"$service_name","k8s_service_port":"$service_port"}' |
# 7.5.5 更新资源清单
kubectl apply -f 01-filebeat-configmap.yaml | |
kubectl apply -f 02-filebeat-ds.yaml |
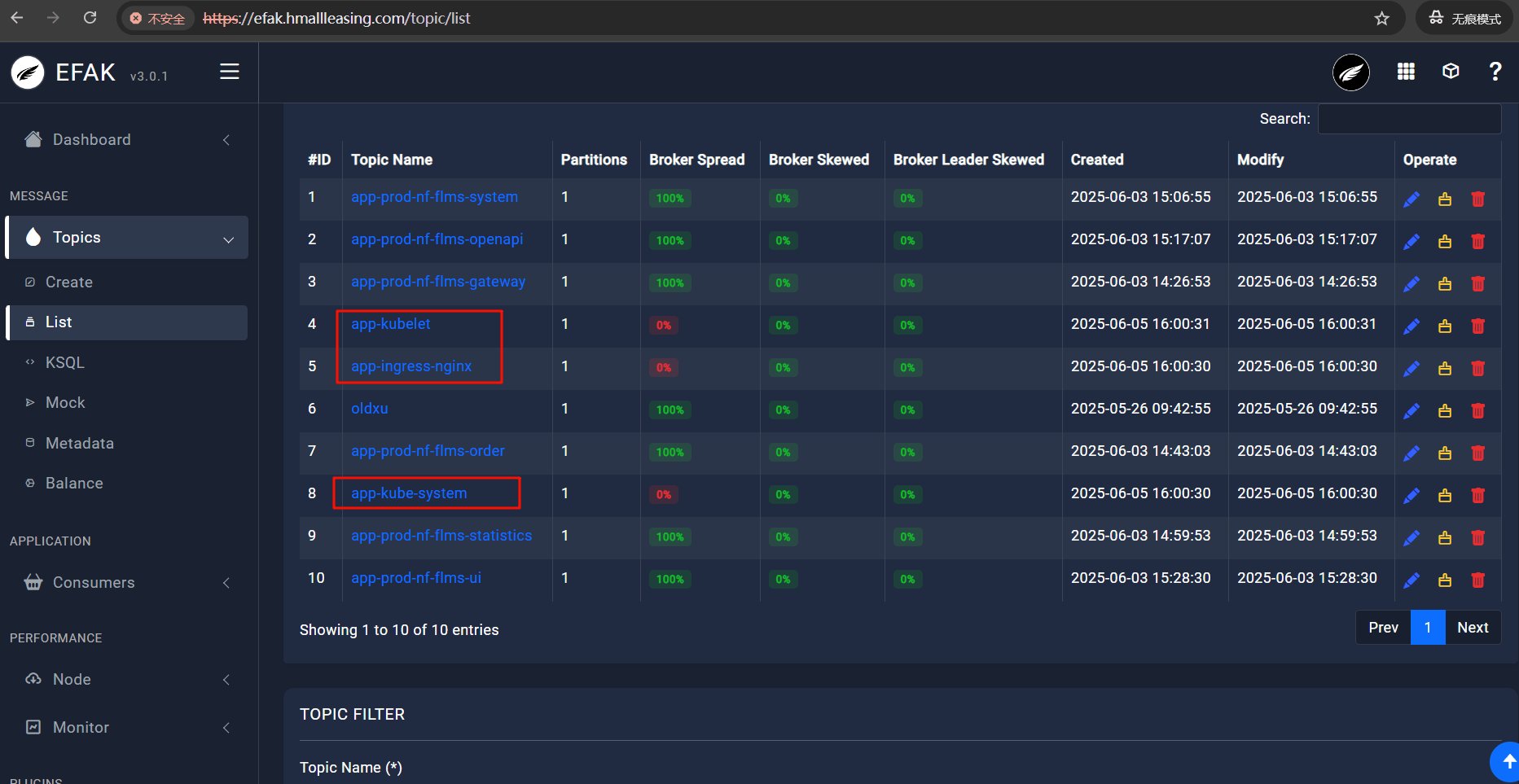
# 7.5.6 检查 kafka 对应 Topic
# 八、 交付 Logstash
# 8.1 下载 Logstash 镜像
# docker pull docker.elastic.co/logstash/logstash-oss:7.17.6 | |
# docker tag docker.elastic.co/logstash/logstash-oss:7.17.6 registry.cn-hangzhou.aliyuncs.com/kubernetes_public/logstash-oss:7.17.6 | |
# docker push registry.cn-hangzhou.aliyuncs.com/kubernetes_public/logstash-oss:7.17.6 |
# 8.2 如何交付 Logstash
- Logstash 需要设定环境变量来调整主配置文件参数,比如:worker 运行数量,以及批量处理的最大条目是多少;
- Logstash 需要调整 JVM 堆内存使用的范围,没办法传参调整,但可以通过 postStart 来修改其文件对应的 jvm 参数;
- Logstash 需要配置文件,读取 Kafka 数据,而后通过 filter 处理,最后输出至 ES
# /usr/share/logstash/config/logstash.yml | |
# 可通过变量传参修改 | |
pipeline.workers: 2 | |
pipeline.batch.size: 1000 | |
# /usr/share/logstash/config/jvm.options-Xms512m-Xmx512m | |
# /usr/share/logstash/config/logstash.conf | |
input { | |
kafka | |
} | |
filter { | |
} |
# 8.3 准备 logstash 配置
input 段含义
- 所有数据都从 kafka 集群中获取;
- 获取 kafka 集群中 topic,主要有 app-kube-system、app-ingress-nginx、app-kubelet
filter 段含义
- 判断 namespace 等于 kubelet,则为其添加一个索引字段名称;
- 判断 namespace 等于 kube-system,则为其添加一个索引字段名称;
- 判断 namespace 等于 ingress-nginx,并且 stream 等于 stderr,则为其添加一个索引字段名称;
- 判断 namespace 等于 ingress-nginx,并且 stream 等于 stdout,则使用 geoip 获取地址来源,使用 useragent 模块分析来访客户端设备,使用 date 处理时间,使用 mutate 转换对应字段格式,最后添加一个索引字段名称;
# cat logstash-node.conf | |
input { | |
kafka { | |
bootstrap_servers => "kafka-0.kafka-svc:9092,kafka-1.kafka-svc:9092,kafka-2.kafka-svc:9092" | |
group_id => "logstash-node" # 消费者组名称 | |
consumer_threads => "3" # 理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡 | |
topics => ["app-kube-system","app-ingress-nginx","app-kubelet"] | |
codec => json | |
} | |
} | |
filter { | |
########################################################################## | |
if "kubelet" in [namespace] { | |
mutate { | |
add_field => { "target_index" => "app-%{[namespace]}-%{+YYYY.MM.dd}" } | |
} | |
} | |
########################################################################## | |
if "kube-system" in [namespace] { | |
mutate { | |
add_field => { "target_index" => "app-%{[namespace]}-%{+YYYY.MM.dd}" } | |
} | |
} | |
########################################################################## | |
if [namespace] == "ingress-nginx" and [stream] == "stdout" { | |
geoip { | |
source => "clientip" | |
} | |
useragent { | |
source => "user_agent" | |
target => "user_agent" | |
} | |
date { | |
# 2022-10-08T13:13:20.000Z | |
match => ["timestamp","ISO8601"] | |
target => "@timestamp" | |
timezone => "Asia/Shanghai" | |
} | |
mutate { | |
convert => { | |
"bytes" => "integer" | |
"responsetime" => "float" | |
"upstreamtime" => "float" | |
} | |
add_field => { "target_index" => "app-%{[namespace]}-%{[stream]}-%{+YYYY.MM.dd}" } | |
} | |
} | |
########################################################################## | |
if [namespace] == "ingress-nginx" and [stream] == "stderr" { | |
mutate { | |
add_field => { "target_index" => "app-%{[namespace]}-%{[stream]}-%{+YYYY.MM.dd}" } | |
} | |
} | |
} | |
output { | |
stdout { | |
codec => rubydebug | |
} | |
elasticsearch { | |
hosts => ["es-data-0.es-svc:9200","es-data-1.es-svc:9200"] | |
index => "%{[target_index]}" | |
template_overwrite => true | |
} | |
} |
# 8.4 创建 ConfigMap
kubectl create configmap logstash-node-conf --from-file=logstash.conf=conf/logstash-node.conf -n logging |
# 8.5 创建 Service
# cat 01-logstash-svc.yaml | |
apiVersion: v1 | |
kind: Service | |
metadata: | |
name: logstash-svc | |
namespace: logging | |
spec: | |
clusterIP: None | |
selector: | |
app: logstash | |
ports: | |
- port: 9600 | |
targetPort: 9600 |
# 8.6 交付 Logstash
[root@k8s-master01 08-logstash]# cat 02-logstash-node-sts.yaml | |
apiVersion: apps/v1 | |
kind: StatefulSet | |
metadata: | |
name: logstash-node | |
namespace: logging | |
spec: | |
serviceName: "logstash-svc" | |
replicas: 1 | |
selector: | |
matchLabels: | |
app: logstash | |
env: node | |
template: | |
metadata: | |
labels: | |
app: logstash | |
env: node | |
spec: | |
imagePullSecrets: | |
- name: harbor-admin | |
containers: | |
- name: logstash | |
image: registry.cn-hangzhou.aliyuncs.com/kubernetes_public/logstash-oss:7.17.6 | |
args: ["-f","config/logstash.conf"] # 启动时指定加载的配置文件 | |
resources: | |
limits: | |
memory: 1024Mi | |
env: | |
- name: PIPELINE_WORKERS | |
value: "2" | |
- name: PIPELINE_BATCH_SIZE | |
value: "10000" | |
lifecycle: | |
postStart: # 设定 JVM | |
exec: | |
command: | |
- "/bin/bash" | |
- "-c" | |
- "sed -i -e '/^-Xms/c-Xms512m' -e '/^-Xmx/c-Xmx512m' /usr/share/logstash/config/jvm.options" | |
volumeMounts: | |
- name: data # 持久化数据目录 | |
mountPath: /usr/share/logstash/data | |
- name: conf | |
mountPath: /usr/share/logstash/config/logstash.conf | |
subPath: logstash.conf | |
- name: tz-config | |
mountPath: /usr/share/zoneinfo/Asia/Shanghai | |
- name: tz-config | |
mountPath: /etc/localtime | |
- name: timezone | |
mountPath: /etc/timezone | |
volumes: | |
- name: conf | |
configMap: | |
name: logstash-node-conf | |
- name: tz-config | |
hostPath: | |
path: /usr/share/zoneinfo/Asia/Shanghai | |
type: "" | |
- name: timezone | |
hostPath: | |
path: /etc/timezone | |
type: "" | |
volumeClaimTemplates: | |
- metadata: | |
name: data | |
spec: | |
accessModes: ["ReadWriteMany"] | |
storageClassName: "nfs-storage" | |
resources: | |
requests: | |
storage: 5Gi |
# 8.7 更新资源清单
kubectl apply -f 01-logstash-svc.yaml | |
kubectl apply -f 02-logstash-node-sts.yaml |
# 8.8 检查 kibana 索引
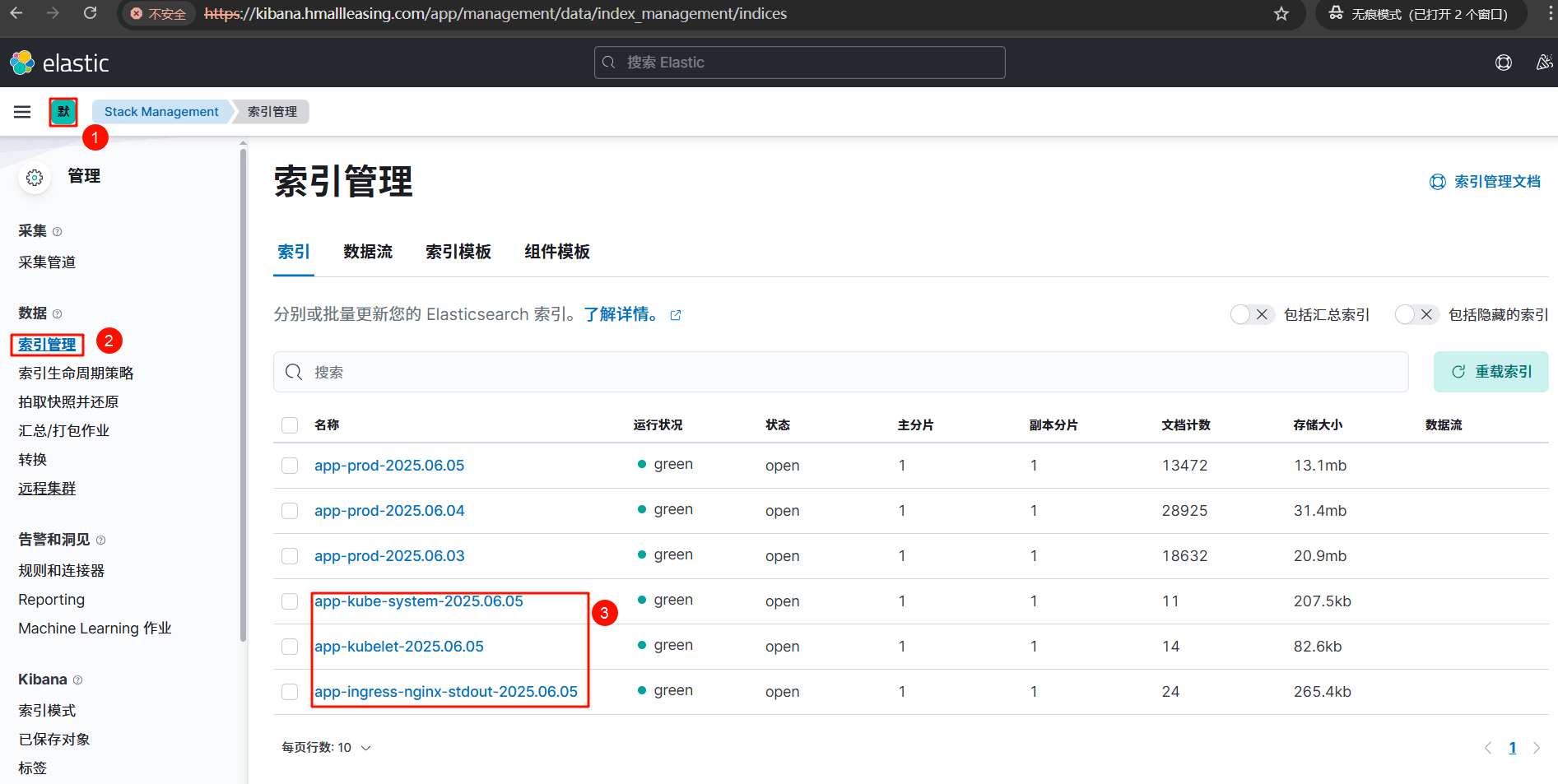
# 九、Kibana 可视化
# 9.1 创建索引
kube-system 索引
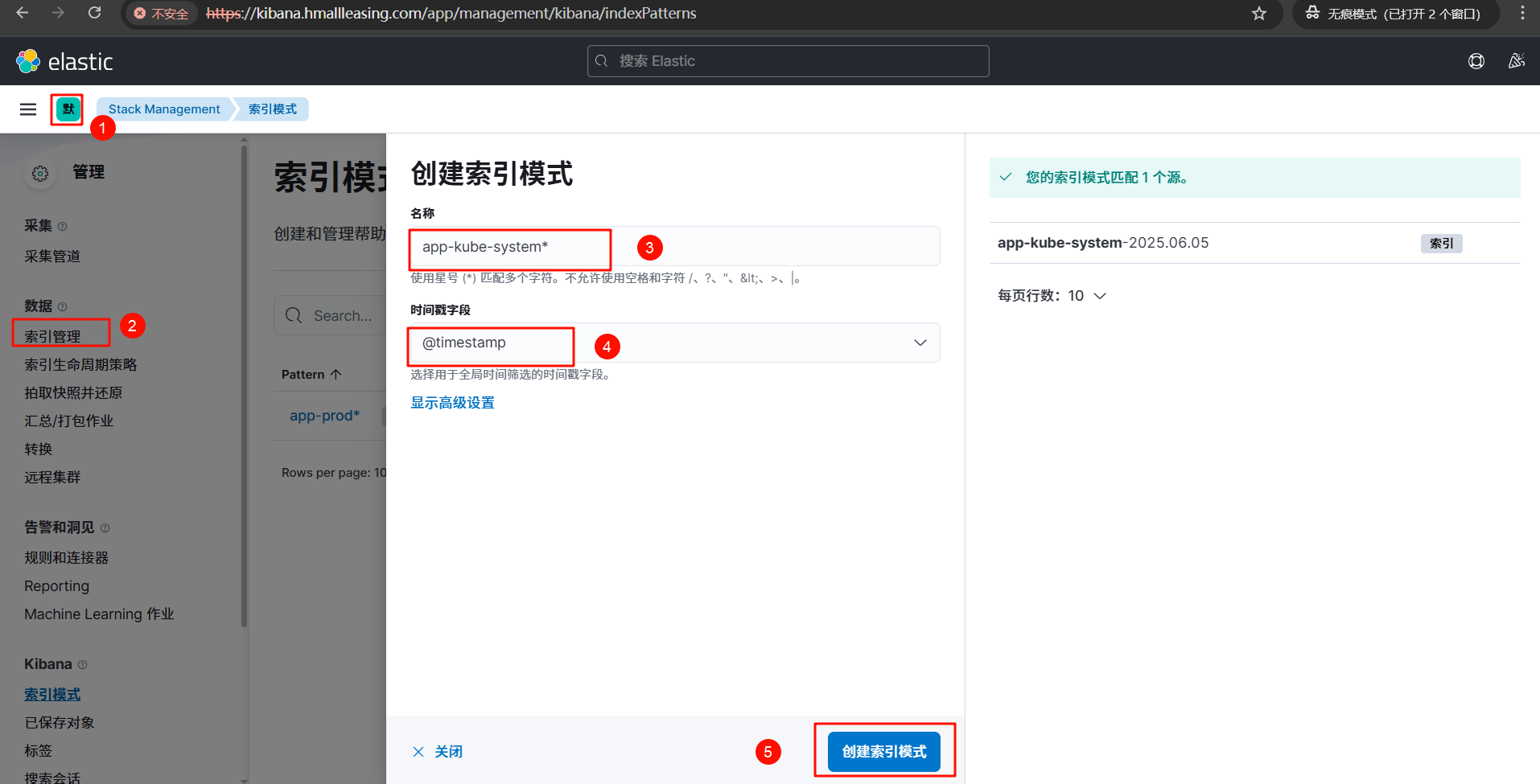
ingress-stdout 索引
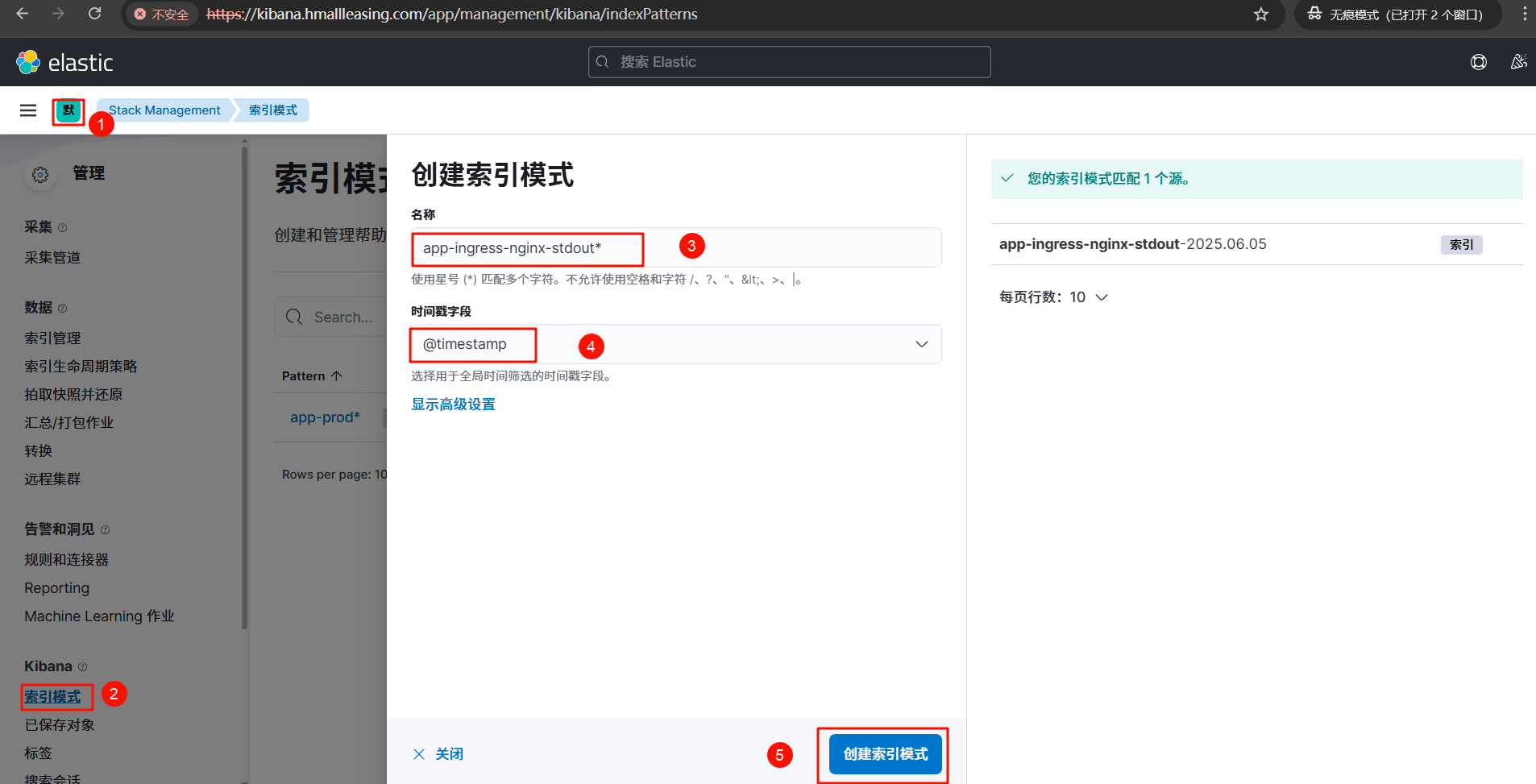
ingress-stderr 索引
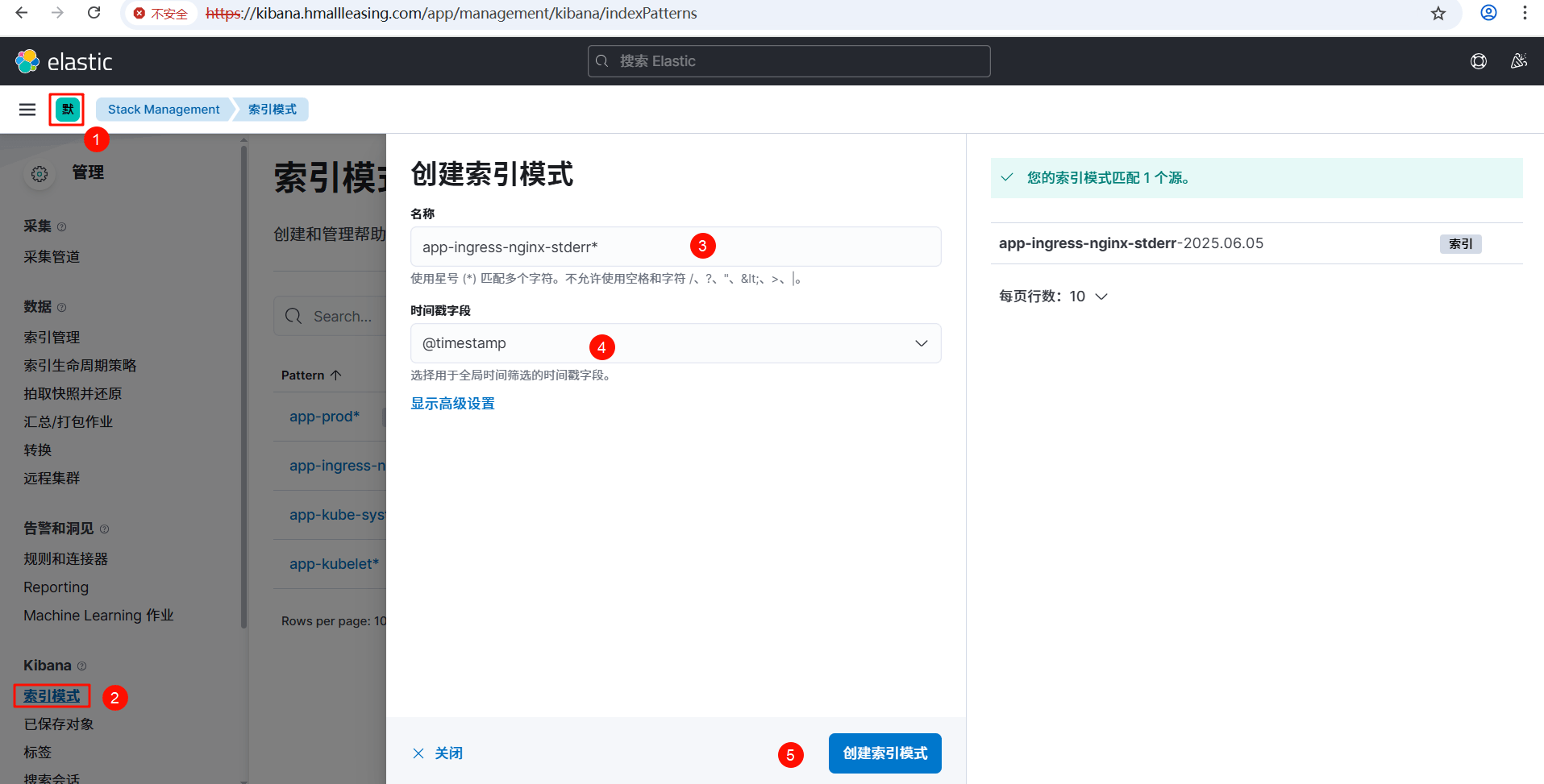
kubelet 索引
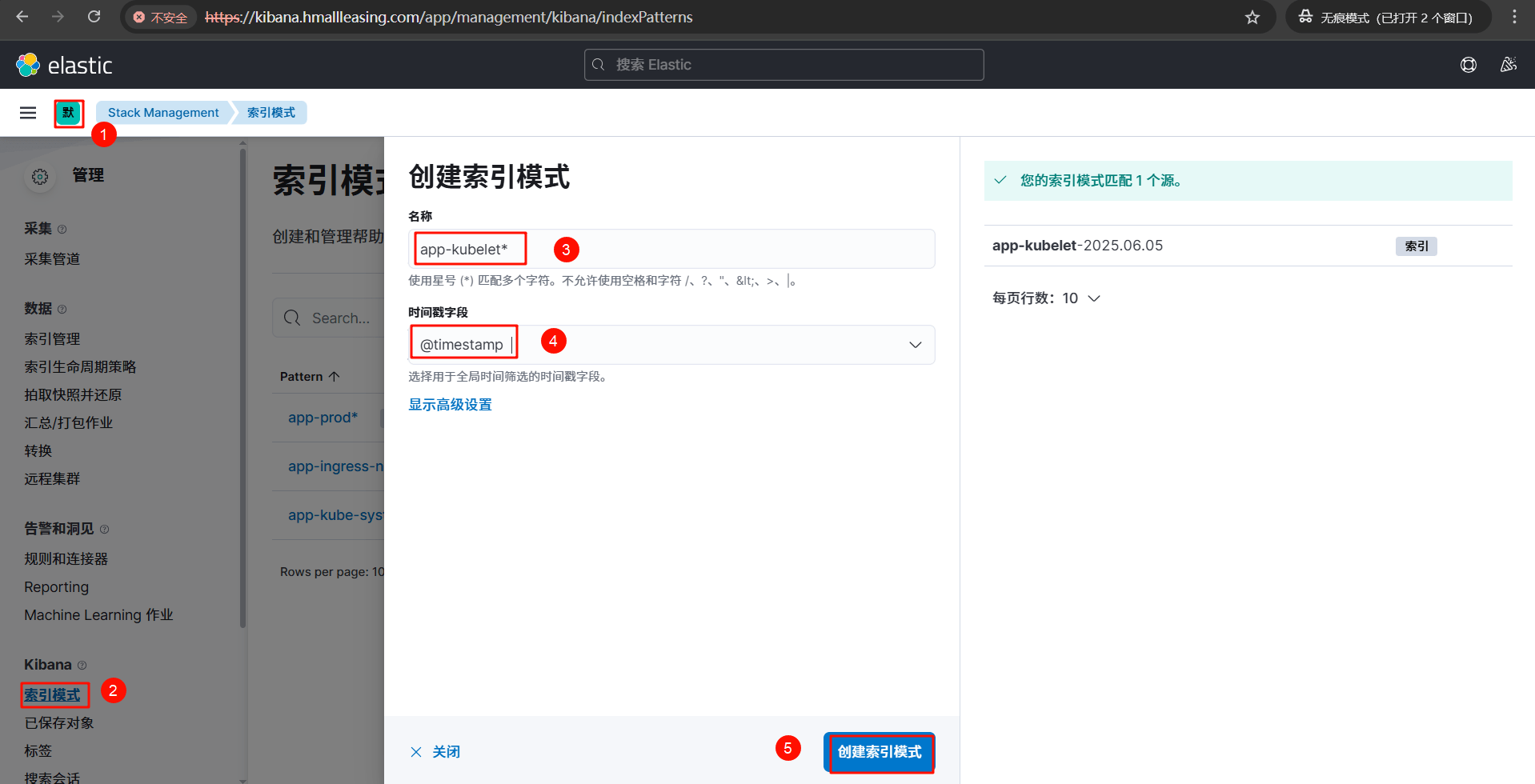
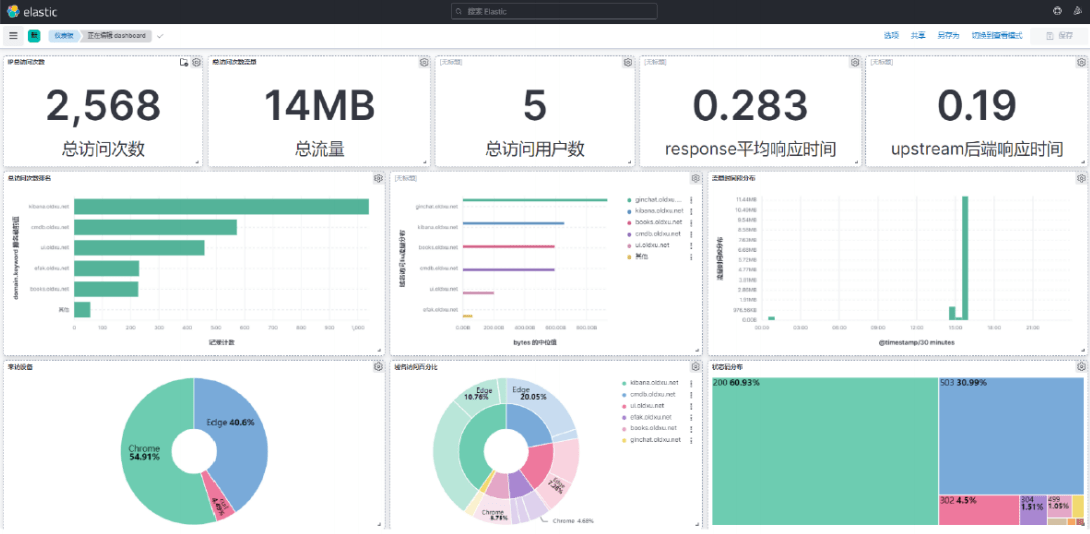
# 9.2 日志展示
app-ingress-nginx-stdout 索引日志
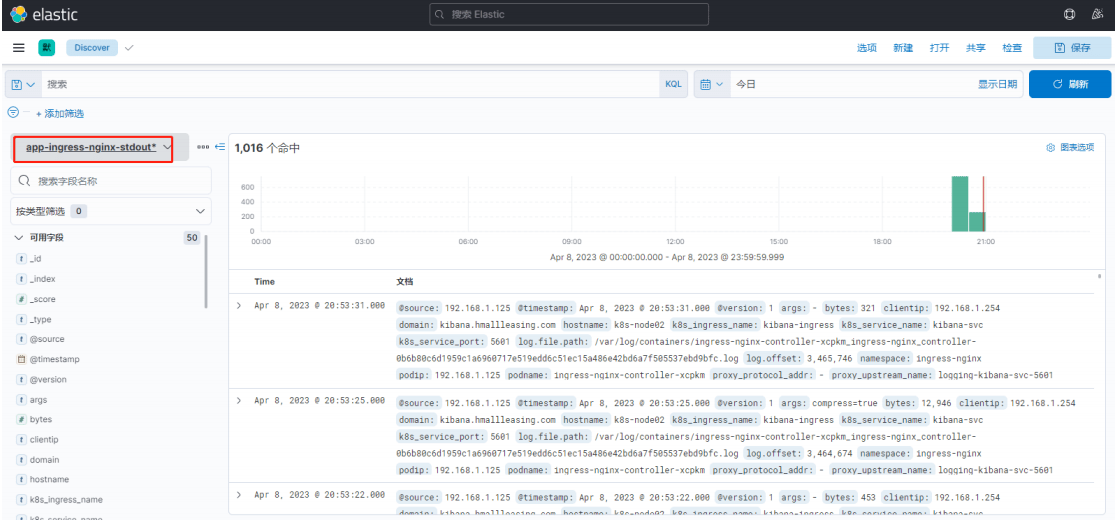
app-ingress-nginx-stderr 索引日志
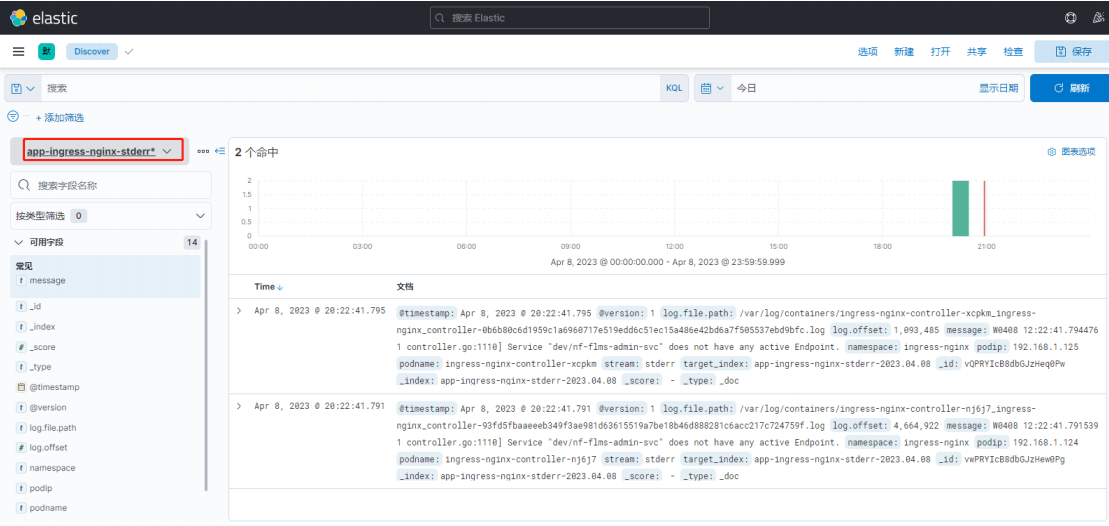
app-kube-system 索引日志
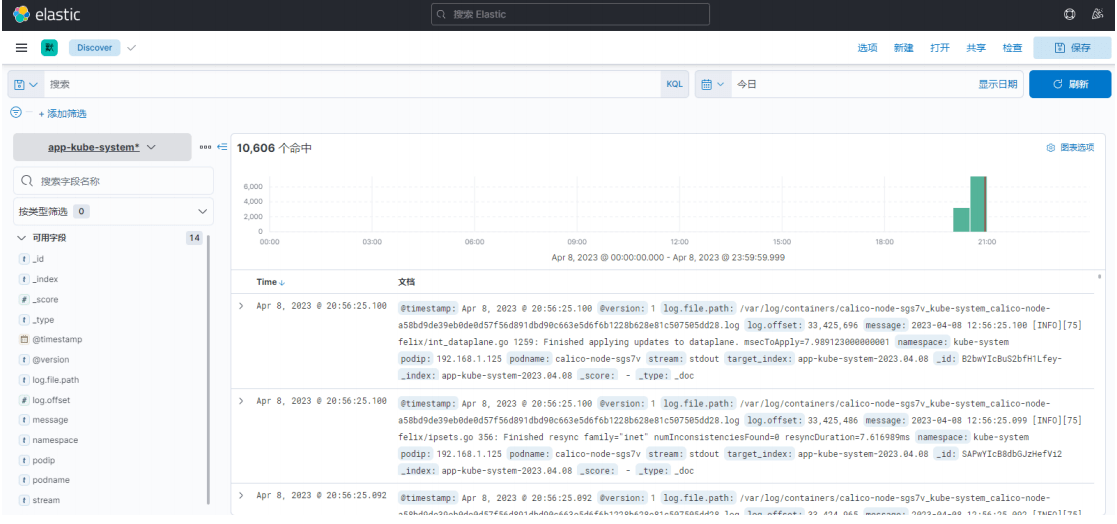
app-kubelet 索引日志
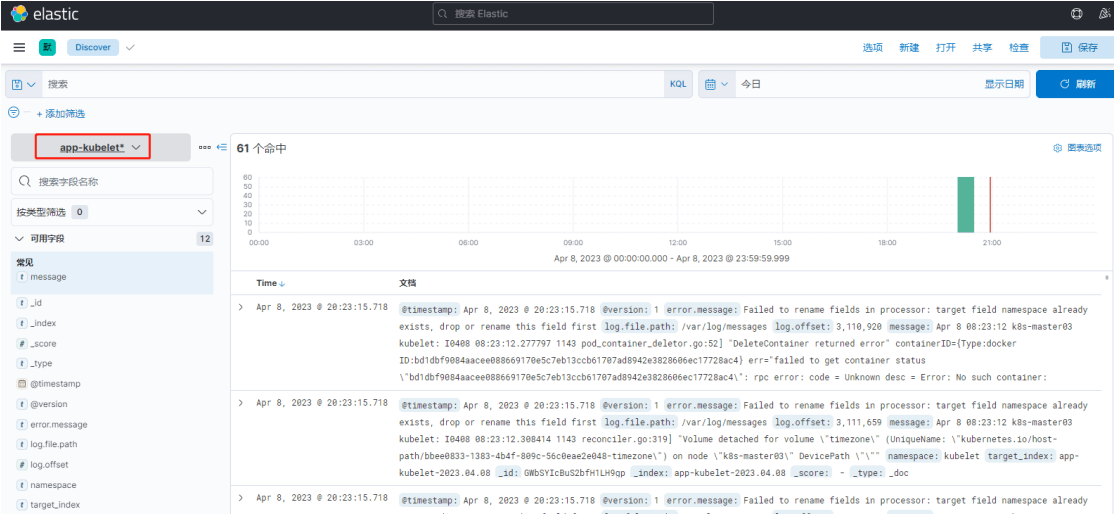
# 9.3 图形展示